MySQL 索引为什么使用B+Tree
0、先验知识
二分查找法
二分查找法也叫作折半查找法,它是在有序数组中查找指定数据的搜索算法。它的优点是等值查询、范围查询性能优秀,缺点是更新数据、新增数据、删除数据维护成本高。
首先定位left和right两个指针。
计算
(left+right)/2。判断除2后索引位置值与目标值的大小比对。
索引位置值大于目标值就-1,right移动;如果小于目标值就+1,left移动。
1、背景
MySQL底层使用的存储结构是 B+Tree,那为什么选择 B+Tree,我们对不同的存储结构对比分析一下,请看下文,尽量用通俗的话讲清楚。
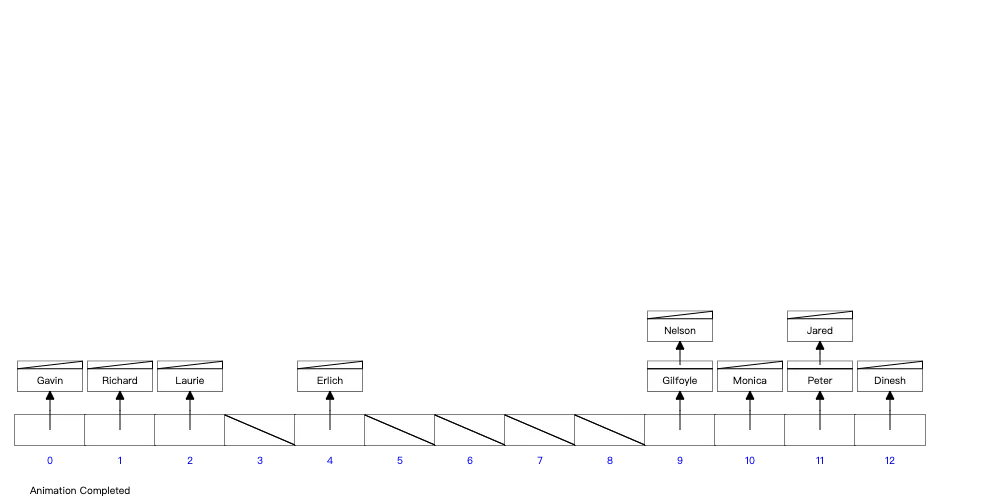
首先假设我们有这么一张 MySQL 表 user:
| id | name |
|---|---|
| 1 | Richard |
| 2 | Erlich |
| 3 | Jared |
| 4 | Nelson |
| 5 | Gilfoyle |
| 6 | Dinesh |
| 7 | Peter |
| 8 | Monica |
| 9 | Laurie |
| 10 | Gavin |
| 11 | Russ |
在没有给name这一列创建索引的情况下,当我们要执行 SELECT * FROM user WHERE name='Gavin'时,MySQL需要从第一条数据开始(Richard),逐行对比。
这种情况下查询操作的时间复杂度是 O(n),当数据量达到上百万时,查询操作就会变得很慢,这时就需要采取一些手段进行优化。
2、散列表(Hash table,也叫哈希表)
散列表(Hash table,也叫哈希表),是根据键(Key)而直接访问在内存储存位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。
