NumPy 简介
NumPy 模块
NumPy:Numerical Python,即数值Python包,是Python进行科学计算的一个基础包,所以是一个掌握其他Scipy库中模块的基础模块,一定需要先掌握该包的主要使用方式。

NumPy 简介
NumPy 发展历史
- 1995年 Jim HugUNin开发了Numeric。
- 随后,Numarray包诞生。
- Travis Oliphants整合Numeric和Numarray,开发Numpy,于2006年发布第一个版本。
- Numpy(Numeric Python)提供了许多高级的数值编程工具,如:矩阵数据类型、矢量处理,以及精密的运算库。专为进行严格的数字处理而产生。多为很多大型金融公司使用,以及核心的科学计算组织如:Lawrence Livermore,NASA用其处理一些本来使用C++,Fortran或Matlab等所做的任务。
- 使用Anaconda发行版的Python,已经帮我们事先安装好了Numpy模块,因此无需另外安装。
- 依照标准的Numpy约定,习惯使用 import numpy as np方式导入该模块。
NumPy、Scipy、Pandas、matplotlib简介
- NumPy——基础,以矩阵为基础的数学计算模块,纯数学存储和处理大型矩阵。这个是很基础的扩展,其余的扩展都是以此为基础。
- Scipy——数值计算库,在numPy库的基础上增加了众多的数学、科学以及工程计算中常用的库函数。方便、易于使用、专为科学和工程设计的Python工具包.它包括统计,优化,整合,线性代数模块,傅里叶变换,信号和图像处理,常微分方程求解器等等。
- Pandas——数据分析,基于numPy 的一种工具,为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。
- matplotlib——绘图,对于图像美化方面比较完善,可以自定义线条的颜色和式样,可以在一张绘图纸上绘制多张小图,也可在一张图上绘制多条线,可以很方便的对数据进行可视化分析。
NumPy核心数据结构:ndarray
NumPy的数组类被称作ndarray,通常被称作数组。注意numpy.array和标准Python库类array.array并不相同,后者只处理一维数组和提供少量功能。
一种由相同类型的元素组成的多维数组,元素数量是实现给定好的。
元素的数据类型由dtype(data-type)对象来指定,每个ndarray只有一种dtype类型。
ndarray的大小固定,创建好数组后数组大小是不会再发生改变的。
ndarray创建
函数创建
np.array
array:接收一个普通的python序列,并将其转换为ndarray
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| print(np.array([1,2,3])) # 用列表创建一维数组
print(np.array((1,2,3))) # 用元组创建一维数组
print(np.array([[1,2,3],[3,4,5]])) # 创建二维数组
print(np.array([[[1,2,3],[3,4,5]], [[4,5,6],[7,8,9]]])) # 创建三维数组
# [1 2 3]
# [1 2 3]
# [[1 2 3]
# [3 4 5]]
# [[[1 2 3]
# [3 4 5]]
# [[4 5 6]
# [7 8 9]]]
|
np.zeros
zeros函数:创建指定长度或者形状的全零数组
1
2
3
4
5
| print(np.zeros((3,4)))
# [[0. 0. 0. 0.]
# [0. 0. 0. 0.]
# [0. 0. 0. 0.]]
|
np.ones
ones函数:创建指定长度或者形状的全1数组。
1
2
3
4
5
| print(np.ones((3,4)))
# [[1. 1. 1. 1.]
# [1. 1. 1. 1.]
# [1. 1. 1. 1.]]
|
np.empty
empty函数:创建一个没有任何具体值的数组(准备地说是创建一些未初始化的ndarray多维数组)
1
2
3
4
5
| print(np.empty((3,4)))
# [[6.23042070e-307 3.56043053e-307 1.37961641e-306 6.23039354e-307]
# [6.23053954e-307 9.34609790e-307 8.45593934e-307 9.34600963e-307]
# [1.86921143e-306 6.23061763e-307 9.34608432e-307 4.24399158e-314]]
|
其他方式:
