0、内涵
1
2
| Python2 1:臃肿,源码的重复量很多 2:语法不清晰,掺杂C,php,Java的一些陋习。
Python3 几乎是重构后的源码,规范,清晰,优美。
|
1、编译时指定字节
1
2
3
4
5
6
7
8
| python2 在编译安装时,可以通过参数 --enable-unicode=ucs2 或 --enable-unicode=ucs4 分别用于指定使用2个字节、4个字节表示一个unicode;
python3 无法进行选择,默认使用 ucs4
impor sys
print(sys.maxunicode)
|
2、默认编码方式
1
2
3
4
5
| Python2 默认编码方式是 ascll 码
Python3 默认编码方式是 utf-8
Python2 输出中文要加在文件加 # -*- encoding:utf-8 -*-
Python3 不需要
|
3、print
1
2
| Python2 可以使用 print,也可以使用 print(),例:print('111') 或 print '111'
Python3 只能使用 print(),例:print('111')
|
1
2
| Python2 中是 raw_input
Python3 中是 input
|
5、除法
1
2
| Python2 不会取余,如:5/2=2
Python3 会取余 如:5/2=2.5
|
6、函数继承
1
2
| Python3 中的函数都是新式类
Python2 中的函数新式类和经典类共存
|
新式类都继承自 object,且 super() 和 mro() 只存在于新式类,只要继承自object,都是新式类。
在多继承问题中,有两种继承方式:
广度优先。即A和E能同时到达F,则走完A之后走C,即 D->B->A->C->E->F,新式类使用广度优先。
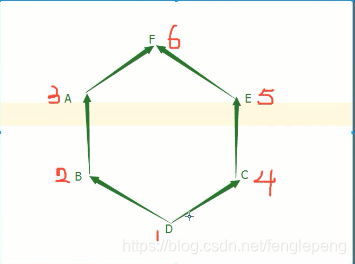
super的本质:不是单纯找父类,而是根据调用者的节点位置的广度优先顺序来的,即和广度优先正好相逆 F->E->C->A->B->D
深度优先。一条路走到头,即 D->B->A->F->C->E,经典类遵循深度优先。
7、True和False
1
2
| python2 中是两个全局变量可以重新赋值
python3 中为两个关键字,不可重新赋值
|
8、文件操作
1
2
3
| python2:readliens() 读取文件的所有行,返回一个列表,包含所有行的结束符。
xreadliens() 返回一个生成器,循环取值。
python3: 只有readlines()。
|
9、包结构
1
2
| python2:必须有__init__
python3:不是必须的了
|
10、其他
sort()
1
2
3
4
5
6
|
sorted(iterable, cmp=None, key=None, reverse=False)
sorted(iterable,key=None,reverse=False)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| '迭代':
py2:xrange、range
py3:统一使用range,并且range的机制也进行修改并提高了大数据集生成效率
'Nonlocal':
py3专有的(声明为非局部变量)
'yield':
py2:yield
py3:yield/yield from
exec语句被python3废弃,统一使用exec函数
不相等操作符"<>"被Python3废弃,统一使用"!="
long整数类型被Python3废弃,统一使用int
迭代器iterator的next()函数被Python3废弃,统一使用next(iterator)
异常StandardError 被Python3废弃,统一使用Exception
字典变量的has_key函数被Python废弃,统一使用in关键词
file函数被Python3废弃,统一使用open来处理文件,可以通过io.IOBase检查文件类型
|