上述 user 表的数据,如果按哈希表来存储,结构如下图所示。哈希表的优点是即使数据量非常大,也只需要进行一次 hash 运算(通过链表解决哈希碰撞问题),就能快速找到某一条数据,时间复杂度 O(1)。
如果我们用哈希建了索引,那么对于如下这种SQL,通过哈希,可以快速检索出数据:
select * from t_user_info where id=1;
如果是一个范围查询,那么使用哈希算法作为索引,这种情况就很难办,我们可能需要 遍历一遍所有的数据,然后做排序,最后得到结果,这显然是不能接受的。因此,这种情况,哈希索引是不适合做为 InnoDB 的索引的。
select * from t_user_info where id>10;
对于范围查询,我们怎么优化了,很容易就想到了“二叉查找树”,二叉查找树的左边节点都是小于根节点的,右边节点都是大于根节点的,这样不仅单点查询不会很慢,此外可以加快范围查询效率。
3、二叉查找树(Binary Search Tree, BST)
二叉查找树(Binary Search Tree, BST),也称为二叉搜索树、有序二叉树(ordered binary tree)或排序二叉树(sorted binary tree),是指一棵空树或者具有下列性质的二叉树:
- 若任意节点的左子树不空,则左子树上所有节点的值均小于它的根节点的值;
- 若任意节点的右子树不空,则右子树上所有节点的值均大于或等于它的根节点的值;
- 任意节点的左、右子树也分别为二叉查找树;
二叉查找树相比于其他数据结构的优势在于查找、插入的时间复杂度较低,为 O(logn)
对 user 的 name 列建立索引后,数据存储结构如图所示:
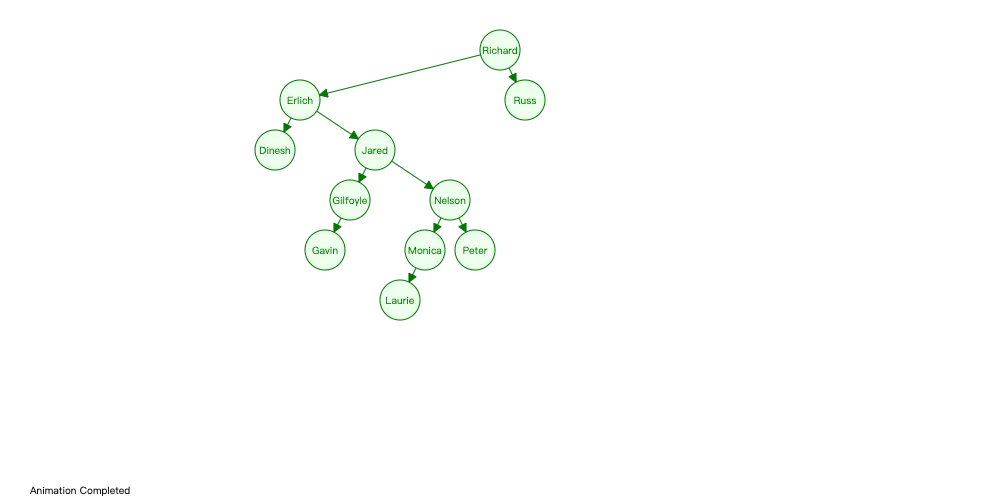
最大查询次数为二叉树的最大高度 logn。二叉查找树和哈希表相比,虽然单条数据查询不如哈希表快,但是 O(logn) 的时间复杂度也可以接受,并且能支持范围查找。
可以用二叉查找树作为底层存储结构吗?
