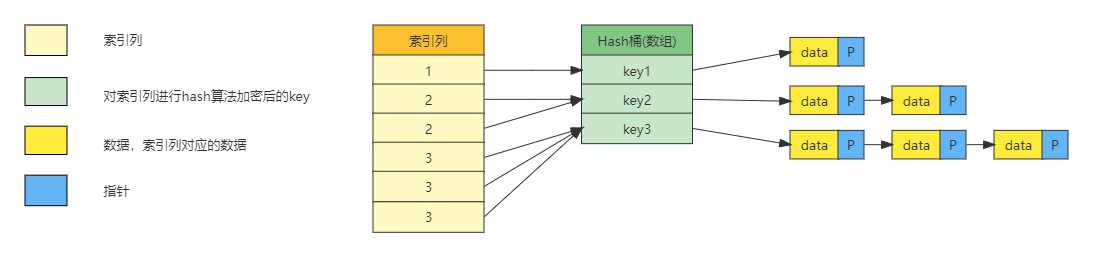
mysql> SHOW variables like "innodb_adaptive_hash_index"; +----------------------------+-------+ | Variable_name | Value | +----------------------------+-------+ | innodb_adaptive_hash_index | ON | +----------------------------+-------+ 1 row in set (0.16 sec)
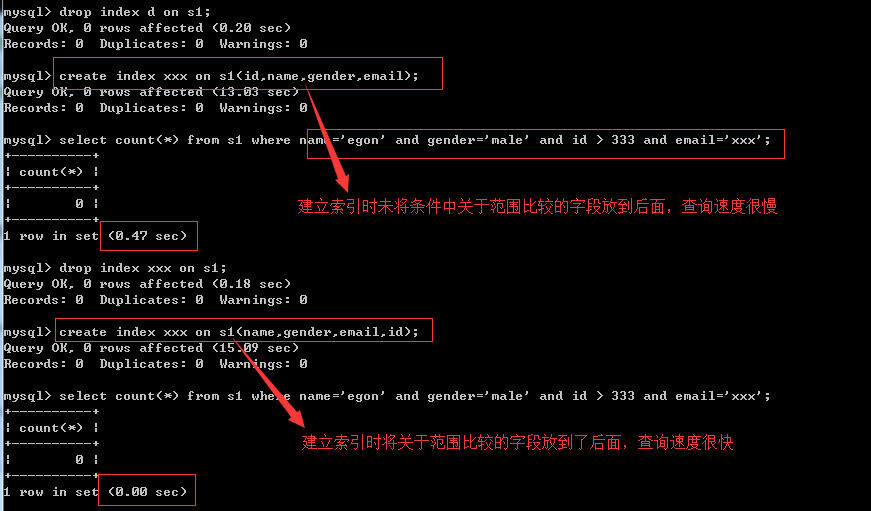
# 假设表 tb1 有字段 (id int, a int, b int, c int, d varchar),有联合索引(a,b,c),主键索引id,唯一索引d,记录110条 SELECT * FROM tb1 WHERE a=xxx; -- 可以使用索引 SELECT * FROM tb1 WHERE a=xxx ORDERBY b; -- 可以使用索引 SELECT * FROM tb1 WHERE a=xxx AND b=xxx ORDERBY c; -- 可以使用索引 SELECT * FROM tb1 WHERE a=xxx AND c=xxx AND b=xxx; -- 可以使用索引
SELECT * FROM tb1 WHERE c=xxx AND b=xxx; -- 不能使用索引,因为索引的第一个值是 a,在使用索引树进行查找的没事,没有办法利用 a 进行比较,所以不知道找哪一个子树,所以没有办法利用索引。
SELECT * FROM tb1 WHERE a=xxx AND c=xxx; -- 可以使用索引,但是需要回表,5.6之前,只利用索引a,把找到的符合索引a的数据,全部进行回表读取,然后再判断并返回满足条件的数据,5.6之后,直接会找到满足条件的对应的主键记录,然后再回表,用到了一个叫做索引下推的东西:直接使用组合索引判断符合查询条件的数据,然后再回表取数据 SELECT * FROM tb1 WHERE a>xxx AND b=xxx; -- 同上,5.6 之前,只能利用索引a,范围索引会导致等值索引失效,5.6 之后,直接会找到满足条件的对应的主键记录,然后再回表,也是用了一个叫做索引下推的东西。
SELECT * FROM tb1 WHERE a=xxx ORDERBY c; -- 可以利用索引,但是不能通过索引直接得到结果,还需要自己执行一次 filesort 操作
SELECT * FROM tb1 WHERE a>1; -- 不能使用索引,因为范围太大,需要回表次数太多,还不如直接把主键索引的数据加载到内存中再排序效率高。 SELECT * FROM tb1 order a,b,c; -- 不能使用索引,因为范围太大,需要回表次数太多,还不如直接把主键索引的数据加载到内存中再排序效率高。 SELECT * FROM tb1 WHERE a>100; -- 可以使用索引,因为符合条件的记录较少,回表次数较少,所以写 WHERE 条件的时候,尽量把条件写的更精确。 SELECT a FROM tb1 WHERE a>1; -- 可以使用索引,因为索引中包含a字段,不需要回表,但是查询返回的数据的结果是 按照 a字段 排序的结果,不是按照 主键 排序的结果。 SELECT a,idFROM tb1 WHERE a>1; -- 可以使用索引,因为索引中包含a字段,而且包含id字段,不需要回表,但是查询返回的数据的结果是 按照 a字段 排序的结果,不是按照 主键 排序的结果。
# 类型不一样 SELECT * FROM tb1 WHERE a=1-- 可以使用索引 SELECT * FROM tb1 WHERE a='1'-- 可以使用索引,会先将 '1' 转化为 1 SELECT * FROM tb1 WHERE d='1'-- 可以使用索引 SELECT * FROM tb1 WHERE d=1-- 不可以使用索引
-- 范围很大时,全表扫描,全表扫描比利用索引还快 MariaDB [lp]> EXPLAIN SELECT * FROM t WHERE f>10000; +------+-------------+-------+------+---------------+------+---------+------+-------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+-------------+-------+------+---------------+------+---------+------+-------+-------------+ | 1 | SIMPLE | t | ALL | weiyi_f | NULL | NULL | NULL | 80503 | Using where | +------+-------------+-------+------+---------------+------+---------+------+-------+-------------+ 1 row in set (0.00 sec)
-- 范围不大时,会利用索引,然后回表获取数据 MariaDB [lp]> EXPLAINSELECT * FROM t WHERE f>70000; +------+-------------+-------+-------+---------------+---------+---------+------+------+-----------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+-------------+-------+-------+---------------+---------+---------+------+------+-----------------------+ | 1 | SIMPLE | t | range | weiyi_f | weiyi_f | 5 | NULL | 9998 | Using index condition | +------+-------------+-------+-------+---------------+---------+---------+------+------+-----------------------+ 1 row in set (0.01 sec)