np.arange
arange函数: 类似python的range函数,通过指定开始值、终值和步长来创建一个一维数组,注意:最终创建的数组不包含终值
1
2
| print(np.arange(9)) # 一个参数时代表是n值
print(np.arange(0,9,3)) # 起始值,终值,步长
|
np.linspace
linspace函数:通过指定开始值、终值和元素个数来创建一个一维数组,数组的数据元素符合等差数列,可以通过endpoint关键字指定是否包含终值,默认包含终值
1
2
| print(np.linspace(0,8,5)) # 形成一个0到8之间的等差数列,共5个元素
# [0. 2. 4. 6. 8.]
|
np.logspace
logspace函数:和linspace函数类似,不过创建的是等比数列数组
1
2
3
4
5
| print(np.logspace(0, 2, 5)) # 范围1-10**2,5个元素
print(np.logspace(0, 5, 6, base=2)) # 范围 1-2**5,6个元素,base是底
# [ 1. 3.16227766 10. 31.6227766 100. ]
# [ 1. 2. 4. 8. 16. 32.]
|
np.random.randint
np.random.randint((m,n,size=(a,b))):创建随机整数数组,选值的范围是 [m,n); a是数组的行;b是数组的列数
1
2
3
4
5
| print(np.random.randint(1,9, size=(3,4)))
# [[1 2 3 5]
# [1 6 2 7]
# [8 6 4 6]]
|
np.random.random
np.random.random((m,n,p)):创建随机数组,范围0-1之间,m为维数,默认为1; n为行数,默认为1; p为列数,默认为1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| print(np.random.random())
print(np.random.random((3,3)))
print(np.random.random((3,4,5)))
0.488869811358302
[[0.04233258 0.3131225 0.68944938]
[0.87059721 0.67384851 0.15279566]
[0.55984723 0.93180875 0.94961102]]
[[[0.59919237 0.1994035 0.51349683 0.74415431 0.08967972]
[0.51202792 0.90590204 0.72763875 0.28438195 0.74681998]
[0.83841345 0.58347337 0.11484284 0.55444849 0.7978348 ]
[0.28018216 0.01040884 0.57392768 0.2434304 0.59227622]]
[[0.5430919 0.42146133 0.14726534 0.03191174 0.26208523]
[0.09970413 0.42386556 0.91181302 0.98131496 0.80365805]
[0.45376739 0.83388326 0.44127547 0.09819375 0.7977529 ]
[0.94739682 0.70020476 0.21155345 0.42489893 0.99906962]]
[[0.91776003 0.10385849 0.52768841 0.79937635 0.69065729]