但是 BST 有一个致命缺点:假设我们的id列是一个自增整型,给一列建立索引时,对应的 BST 如下图所示:
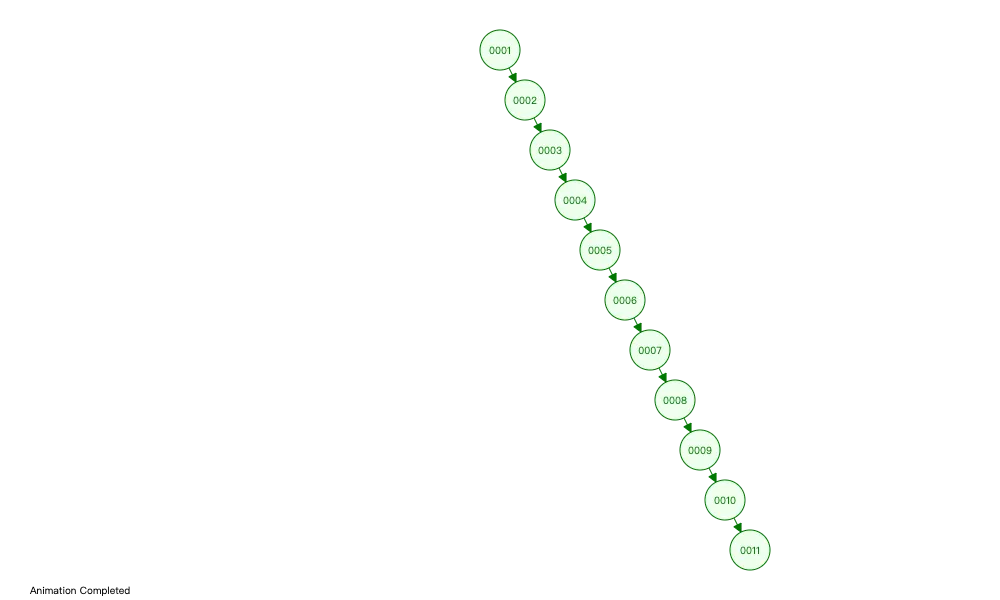
可以看到,当我们按顺序进行插入数据时,BST 退化成了一个单向链表,时间复杂度又成了 O(n)。
如果 BST 能够在增加数据的时候,自动调整树的高度,让树能够尽量平衡就好了。当二叉查找树是平衡的时候,也就是树的每个节点的左右子树深度相差不超过 1 的时候,查询的时间复杂度为 O(log2(N)),具有比较高的效率。
也就是说,二叉查找树的性能非常依赖于它的平衡程度,这就导致其不适合作为 MySQL 底层索引的数据结构。
为了解决这个问题,并提高查询效率,人们发明了多种在二叉查找树基础上的改进型数据结构,如平衡二叉树、B-Tree、B+Tree 等。
接下来介绍的红黑树和 AVL 树,都是能够进行自动平衡的二叉查找树。
4、红黑树(Red-black tree)
红黑树是一种自平衡二叉查找树,是在计算机科学中用到的一种数据结构,典型用途是实现关联数组。它在1972年由鲁道夫·贝尔发明,被称为 “对称二叉B-Tree”。红黑树的结构复杂,但它的操作有着良好的最坏情况运行时间,并且在实践中高效:它可以在 O(logn) 时间内完成查找、插入和删除。
红黑树通过在插入和删除节点时进行颜色变换和旋转操作,使得树始终保持平衡状态,它具有以下特点:
- 每个节点非红即黑;
- 根节点总是黑色的;
- 每个叶子节点都是黑色的空节点(NIL 节点);
- 如果节点是红色的,则它的子节点必须是黑色的(反之不一定);
- 从任意节点到它的叶子节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)。
