71-HTTPS
这篇文章写的不错,转载一下 https://zhuanlan.zhihu.com/p/43789231
为什么需要加密?
因为 http 的内容是明文传输的,明文数据会经过中间代理服务器、路由器、wifi热点、通信服务运营商等多个物理节点,如果信息在传输过程中被劫持,传输的内容就完全暴露了。劫持者还可以篡改传输的信息且不被双方察觉,这就是中间人攻击。所以我们才需要对信息进行加密。最容易理解的就是对称加密 。
什么是对称加密?
简单说就是有一个密钥,它可以加密一段信息,也可以对加密后的信息进行解密,和我们日常生活中用的钥匙作用差不多。
用对称加密可行吗?
如果通信双方都各自持有同一个密钥,且没有别人知道,这两方的通信安全当然是可以被保证的(除非密钥被破解)。
然而最大的问题就是这个密钥怎么让传输的双方知晓,同时不被别人知道。如果由服务器生成一个密钥并传输给浏览器,那在这个传输过程中密钥被别人劫持到手了怎么办?之后他就能用密钥解开双方传输的任何内容了,所以这么做当然不行。
换种思路?试想一下,如果浏览器内部就预存了网站A的密钥,且可以确保除了浏览器和网站A,不会有任何外人知道该密钥,那理论上用对称加密是可以的,这样浏览器只要预存好世界上所有HTTPS网站的密钥就行了!这么做显然不现实。怎么办?所以我们就需要非对称加密 。
什么是非对称加密?
简单说就是有两把密钥,通常一把叫做公钥、一把叫私钥,用公钥加密的内容必须用私钥才能解开,同样,私钥加密的内容只有公钥能解开。
用非对称加密可行吗?
鉴于非对称加密的机制,我们可能会有这种思路:服务器先把公钥以明文方式传输给浏览器,之后浏览器向服务器传数据前都先用这个公钥加密好再传,这条数据的安全似乎可以保障了!
因为只有服务器有相应的私钥能解开公钥加密的数据。
那有人会问 由服务器到浏览器的这条路怎么保障安全?
如果服务器用它的私钥加密数据传给浏览器,那么浏览器用公钥可以解密它,而这个公钥是一开始通过明文传输给浏览器的,若这个公钥被中间人劫持到了,那他也能用该公钥解密服务器传来的信息了。
所以目前似乎只能保证由浏览器向服务器传输数据的安全性(其实仍有漏洞,下文会说),那利用这点你能想到什么解决方案吗?
改良的非对称加密方案,似乎可以?
我们已经理解通过一组公钥私钥,可以保证单个方向传输的安全性,那用两组公钥私钥,是否就能保证双向传输都安全了?请看下面的过程:
- 某网站服务器拥有
公钥A与对应的私钥A’;浏览器拥有公钥B与对应的私钥B’。 - 浏览器把
公钥B明文传输给服务器。 - 服务器把
公钥A明文给传输浏览器。 - 之后浏览器向服务器传输的内容都用
公钥A加密,服务器收到后用私钥A’解密。由于只有服务器拥有私钥A’,所以能保证这条数据的安全。 - 同理,服务器向浏览器传输的内容都用
公钥B加密,浏览器收到后用私钥B’解密。同上也可以保证这条数据的安全。
的确可以!但这里面仍有的漏洞(中间人劫持服务器,下文会讲),HTTPS的加密却没使用这种方案,为什么?
很重要的原因是非对称加密算法非常耗时,而对称加密快很多。那我们能不能运用非对称加密的特性解决前面提到的对称加密的漏洞?
非对称加密+对称加密?