[0.00796977 0.77475184 0.37661829 0.86323215 0.48432327]
[0.26268683 0.51724413 0.24022605 0.08388501 0.30099232]
[0.09245234 0.07751062 0.77418801 0.43640313 0.99036787]]]
|
np.random.randn
np.random.randn(m,n):创建一个标准正态分布的数组,m表示行数;n表示列数。
1
2
3
4
| print(np.random.randn(3,2))
# [[ 0.10110133 -0.23799349]
# [ 0.44611654 2.52476781]
# [-0.52620207 -1.42422191]]
|
ndarray 对象属性
- ndim 数组轴(维度)的个数,轴的个数被称作秩
- shape 数组的维度, 例如一个2排3列的矩阵,它的shape属性将是(2,3),这个元组的长度显然是秩,即维度或者ndim属性
- size 数组元素的总个数,等于shape属性中元组元素的乘积。
- dtype 一个用来描述数组中元素类型的对象,可以通过创造或指定dtype使用标准Python类型。不过NumPy提供它自己的数据类型。
- itemsize 数组中每个元素的字节大小。例如,一个元素类型为float64的数组itemsiz属性值为8(=64/8),又如,一个元素类型为complex32的数组item属性为4(=32/8).
1
2
3
4
5
6
| arr = np.random.randint(1, 9, size=(3,3))
print(arr.ndim) # 2
print(arr.shape) # (3, 3)
print(arr.dtype) # int32
print(arr.size) # 9
print(arr.itemsize) # 4
|
NumPy 基本数据类型
| 数据类型 |
类型简写 |
说明 |
| int_ |
|
默认整形 |
| intc |
|
等价于long的整形 |
| int8 |
i1 |
字节整形,1个字节,范围:[-128,127] |
| int16 |
i2 |
整形,2个字节,范围:[-32768,32767] |
| int32 |
i3 |
整形,4个字节,范围:[-2^31, 2^31-1] |
| int64 |
i4 |
整形,8个字节,范围:[-2^63, 2^63-1] |
| uint8 |
u1 |
无符号整形, 1个字节, 范围:[0,255] |
| uint16 |
u2 |
无符号整形, 2个字节, 范围:[0,65535] |
| uint32 |
u3 |
无符号整形, 1个字节, 范围:[0, 2^32-1] |
| uint64 |
u4 |
无符号整形, 1个字节, 范围:[0,2^64-1] |
| bool_ |
|
以一个字节形成存储的布尔值(True或者False) |
| float_ |
|
float64简写形式 |
| float16 |
f2 |
半精度浮点型(2字节):1符号位+5位指数+10位的小数部分 |
| float32 |
f4或者f |
单精度浮点型(4字节):1符号位+8位指数+23位的小数部分 |
| float64 |
f8或者d |
双精度浮点型(8字节):1符号位+11位指数+52位的小数部分 |
| complex_ |
c16 |
complex128的简写形式 |
| complex64 |
c8 |
复数,由两个32位的浮点数来表示 |
| complex128 |
c16 |
复数,由两个64位的浮点数来表示 |
| object |
O |
Python对象类型 |
| String_ |