用红黑树存储索引,插入数据时会自动旋转调整树的高度,结构如下:
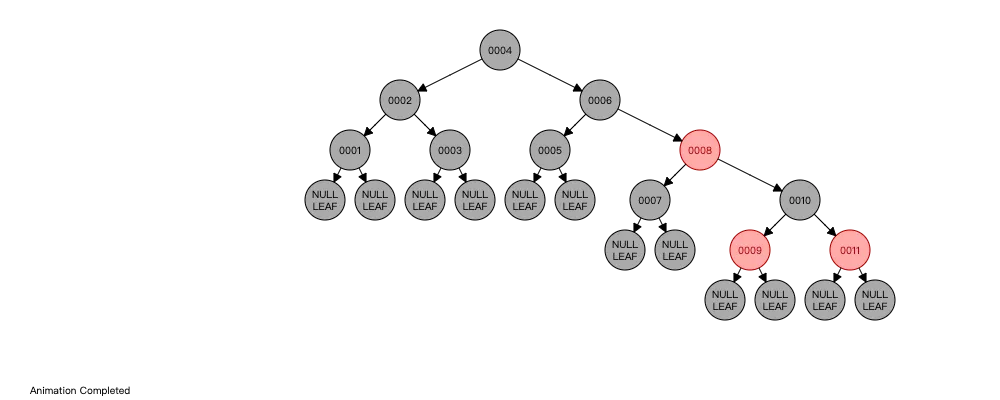
和 AVL 树不同的是,红黑树并不追求严格的平衡,而是大致的平衡。正因如此,红黑树的查询效率稍有下降,因为红黑树的平衡性相对较弱,可能会导致树的高度较高,这可能会导致一些数据需要进行多次磁盘 IO 操作才能查询到,这也是 MySQL 没有选择红黑树的主要原因。也正因如此,红黑树的插入和删除操作效率大大提高了,因为红黑树在插入和删除节点时只需进行 O(1) 次数的旋转和变色操作,即可保持基本平衡状态,而不需要像 AVL 树一样进行 O(logn) 次数的旋转操作。
红黑树的应用还是比较广泛的,TreeMap、TreeSet 以及 JDK1.8 的 HashMap 底层都用到了红黑树。对于数据在内存中的这种情况来说,红黑树的表现是非常优异的。
5、AVL树
在计算机科学中,AVL 树是最早被发明的自平衡二叉查找树。在AVL树中,任一节点对应的两棵子树的最大高度差为 1,因此它也被称为高度平衡树。查找、插入和删除在平均和最坏情况下的时间复杂度都是 O(logn)。增加和删除元素的操作则可能需要借由一次或多次树旋转,以实现树的重新平衡。
AVL 树采用了旋转操作来保持平衡。主要有四种旋转操作:LL 旋转、RR 旋转、LR 旋转和 RL 旋转。其中 LL 旋转和 RR 旋转分别用于处理左左和右右失衡,而 LR 旋转和 RL 旋转则用于处理左右和右左失衡。
AVL 树比红黑树更加平衡,用AVL树存储索引,查询效率会比红黑树稍高,但插入效率比红黑树差。结构如下:
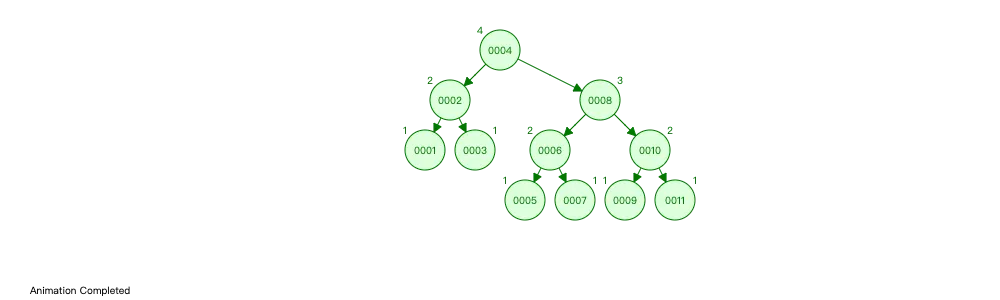
可以用 AVL 树或是红黑树作为底层存储结构吗?