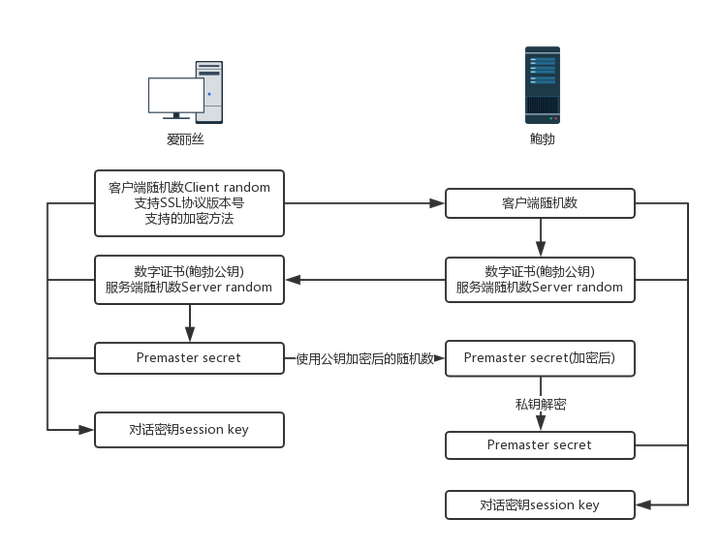
既然非对称加密耗时,那非对称加密+对称加密结合可以吗?而且得尽量减少非对称加密的次数。当然是可以的,且非对称加密、解密各只需用一次即可。请看一下这个过程:
- 某网站拥有用于非对称加密的
公钥A、私钥A’。 - 浏览器向网站服务器请求,服务器把
公钥A明文给传输浏览器。 - 浏览器随机生成一个用于对称加密的
密钥X,用公钥A加密后传给服务器。 - 服务器拿到后用
私钥A’解密得到密钥X。 - 这样双方就都拥有
密钥X了,且别人无法知道它。之后双方所有数据都通过密钥X加密解密即可。
完美!HTTPS基本就是采用了这种方案。完美?还是有漏洞的(中间人劫持服务器)。
中间人攻击
在上述数据传输过程中,中间人在第二步劫持到了数据,此时他的确无法得到浏览器生成的密钥X,因为这个密钥本身被公钥A加密了,只有服务器才有私钥A’解开它,然而中间人却完全不需要拿到私钥A’就能干坏事了。请看:
- 某网站有用于非对称加密的
公钥A、私钥A’。 - 浏览器向网站服务器请求,服务器把
公钥A明文给传输浏览器。 - 中间人劫持到
公钥A,保存下来,把数据包中的公钥A替换成自己伪造的公钥B(它当然也拥有公钥B对应的私钥B’)。 - 浏览器生成一个用于对称加密的
密钥X,用公钥B(浏览器无法得知公钥被替换了)加密后传给服务器。 - 中间人劫持后用
私钥B’解密得到密钥X,再用公钥A加密后传给服务器。 - 服务器拿到后用
私钥A’解密得到密钥X。
这样在双方都不会发现异常的情况下,中间人通过一套“狸猫换太子”的操作,掉包了服务器传来的公钥,进而得到了 密钥X。其根本原因是 浏览器无法确认收到的公钥是不是网站自己的, 因为公钥本身是明文传输的,难道还得对公钥的传输进行加密?这似乎变成鸡生蛋、蛋生鸡的问题了。解法是什么?
如何证明浏览器收到的公钥一定是该网站的公钥?
其实所有证明的源头都是一条或多条不证自明的“公理”(可以回想一下数学上公理),由它推导出一切。比如现实生活中,若想证明某身份证号一定是小明的,可以看他身份证,而身份证是由政府作证的,这里的“公理”就是“政府机构可信”,这也是社会正常运作的前提。
那能不能类似地有个机构充当互联网世界的“公理”呢?让它作为一切证明的源头,给网站颁发一个“身份证”?
它就是CA机构,它是如今互联网世界正常运作的前提,而CA机构颁发的“身份证”就是数字证书。
数字证书
网站在使用 HTTPS 前,需要向 CA机构 申领一份数字证书,数字证书里含有证书持有者信息、公钥信息等。服务器把证书传输给浏览器,浏览器从证书里获取公钥就行了,证书就如身份证,证明“该公钥对应该网站”。
而这里又有一个显而易见的问题,证书本身的传输过程中,如何防止被篡改?即如何证明证书本身的真实性?身份证运用了一些防伪技术,而数字证书怎么防伪呢?解决这个问题我们就接近胜利了!
如何放防止数字证书被篡改?