S |
固定长度的字符串类型(每个字符1个字节),比如:要创建一个长度为8的字符串,应该使用S8 |
| Unicode_ |
U |
固定长度的unicode类型的字符串(每个字符占用字节数由平台决定),长度定义类似String_类型 |
ndarray修改类型
创建numpy数组的时候可以通过属性dtype显示指定数据类型,如果不指定的情况下,numpy会自动推断出适合的数据类型,所以一般不需要显示给定数据类型。
如果需要更改一个已经存在的数组的数据类型,可以通过astype方法进行修改从而得到一个新数组
1
2
3
4
| arr = np.random.randint(1, 9, size=(3,3))
print(arr.dtype) # int32
arr2 = arr.astype(float)
print(arr2.dtype) # float64
|
数值型dtype的命名方式为:一个类型名称(eg:int、float等),后接一个表示各个元素位长的数字。比如Python的float数据类型(双精度浮点值),需要占用8个字节(64位),因此在NumPy中记为float64。每个数据类型都有一个类型代码,即简写方式
1
2
| arr3 = np.random.randint(1, 9, size=(3,3), dtype='i8')
print(arr3.dtype) # int64
|
ndarray修改形状
对于一个已经存在的ndarray数组对象而言,可以通过修改形状相关的参数/方法从而改变数组的形状。
直接修改数组ndarray的shape值, 要求修改后乘积不变。
直接使用reshape函数创建一个改变尺寸的新数组,原数组的shape保持不变,但是新数组和原数组共享一个内存空间,也就是修改任何一个数组中的值都会对另外一个产生影响,另外要求新数组的元素个数和原数组一致。
当指定某一个轴为-1的时候,表示将根据数组元素的数量自动计算该轴的长度值。
1
2
3
4
5
6
7
8
9
| arr = np.array([1,2,3,4,5,6,7,8])
print(arr.reshape(2,4))
arr = np.array([1,2,3,4,5,6,7,8])
print(arr.reshape(2,-1))
# [[1 2 3 4]
# [5 6 7 8]]
# [[1 2 3 4]
# [5 6 7 8]]
|
NumPy基本操作
数组与标量、数组之间的运算
数组不用循环即可对每个元素执行批量的算术运算操作,这个过程叫做矢量化,即用数组表达式代替循环的做法。
矢量化数组运算性能比纯Python方式快上一两个数据级。
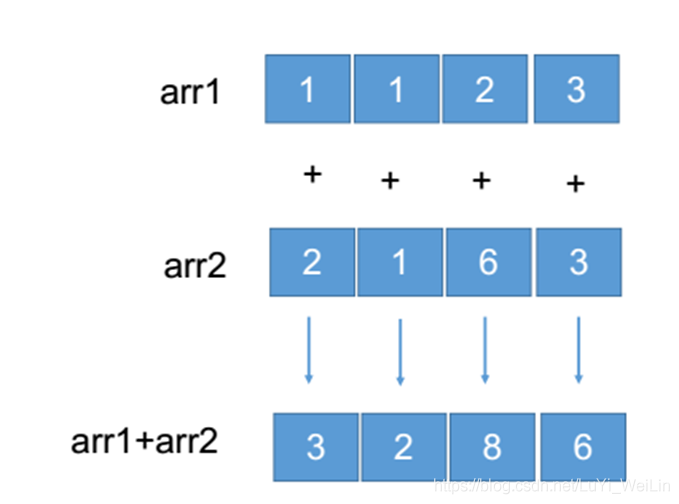
大小相等的两个数组之间的任何算术运算都会将其运算应用到元素级上的操作。
元素级操作:在NumPy中,大小相等的数组之间的运算,为元素级运算,即只用于位置相同的元素之间,所得的运算结果组成一个新的数组,运算结果的位置跟操作数位置相同。
1
2
3
4
5
6
7
8
| # 数组和标量运算
arr1 = np.array((1,2,3,4,5))
print(arr1+2) # [3 4 5 6 7]
print(arr1-3) # [-2 -1 0 1 2]
print(arr1*2) # [ 2 4 6 8 10]
print(arr1/2) # [0.5 1. 1.5 2. 2.5]
print(arr1**2) # [ 1 4 9 16 25]
print(2**arr1) # [ 2 4 8 16 32]
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| # 数组和数组运算