如果我们要在上述 AVL 树中,查找 11 这个元素,那么就需要经过4次查找:4 -> 8 -> 10 -> 11
在 MySQL 中,每查找一个节点,都需要进行一次 IO 操作,查找 11 这个元素就需要进行 4 次 IO 操作。当数据量达到10k时,查找一个元素可能需要进行 14 次 IO,这显示是不能接受的。
根据实际情况,在内存中操作数据的耗时与 IO 耗时相比起来,几乎可以忽略不计。如果每一个树结点,都存储多个元素的话,就可以降低树的高度,减少 IO 次数了。这就是 B-Tree/B+Tree 的原理。
6、B-Tree(B树,B减树)
在计算机科学中,B-Tree 是一种自平衡的树,能够保持数据有序。这种数据结构能够让查找数据、顺序访问、插入数据及删除的动作,都在对数时间内完成。
B-Tree,概括来说是一个一般化的二叉查找树一个节点可以拥有2个以上的子节点。与自平衡二叉查找树不同,B-Tree 适用于读写相对大的数据块的存储系统,例如磁盘。B-Tree 减少定位记录时所经历的中间过程,从而加快存取速度。B-Tree 这种数据结构可以用来描述外部存储。这种数据结构常被应用在数据库和文件系统的实现上。
B-Tree 就是常说的“B减树(B-树)”,又名平衡多路(即不止两个子树)查找树,它和平衡二叉树的不同有这么几点:
- 平衡二叉树节点最多有两个子树,而 B-Tree 每个节点可以有多个子树,M 阶 B-Tree 表示该树每个节点最多有 M 个子树
- 平衡二叉树每个节点只有一个数据和两个指向孩子的指针,而 B-Tree 每个中间节点有 k-1 个关键字和 k 个子树(k 介于阶数 M 和 M/2 之间,M/2 向上取整)
- B-Tree 的所有叶子节点都在同一层,并且叶子节点只有关键字,指向孩子的指针为 null
- B-Tree 的节点数据大小也是按照左小右大
示例:将 user 表中的11条数据全部存在一个7阶 B-Tree 中(每个节点最多存储6个数据)
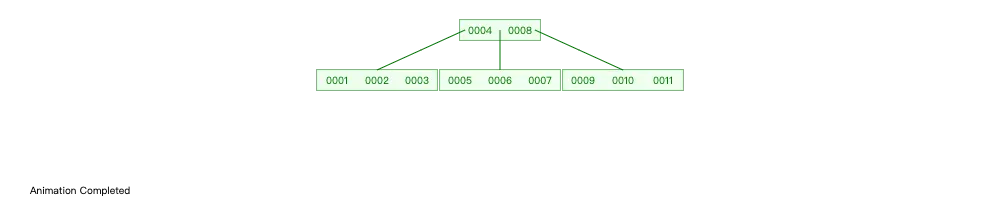
- 规定 m 阶 B-tree 中,根结点至少有2个子结点。
- 根结点中关键字的个数为
1~m-1,比节点数目少一个; - 非根结点至少有
[m/2](向上取整)个子结点,相应的,关键字个数为[m/2]-1~m-1
可以看到查找11这个元素,只需要进行2次IO,比之前的AVL树减少了2次。
那么用 B-Tree 作为底层存储结构吗?
B-Tree 中的每个元素,除了存放关键字外,还会存放额外的数据(比如对应数据记录的地址或者数据内容)。而实际情况是,每个节点的存储空间是有上限的,在内部节点中存储这些数据,会导致内部节点能够存储的元素数据变小。阶数变小就会导致树变高,IO次数增加,比如将上述数据存在3阶 B-Tree 中,查找11就需要3次IO:
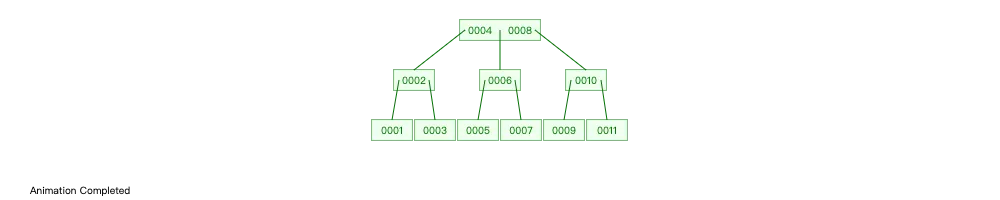
并且针对 B-Tree 进行范围查找,效率并不太高。比如对上图 B-Tree,执行SELECT * FROM user WHERE id>4,需要进行7次IO。
针对 B-Tree 的一些局限,衍生了一些变种: B+Tree、B*树,而MySQL底层使用的存储结构,就是 B+Tree
7、B+Tree