我们把证书原本的内容生成一份“签名”,比对证书内容和签名是否一致就能判别是否被篡改。这就是数字证书的“防伪技术”,这里的“签名”就叫数字签名:
数字签名
这部分内容建议看下图并结合后面的文字理解,图中左侧是数字签名的制作过程,右侧是验证过程:
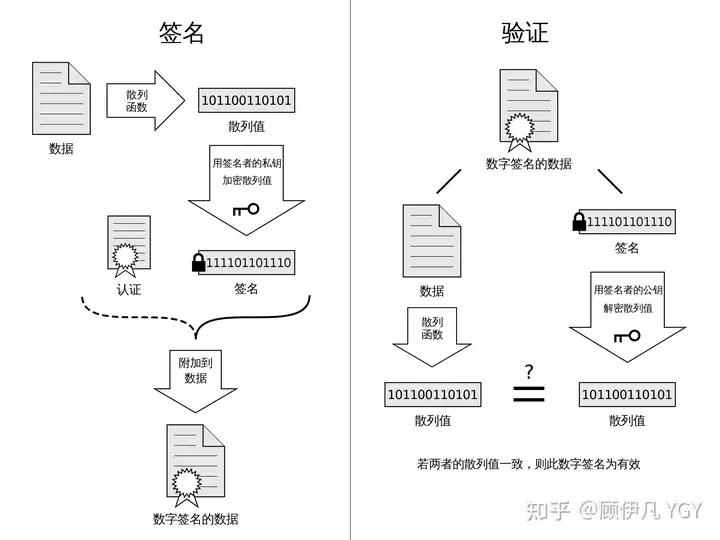
数字签名的制作过程:
- CA 机构拥有非对称加密的私钥和公钥。
- CA 机构对证书明文数据 T 进行 hash。
- 对 hash 后的值用私钥加密,得到数字签名 S。
明文 T 和数字签名 S 共同组成了数字证书,这样一份数字证书就可以颁发给网站了。
那浏览器拿到服务器传来的数字证书后,如何验证它是不是真的?(有没有被篡改、掉包)
浏览器验证过程:
- 拿到证书,得到明文 T、签名 S。
- 用 CA 机构的公钥对 S 解密(由于是浏览器信任的机构,所以浏览器保有它的公钥。详情见下文),得到 S’。
- 用证书里指明的 hash 算法对明文 T 进行 hash 得到 T’。
- 显然通过以上步骤,T’ 应当等于 S’,除非明文或签名被篡改。所以此时比较 S’ 是否等于 T’,等于则表明证书可信。
为何么这样可以保证证书可信呢?我们来仔细想一下。
中间人有可能篡改该证书吗?
假设中间人篡改了证书的原文,由于他没有CA机构的私钥,所以无法得到此时加密后签名,无法相应地篡改签名。浏览器收到该证书后会发现原文和签名解密后的值不一致,则说明证书已被篡改,证书不可信,从而终止向服务器传输信息,防止信息泄露给中间人。
既然不可能篡改,中间人有可能把证书掉包吗?
假设有另一个网站B也拿到了CA机构认证的证书,它想劫持网站A的信息。于是它成为中间人拦截到了网站A传给浏览器的证书,然后替换成自己的证书,传给浏览器,之后浏览器就会错误地拿到B的证书里的公钥了,这确实会导致上文“中间人攻击”那里提到的漏洞?
其实这并不会发生,因为证书里包含了网站A的信息,包括域名,浏览器把证书里的域名与自己请求的域名比对一下就知道有没有被掉包了。这个是浏览器自己的策略。
为什么制作数字签名时需要hash一次?
我初识HTTPS的时候就有这个疑问,因为似乎那里的hash有点多余,把hash过程去掉也能保证证书没有被篡改。
最显然的是性能问题,前面我们已经说了非对称加密效率较差,证书信息一般较长,比较耗时。而hash后得到的是固定长度的信息(比如用md5算法hash后可以得到固定的128位的值),这样加解密就快很多。
当然也有安全上的原因,这部分内容相对深一些,感兴趣的可以看这篇解答:crypto.stackexchange.com/a/12780
怎么证明CA机构的公钥是可信的?
你们可能会发现上文中说到CA机构的公钥,我几乎一笔带过,“浏览器保有它的公钥”,这是个什么保有法?怎么证明这个公钥是否可信?