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
arr3 = np.array([[10, 20, 30], [40, 50, 60]])
print(arr2+arr3) # 相乘的两者结构相同
print(arr2*arr3)
print(arr2**arr3)
# [[11 22 33]
# [44 55 66]]
# [[ 10 40 90]
# [160 250 360]]
# [[ 1 1048576 -1010140999]
# [ 0 1296002393 0]]
|
数组的矩阵积(matrix product)
矩阵积(matrix product):两个二维矩阵(行和列的矩阵)满足第一个矩阵的列数与第二个矩阵的行数相同,那么可以进行矩阵的乘法,即矩阵积,矩阵积不是元素级的运算。也称为点积、数量积。
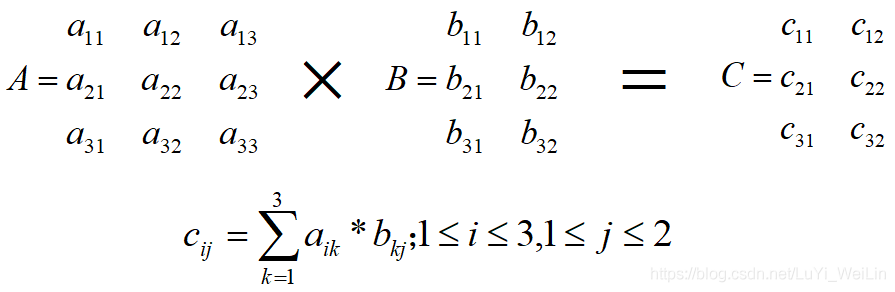
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| arr1 = np.array((
(1, 2, 3),
(4, 5, 6),
(7, 8, 9)))
arr2 = np.array((
(1, 2),
(3, 4),
(5, 6)))
print(np.dot(arr1,arr2))
print(arr1.dot(arr2))
# [[ 22 28]
# [ 49 64]
# [ 76 100]]
# [[ 22 28]
# [ 49 64]
# [ 76 100]]
|
数组的索引与切片
ndarray-多维数组的索引
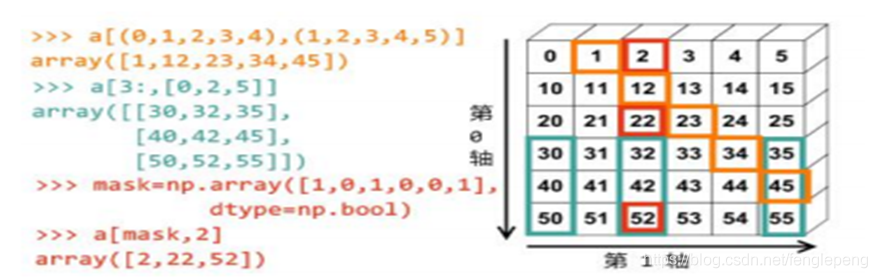
根据数组的形状,进行索引
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| arr2 = np.arange(27).reshape(3, 3, 3)
print(arr2)
print(arr2[0]) # 一维索引
print(arr2[0][1]) # 一维,二维
print(arr2[0][1][2]) # 一维,二维,三维
print(arr2[0, 1, 2]) # 推荐写法
# [[[ 0 1 2]
# [ 3 4 5]
# [ 6 7 8]]
# [[ 9 10 11]
# [12 13 14]
# [15 16 17]]
# [[18 19 20]
# [21 22 23]
# [24 25 26]]]
# [[0 1 2]
# [3 4 5]
# [6 7 8]]
# [3 4 5]
# 5
# 5
|
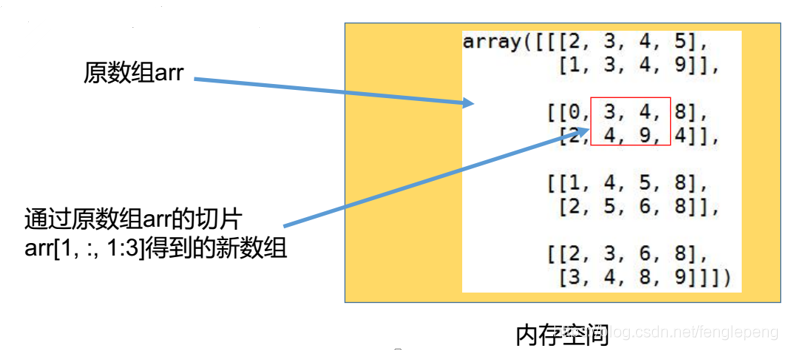
切片
在各维度上单独切片,如果某维度数据都保留,直接使用冒号,不指定起始值和终值
从Numpy切片得到的数组,只是原来数组的一个视图,内部数据使用相同的存储地址,所以对切片得到的数组修改会影响原数组
1
2
3
4
| print(arr2[0:2, 1, :])
# [[ 3 4 5]
# [12 13 14]]
|
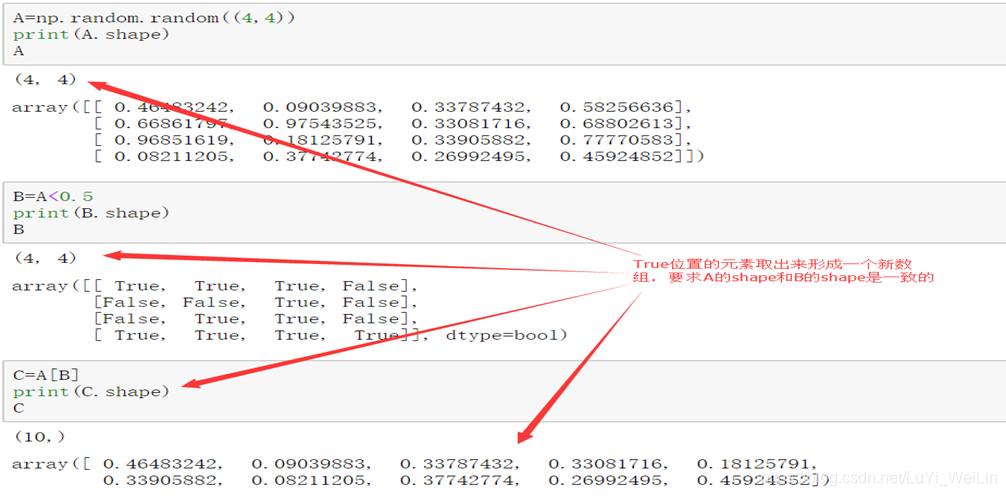
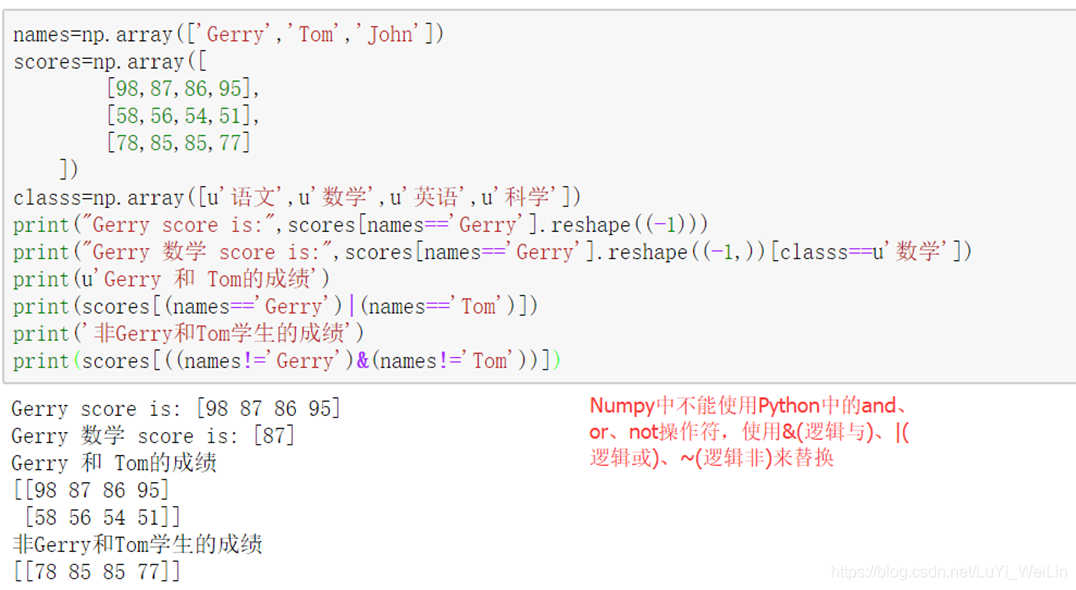
布尔类型索引
利用布尔类型的数组进行数据索引,最终返回的结果是对应索引数组中数据为True位置的值。
ndarray-花式索引
花式索引(Fancy indexing)指的是利用整数数组进行索引的方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| import numpy as np
arr1 = np.arange(32).reshape(8, 4)