不等于
1 2 3 4 5 6 7
-- 不等于,范围很大,全表扫描比利用索引还快 MariaDB [lp]> EXPLAIN SELECT * FROM t WHERE f!=70000; +------+-------------+-------+------+---------------+------+---------+------+-------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+-------------+-------+------+---------------+------+---------+------+-------+-------------+ | 1 | SIMPLE | t | ALL | weiyi_f | NULL | NULL | NULL | 80503 | Using where | +------+-------------+-------+------+---------------+------+---------+------+-------+-------------+
BETWEEN…AND…
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
-- 范围不大时,会利用索引,然后回表获取数据 MariaDB [lp]> EXPLAIN SELECT * FROM t WHERE f BETWEEN 10 AND 100; +------+-------------+-------+-------+---------------+---------+---------+------+------+-----------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+-------------+-------+-------+---------------+---------+---------+------+------+-----------------------+ | 1 | SIMPLE | t | range | weiyi_f | weiyi_f | 5 | NULL | 91 | Using index condition | +------+-------------+-------+-------+---------------+---------+---------+------+------+-----------------------+ 1 row in set (0.00 sec)
-- 范围很大时,全表扫描,全表扫描比利用索引还快 MariaDB [lp]> EXPLAINSELECT * FROM t WHERE f BETWEEN10AND40000; +------+-------------+-------+------+---------------+------+---------+------+-------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+-------------+-------+------+---------------+------+---------+------+-------+-------------+ | 1 | SIMPLE | t | ALL | weiyi_f | NULL | NULL | NULL | 80503 | Using where | +------+-------------+-------+------+---------------+------+---------+------+-------+-------------+ 1 row in set (0.00 sec)
like
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
-- % 在后面可以利用索引。 MariaDB [lp]> EXPLAIN SELECT * FROM t WHERE d like 'd%'; +------+-------------+-------+-------+---------------+---------+---------+------+------+-----------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+-------------+-------+-------+---------------+---------+---------+------+------+-----------------------+ | 1 | SIMPLE | t | range | weiyi_d | weiyi_d | 768 | NULL | 4950 | Using index condition | +------+-------------+-------+-------+---------------+---------+---------+------+------+-----------------------+ 1 row in set (0.00 sec)
-- % 在前面不可以利用索引。 MariaDB [lp]> EXPLAINSELECT * FROM t WHERE d like'%d'; +------+-------------+-------+------+---------------+------+---------+------+-------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+-------------+-------+------+---------------+------+---------+------+-------+-------------+ | 1 | SIMPLE | t | ALL | NULL | NULL | NULL | NULL | 79752 | Using where | +------+-------------+-------+------+---------------+------+---------+------+-------+-------------+ 1 row in set (0.00 sec)