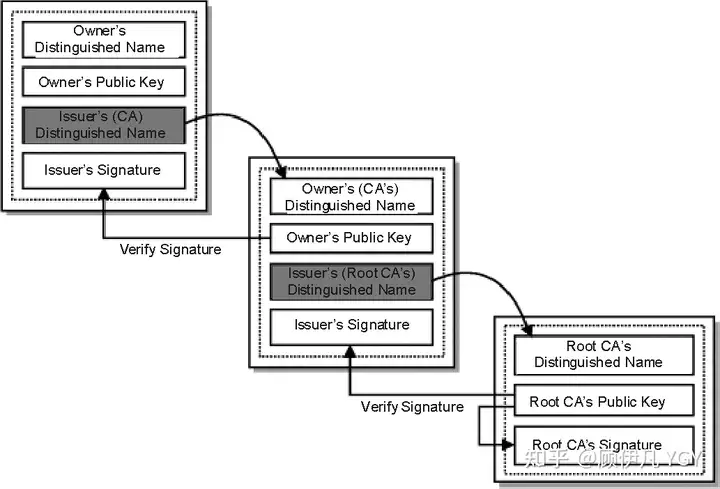
让我们回想一下数字证书到底是干啥的?没错,为了证明某公钥是可信的,即“该公钥是否对应该网站”,那CA机构的公钥是否也可以用数字证书来证明?没错,操作系统、浏览器本身会预装一些它们信任的根证书,如果其中有CA机构的根证书,这样就可以拿到它对应的可信公钥了。
实际上证书之间的认证也可以不止一层,可以A信任B,B信任C,以此类推,我们把它叫做信任链或数字证书链。也就是一连串的数字证书,由根证书为起点,透过层层信任,使终端实体证书的持有者可以获得转授的信任,以证明身份。
另外,不知你们是否遇到过网站访问不了、提示需安装证书的情况?这里安装的就是根证书。说明浏览器不认给这个网站颁发证书的机构,那么你就得手动下载安装该机构的根证书(风险自己承担)。安装后,你就有了它的公钥,就可以用它验证服务器发来的证书是否可信了。
每次进行 HTTPS 请求时都必须在 SSL/TLS 层进行握手传输密钥吗?
这也是我当时的困惑之一,显然每次请求都经历一次密钥传输过程非常耗时,那怎么达到只传输一次呢?
服务器会为每个浏览器(或客户端软件)维护一个session ID,在TLS握手阶段传给浏览器,浏览器生成好密钥传给服务器后,服务器会把该密钥存到相应的session ID下,之后浏览器每次请求都会携带session ID,服务器会根据session ID找到相应的密钥并进行解密加密操作,这样就不必要每次重新制作、传输密钥了!
总结
可以看下这张图,梳理一下整个流程(SSL、TLS握手有一些区别,不同版本间也有区别,不过大致过程就是这样):
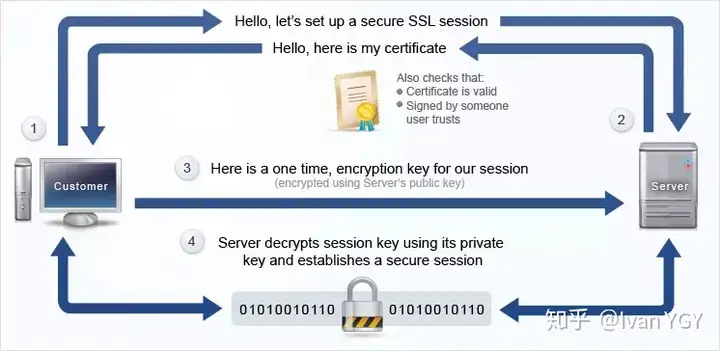
client 向 server 发送请求 https://baidu.com,然后连接到 server 的 443 端口,发送的信息主要是
随机值1客户端支持的加密算法支持的协议版本,比如TLS 1.2版一个 session id,标识是否复用服务器之前的tls连接(需要服务器支持)
server 接收到信息之后给予 client 响应握手信息,包括
随机值2确认使用的加密通信协议版本,比如 TLS 1.2 版本。如果浏览器与服务器支持的版本不一致,服务器关闭加密通信匹配好的协商加密算法,这个加密算法一定是 client 发送给 server 加密算法的子集一个 session id(若同意复用连接)
随即 server 给 client 发送第二个响应报文是数字证书。server 必须要有一套数字证书,可以自己制作,也可以向组织申请。区别就是自己颁发的证书需要客户端验证通过,才可以继续访问,而使用受信任的公司申请的证书则不会弹出提示页面,这套证书其实就是一对公钥和私钥。
传送证书,这个证书其实就是公钥,只是包含了很多信息,如证书的颁发机构,过期时间、server 端的公钥,第三方证书认证机构(CA)的签名,server 端的域名信息等内容。client 解析证书,这部分工作是由 client 的 TLS 来完成的,首先会验证公钥是否有效,比如颁发机构,过期时间等等,如果发现异常,则会弹出一个警告框,提示证书存在问题。如果证书没有问题,那么就生成一个随即值(预主秘钥)。