print(arr1)
print("========= 获取 0,3,5 行的数据 =========")
print(arr1[[0, 3, 5]])
print("========= 获取 (0,0),(3,2),(5,2) 的数据 =========")
print(arr1[[0, 3, 5], [0, 2, 2]])
print("========= 获取 0,3,5 行 0,2,3 列的数据 =========")
print(arr1[[0, 3, 5]].T[[0, 2, 3]].T)
print(arr1[np.ix_([0, 3, 5], [0, 2, 3])])
|
数组的转置与轴对换
数组转置是指将shape进行重置操作,并将其值重置为原始shape元组的倒置,比如原始的shape值为:(2,3,4),那么转置后的新元组的shape的值为: (4,3,2)
对于二维数组而言(矩阵)数组的转置其实就是矩阵的转置
可以通过调用数组的transpose函数或者T属性进行数组转置操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| arr1 = np.arange(20).reshape(5,-1)
print(arr1)
arr2 = arr1.transpose()
print(arr2)
arr3 = arr1.T
print(arr3)
#################
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]
[16 17 18 19]]
#################
[[ 0 4 8 12 16]
[ 1 5 9 13 17]
[ 2 6 10 14 18]
[ 3 7 11 15 19]]
#################
[[ 0 4 8 12 16]
[ 1 5 9 13 17]
[ 2 6 10 14 18]
[ 3 7 11 15 19]]
|
通用函数:快速的元素级数组成函数
ufunc:numpy模块中对ndarray中数据进行快速元素级运算的函数,也可以看做是简单的函数(接受一个或多个标量值,并产生一个或多个标量值)的矢量化包装器。
主要包括一元函数和二元函数
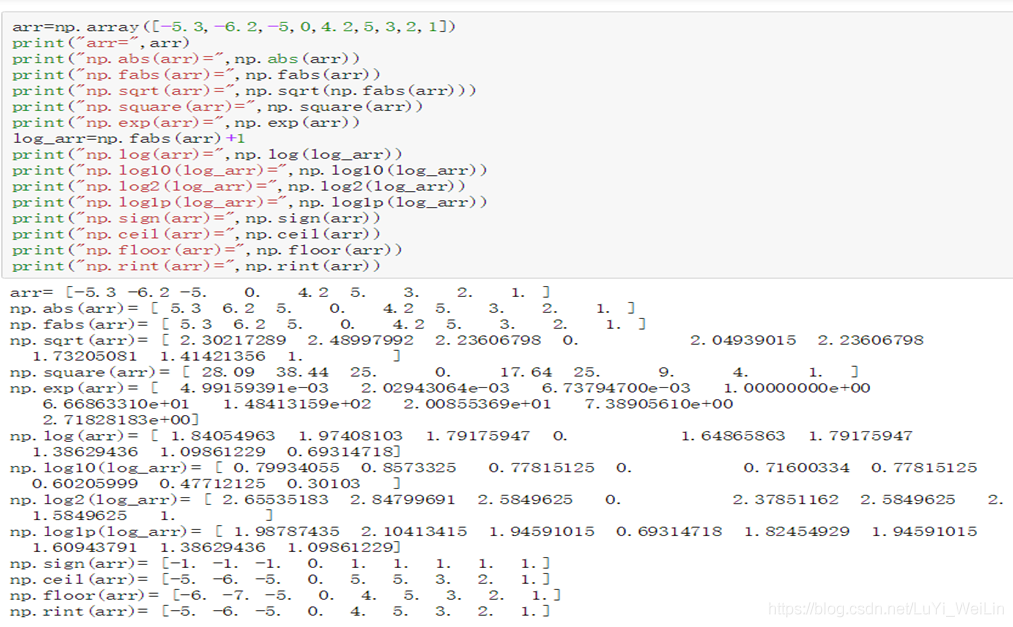
ndarray-通用函数(一元函数)
| 一元ufunc |
描述 |
调用方式 |
| abs, fabs |
计算整数、浮点数或者复数的绝对值,对于非复数,可以使用更快的fabs |
np.abs(arr) np.fabs(arr) |
| sqrt |
计算各个元素的平方根,相当于arr ** 0.5, 要求arr的每个元素必须是非负数 |
np.sqrt(arr) |
| square |
计算各个元素的评分,相当于arr ** 2 |
np.square(arr) |
| exp |
计算各个元素的指数e的x次方 |
np.exp(arr) |
| log、log10、log2、log1p |
分别计算自然对数、底数为10的log、底数为2的log以及log(1+x);要求arr中的每个元素必须为正数 |
np.log(arr) np.log10(arr) np.log2(arr) np.log1p(arr) |
| sign |
计算各个元素的正负号: 1 正数,0:零,-1:负数 |
np.sign(arr) |
| ceil |
计算各个元素的ceiling值,即大于等于该值的最小整数 |
np.ceil(arr) |
| floor |
计算各个元素的floor值,即小于等于该值的最大整数 |
np.floor(arr) |
| rint |
将各个元素值四舍五入到最接近的整数,保留dtype的类型 |