-- d 的类型为字符串,利用不到索引。 MariaDB [lp]> EXPLAIN SELECT * FROM t WHERE d=22; +------+-------------+-------+------+---------------+------+---------+------+-------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+-------------+-------+------+---------------+------+---------+------+-------+-------------+ | 1 | SIMPLE | t | ALL | weiyi_d | NULL | NULL | NULL | 79752 | Using where | +------+-------------+-------+------+---------------+------+---------+------+-------+-------------+ 1 row in set (0.00 sec)
-- a 的类型为 int MariaDB [lp]> EXPLAINSELECT * FROM t WHERE a=22; +------+-------------+-------+------+---------------+----------+---------+-------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+-------------+-------+------+---------------+----------+---------+-------+------+-------+ | 1 | SIMPLE | t | ref | zuhe_abc | zuhe_abc | 5 | const | 1 | | +------+-------------+-------+------+---------------+----------+---------+-------+------+-------+ 1 row in set (0.00 sec)
MariaDB [lp]> EXPLAINSELECT * FROM t WHERE a='22'; +------+-------------+-------+------+---------------+----------+---------+-------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+-------------+-------+------+---------------+----------+---------+-------+------+-------+ | 1 | SIMPLE | t | ref | zuhe_abc | zuhe_abc | 5 | const | 1 | | +------+-------------+-------+------+---------------+----------+---------+-------+------+-------+
MariaDB [lp]> EXPLAIN SELECT * FROM t ORDER BY a; +------+-------------+-------+------+---------------+------+---------+------+-------+----------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+-------------+-------+------+---------------+------+---------+------+-------+----------------+ | 1 | SIMPLE | t | ALL | NULL | NULL | NULL | NULL | 79752 | Using filesort | +------+-------------+-------+------+---------------+------+---------+------+-------+----------------+ 1 row in set (0.00 sec)
MariaDB [lp]> EXPLAINSELECT a FROM t ORDERBY a; +------+-------------+-------+-------+---------------+----------+---------+------+-------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+-------------+-------+-------+---------------+----------+---------+------+-------+-------------+ | 1 | SIMPLE | t | index | NULL | zuhe_abc | 15 | NULL | 79752 | Using index | +------+-------------+-------+-------+---------------+----------+---------+------+-------+-------------+ 1 row in set (0.00 sec)
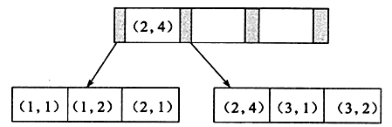
5、最左前缀匹配原则,非常重要的原则
对于组合索引 MySQL 会一直向右匹配直到遇到范围查询(>、<、BETWEEN、LIKE)就停止匹配(指的是范围大了,有索引速度也慢)
比如 a=1 AND b=2 AND c>3 AND d=4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。