client 认证证书通过之后,接下来是通过
随机值1、随机值2和预主秘钥组装会话秘钥。然后通过证书的公钥加密会话秘钥。传送加密信息,这部分传送的是用证书加密后的会话秘钥,目的就是让 server 使用秘钥解密得到
随机值1、随机值2和预主秘钥。server 解密得到
随机值1、随机值2和预主秘钥,然后组装会话秘钥,跟客户端会话秘钥相同。client 通过会话秘钥加密一条消息发送给服务端,主要验证服务端是否正常接受客户端加密的消息。
同样 server 也会通过会话秘钥加密一条消息回传给客户端,如果客户端能够正常接受的话表明SSL层连接建立完成了。
至此,我们已自上而下地打通了HTTPS加密的整体脉络以及核心知识点,不知你是否真正搞懂了HTTPS呢?
找几个时间,多看、多想、多理解几次就会越来越清晰的!那么,下面的问题你是否已经可以解答了呢?
- 为什么要用对称加密+非对称加密?
- 为什么不能只用非对称加密?
- 为什么需要数字证书?
- 为什么需要数字签名?
…
还有一些补充:
为什么一定要用三个随机数,来生成”会话密钥”呢
不管是客户端还是服务器,都需要随机数,这样生成的密钥才不会每次都一样。由于 SSL 协议中证书是静态的,因此十分有必要引入一种随机因素来保证协商出来的密钥的随机性。
对于 RSA 密钥交换算法来说,pre-master-key 本身就是一个随机数,再加上 hello 消息中的随机数,三个随机数通过一个密钥导出器最终导出一个对称密钥。
pre-master 的存在在于 SSL 协议不信任每个主机都能产生完全随机的随机数,如果随机数不随机,那么 pre-master-secret 就有可能被猜出来,那么仅适用 pre-master-secret 作为密钥就不合适了,因此必须引入新的随机因素,那么客户端和服务器加上 pre-master-secret 三个随机数一同生成的密钥就不容易被猜出了,一个伪随机可能完全不随机,可是是三个伪随机就十分接近随机了,每增加一个自由度,随机性增加的可不是一。
HTTPS 很安全,很古老也很成熟,为什么一直到今天我们还有66%的网站不支持HTTPS呢?
慢,HTTPS未经任何优化的情况下要比HTTP慢几百毫秒以上(需多次握手),特别在移动端可能要慢500毫秒以上,关于HTTPS慢和如何优化已经是一个非常系统和复杂的话题
贵,特别在计算性能和服务器成本方面。大家也都清楚HTTPS要额外计算,要频繁地做加密和解密操作,几乎每一个字节都需要做加解密,这就产生了服务器成本
协议的网络交互。从TLS的握手过程可以看出,即使不需要进行任何计算,TLS的握手也需要至少1个RTT(round trip time)以上的网络交互。
RTT(Round-Trip Time): 往返时延。在计算机网络中它是一个重要的性能指标,表示从发送端发送数据开始,到发送端收到来自接收端的确认(接收端收到数据后便立即发送确认),总共经历的时延。
Reference