np.rint(arr) |
| modf |
将数组中元素的小数位和整数位以两部分独立数组的形式返回 |
np.modf(arr) |
| isnan |
返回一个表示“那些值是NaN(不是一个数字)”的布尔类型数组 |
np.isnan(arr) |
| isfinite、isinf |
分别一个表示”那些元素是有穷的(非inf、非NaN)”或者“那些元素是无穷的”的布尔型数组 |
np.isfinite(arr) np.isinf(arr) |
| cos、cosh、sin、sinh、tan、tanh |
普通以及双曲型三角函数 |
np.cos(arr) np.sin(arr) np.tan(arr) |
| arccos、arccosh、 arcsin、arcsinh、 arctan、arctanh |
反三角函数 |
|
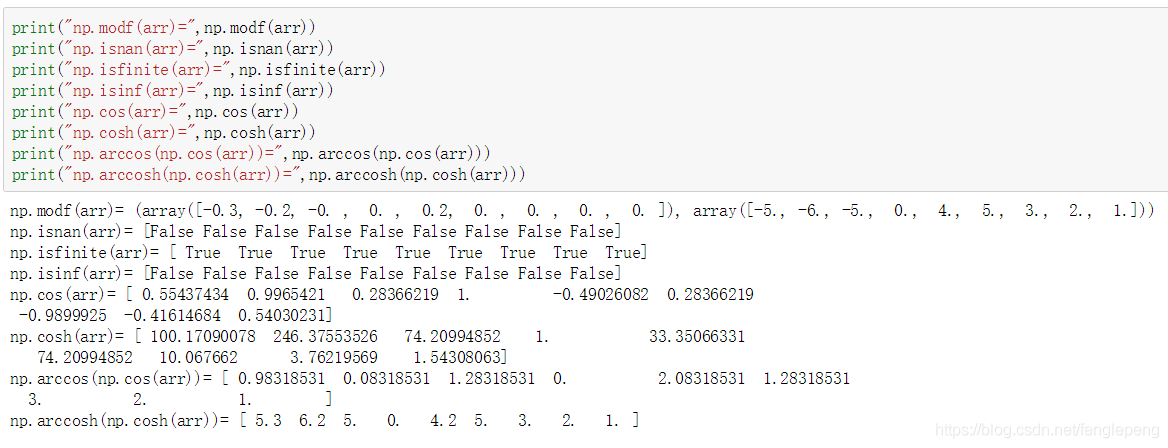
ndarray-通用函数(二元函数)
| 二元ufunc |
描述 |
调用方式 |
| mod |
元素级的取模 |
np.mod(arr1,arr2) |
| dot |
求两个数组的点积 |
np.dot(arr1,arr2) |
| greater、greater_equal、 less、less_equal、 equal、not_equal |
执行元素级别的比较运算,最终返回一个布尔型数组 |
np.greater(arr1, arr2) np.less(arr1, arr2) np.equal(arr1, arr2) |
| logical_and、logical_or、 logical_xor |
执行元素级别的布尔逻辑运算,相当于中缀运算符&、^ |
np.logical_and(arr1,arr2) np.logical_or(arr1,arr2) np.logical_xor(arr1,arr2) |
| power |
求解对数组中的每个元素进行给定次数的指数值,类似于: arr ** 3 |
|
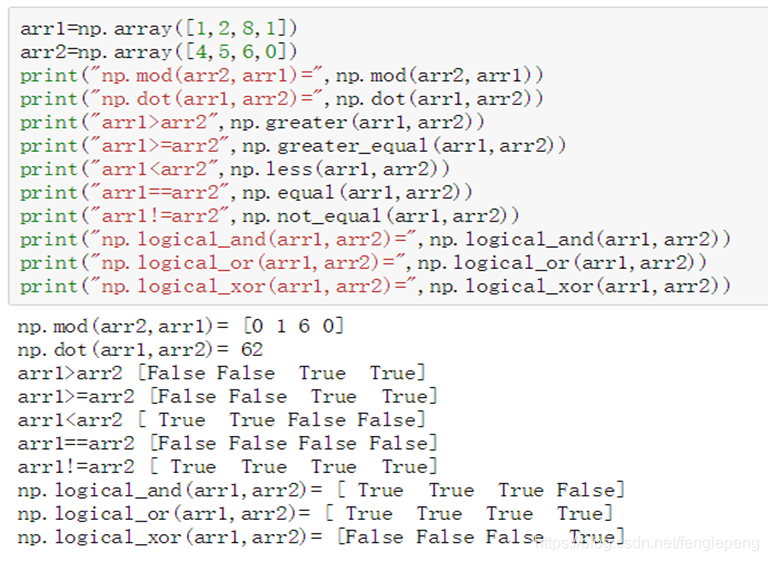
聚合函数
聚合函数是对一组值(eg一个数组)进行操作,返回一个单一值作为结果的函数。当然聚合函数也可以指定对某个具体的轴进行数据聚合操作;常将的聚合操作有:平均值、最大值、最小值、方差等等
当axis=0表示列;axis=1表示行,不写代表计算整个矩阵的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| arr = np.array([[1, 5, 7, 4], [0, 6, 3, 8], [2, 6, 9, 7]])
print(arr)
print('arr的最小值是:', arr.min())
print('arr的最大值是:', arr.max())
print('arr的平均值是:', arr.mean())
print('arr的标准差差是:', arr.std())
print('arr的方差是:', np.power(arr.std(),2))
print('arr中每一列的最小值是:', arr.min(axis=0))
print('arr中每一列的最大值是:', arr.max(axis=0))
print('arr中每一列的平均值是:', arr.mean(axis=0))
print('arr中每一行的最小值是:', arr.min(axis=1))
print('arr中每一行的最大值是:', arr.max(axis=1))
print('arr中每一行的平均值是:', arr.mean(axis=1))
[[1 5 7 4]
[0 6 3 8]
[2 6 9 7]]
arr的最小值是: 0