B+Tree 是一种树数据结构,通常用于数据库和操作系统的文件系统中。 B+Tree 的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。 B+Tree 元素自底向上插入,这与二叉树恰好相反。
B+Tree 和 B-Tree 类似,但是多了一些规则:
- 非叶子结点的子树指针个数与关键字(节点中的元素个数)个数相同
- 非叶子结点的子树指针
P[i],指向关键字值属于[K[i], K[i+1])的子树(B-Tree 是开区间) - 所有叶子结点都有一个指针,连接成一个链表
- 所有关键字都在叶子结点出现
- 只有叶子节点存储值,内部节点只存储关键字
通过 B+Tree 来存储以上数据的结构如下:
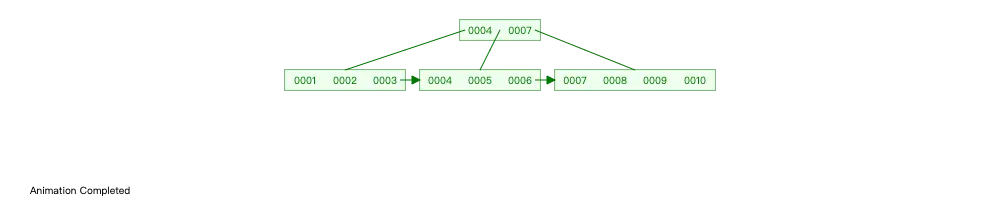
** B+Tree 的优点:**
- 内部节点只保存关键字,提高了阶数,加快查找时间。
- 叶子节点中包含所有数据,所有叶子节点形成一个有序链表,让范围查找更高效。
B-Tree 相对于 B+Tree 的优点是,如果经常访问的数据离根节点很近,这种情况下数据检索会要比 B+Tree 快。因为 B-Tree 的非叶子节点本身存有关键字其数据的地址。
基于 B+Tree 的那么多优点,MySQL最终将其作为了索引的底层存储结构。
B-Tree/B+Tree 总结
B-Tree
m 阶 B-Tree 满足以下条件:
- 每个节点至多可以拥有m棵子树。
- 根节点,只有至少有2个节点(要么极端情况,就是一棵树就一个根节点,单细胞生物,即是根,也是叶,也是树)。
- 非根非叶的节点至少有的
Ceil(m/2)个子树(Ceil表示向上取整,如5阶B-Tree,每个节点至少有3个子树,也就是至少有3个叉)。 - 非叶节点中的信息包括
[n,A0,K1,A1,K2,A2,…,Kn,An],其中n表示该节点中保存的关键字个数,K为关键字且Ki<Ki+1,A为指向子树根节点的指针。 - 从根到叶子的每一条路径都有相同的长度(叶子节点在相同的层)
B+Tree
B+Tree 与 B-Tree 的差异在于:
- B+Tree 非叶子节点不存储data,只存储key。
- 所有的关键字全部存储在叶子节点上。
- 每个叶子节点含有一个指向相邻叶子节点的指针,带顺序访问指针的 B+Tree 提高了区间查找能力。
- 非叶子节点可以看成索引部分,节点中仅含有其子树(根节点)中的最大(或最小)关键字。
B-Tree/B+Tree 索引的性能分析
依据:使用磁盘I/O次数评价索引结构的优劣。
主存和磁盘以页为单位交换数据,将一个节点的大小设为等于一个页,因此每个节点只需一次I/O就可以完全载入。
根据B-Tree的定义,可知检索一次最多需要访问h个节点,渐进复杂度: O(h)=O(logdN)
dmax=floor(pagesize/(keysize+datasize+pointsize))
一般实际应用中,出度d是非常大的数字,通常超过100,因此h非常小(通常不超过3,3层可存大约一百万数据)
B-Tree 中一次检索最多需要 h-1 次I/O(根节点常驻内存)
B+Tree 内节点不含data域,因此出度d更大,则h更小,I/O次数少,效率更高,故 B+Tree 更适合外存索引。