arr的最大值是: 9
arr的平均值是: 4.833333333333333
arr的标准差差是: 2.733536577809454
arr的方差是: 7.472222222222221
arr中每一列的最小值是: [0 5 3 4]
arr中每一列的最大值是: [2 6 9 8]
arr中每一列的平均值是: [1. 5.66666667 6.33333333 6.33333333]
arr中每一行的最小值是: [1 0 2]
arr中每一行的最大值是: [7 8 9]
arr中每一行的平均值是: [4.25 4.25 6. ]
|
np.where函数
np.where函数是三元表达式x if condition else y的矢量化版本
1
2
3
4
5
6
7
8
9
10
| arr1 = np.array([-1.1,-1.2,-1.3,-1.4,-1.5])
arr2 = np.array([-2.1,-2.2,-2.3,-2.4,-2.5])
condition = (arr1<arr2)
result1 = [x if c else y for (x,y,c) in zip(arr1, arr2, condition)] # 用于一维数组,不能用于多维
result2 = np.where(condition, arr1, arr2) # 适合任何维度
print('使用python语法,结果为:', result1,';数据类型为:', type(result1))
print('使用np.where语法,结果为:', result2,';数据类型为:', type(result2))
# 使用python语法,结果为: [-2.1, -2.2, -2.3, -2.4, -2.5] ;数据类型为: <class 'list'>
# 使用np.where语法,结果为: [-2.1 -2.2 -2.3 -2.4 -2.5] ;数据类型为: <class 'numpy.ndarray'>
|
将数组中的所有异常数字替换为0,比如将NaN替换为0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| arr3 = np.array([
[1, 2, np.nan, 4],
[4, 5, 6, np.nan],
[7, 8, 9, np.inf],
[np.inf, np.e, np.pi, 4]
])
condition = np.isnan(arr3)|np.isinf(arr3)
print(arr3)
print(np.where(condition, 0, arr3))
##############################################################3
[[1. 2. nan 4. ]
[4. 5. 6. nan]
[7. 8. 9. inf]
[ inf 2.71828183 3.14159265 4. ]]
[[1. 2. 0. 4. ]
[4. 5. 6. 0. ]
[7. 8. 9. 0. ]
[0. 2.71828183 3.14159265 4. ]]
|
np.unique函数
np.unique函数的主要作用是将数组中的元素进行去重操作(也就是只保存不重复的数据)
1
2
3
4
5
6
7
| arr1 = np.array(['a', 'b', 'c', 'a', 'd', 'c', 'e'])
arr2 = np.unique(arr1)
print('原始数据:', arr1)
print('去重之后的数据:', arr2)
# 原始数据: ['a' 'b' 'c' 'a' 'd' 'c' 'e']
# 去重之后的数据: ['a' 'b' 'c' 'd' 'e']
|