01-Redis 五大数据类型
五大数据类型
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。它支持多种类型的数据结构,如
- 字符串(strings)
- 散列(hashes)
- 列表(lists)
- 集合(sets)
- 有序集合(sorted sets) 与范围查询
- bitmaps
- hyperloglogs
- 地理空间(geospatial) 索引半径查询。
Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
Redis 键(key)的一些操作
注:字母大写小写都一样
1 | |
字符串 String
String 类型是 Redis 最基本的数据类型,你可以理解成 Memcached 一模一样的类型,一个 key 对应一个 value,value 其实不仅可以是 String,也可以是数字。
String 类型是二进制安全的,意思是 Redis 的 String 可以包含任何数据,比如jpg图片或者序列化的对象。
常规计数:微博数,粉丝数等。
常用指令
set、get、del、exists(是否存在)、append(追加)、strlen(获取长度)
1 | |
incr、decr一定要是数字才能进行加减,+1 和 -1。incrby、decrby将 key 中储存的数字加上或减去指定的数量。
1 | |
range [范围]getrange获取指定区间范围内的值,类似between…and的关系,从零到负一表示全部
1 | |
setrange设置指定区间范围内的值,格式是setrange key值 具体值
1 | |
setex(set with expire)设置过期时间setnx(set if not exist)如何 key 存在则不覆盖值,还是原来的值(分布式中常用)
1 | |
mset:同时设置一个或多个 key-value 对。mget:返回所有(一个或多个) key 的值。 如果给定的 key 里面,有某个 key 不存在,则此 key 返回特殊值nilmsetnx:当所有 key 都成功设置,返回 1 。如果所有给定 key 都设置失败(至少有一个 key 已经存在),那么返回 0 。相当于原子性操作,要么都成功,要么都不成功。
1 | |
- 存储对象:
set user:1 value(json数据)
1 | |
getset:先get再set
1 | |
列表 List
Redis 列表是简单的字符串列表,按照插入顺序排序,你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
- 如果键不存在,创建新的链表
- 如果键已存在,新增内容
- 如果值全移除,对应的键也就消失了
- 链表的操作无论是头和尾效率都极高,但假如是对中间元素进行操作,效率就很惨淡了。
list就是链表,略有数据结构知识的人都应该能理解其结构。使用Lists结构,我们可以轻松地实现最新消息排行等功能。List的另一个应用就是消息队列,可以利用List的PUSH操作,将任务存在List中,然后工作线程再用POP操作将任务取出进行执行。Redis还提供了操作List中某一段的api,你可以直接查询,删除List中某一段的元素。
Redis的list是每个子元素都是String类型的双向链表,可以通过push和pop操作从列表的头部或者尾部添加或者删除元素,这样List即可以作为栈,也可以作为队列。
常用指令
Lpush:将一个或多个值插入到列表头部。(LeftPush左)Rpush:将一个或多个值插入到列表尾部。(RightPush右)lrange:返回列表中指定区间内的元素,区间以偏移量 START 和 END 指定。- 其中 0 表示列表的第一个元素, 1 表示列表的第二个元素,以此类推。
- 使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。
1 | |
lpop命令用于移除并返回列表的第一个元素。当列表 key 不存在时,返回 nil 。rpop移除列表的最后一个元素,返回值为移除的元素。
1 | |
Lindex,按照索引下标获得元素(-1代表最后一个,0代表是第一个)
1 | |
llen用于返回列表的长度。
1 | |
lrem (lrem key count element)根据参数 COUNT 的值,移除列表中与参数 VALUE 相等的元素。如果有多个一样的lement,则删除列表最前面的的
1 | |
ltrim key对一个列表进行修剪(trim),只保留指定列表中区间内的元素,不在指定区间之内的元素都将被删除。
1 | |
rpoplpush移除列表的最后一个元素,并将该元素添加到另一个列表并返回。
1 | |
lset key index value: 将列表 key 下标为 index 的元素的值设置为 value 。
1 | |
linsert key before/after pivot value: 用于在列表的元素前或者后插入元素。将值 value 插入到列表 key 当中,位于值 pivot 之前或之后。如果pivot有多个,则插入最前面的那个
1 | |
集合Set
Redis的Set是String类型的无序集合,它是通过HashTable实现的 !
在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。
Redis还为集合提供了求交集、并集、差集等操作,可以非常方便的实现如共同关注、共同喜好、二度好友等功能,对上面的所有集合操作,你还可以使用不同的命令选择将结果返回给客户端还是存集到一个新的集合中。
常用指令
sadd将一个或多个成员元素加入到集合中,不能重复smembers返回集合中的所有的成员。sismember命令判断成员元素是否是集合的成员。
1 | |
scard,获取集合里面的元素个数
1 | |
srem key value用于移除集合中的一个或多个成员元素
1 | |
srandmember key用于返回集合中随机元素。后面加上数字,则随机返回对应数量的成员,默认一个
1 | |
spop key [count]用于移除指定 key 集合的随机元素,不填则默认一个。
1 | |
smove SOURCE DESTINATION MEMBER, 将指定成员 member 元素从 source 集合移动到 destination 集合
1 | |
- 数字集合类:
- 差集: sdiff
- 交集: sinter
- 并集: sunion
1 | |
哈希Hash
Redis hash 是一个String类型的field和value的映射表,hash特别适合用于存储对象。类似Java里面的Map
常用指令
hset、hget命令用于为哈希表中的字段赋值hmset、hmget同时将多个field-value对设置到哈希表中。会覆盖哈希表中已存在的字段- Redis 4.0.0开始弃用HMSET,请使用HSET
hgetall用于返回哈希表中,所有的字段和值。hdel用于删除哈希表 key 中的一个或多个指定字段
1 | |
hlen获取哈希表中字段的数量
1 | |
hexists查看哈希表的指定字段是否存在
1 | |
hkeys获取哈希表中的所有域(field)hvals返回哈希表所有域(field)的值
1 | |
hincrby为哈希表中的字段值加上指定增量值
1 | |
hsetnx为哈希表中不存在的的字段赋值 ,存在则不赋值
1 | |
有序集合Zset
Redis zset 和 set 一样,也是 String 类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个 double 类型的分数。之前 set 是 k1 v1 v2 v3,现在 zset 是 k1 score1 v1 score2 v2
Redis 正是通过分数来为集合中的成员进行从小到大的排序,zset 的成员是唯一的,但是分数(Score)却可以重复。
和 set 相比,sorted set 增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列,比如一个存储全班同学成绩的 sorted set,其集合value可以是同学的学号,而 score 就可以是其考试得分,这样在数据插入集合的时候,就已经进行了天然的排序。
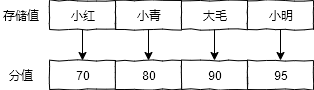
可以用 sorted set 来做带权重的队列,比如普通消息的 score 为 1,重要消息的 score 为 2,然后工作线程可以选择按 score 的倒序来获取工作任务。让重要的任务优先执行。
常用指令
zadd将一个或多个成员元素及其分数值加入到有序集当中。zrange返回有序集中,指定区间内的成员
1 | |
zrangebyscore返回有序集合中指定分数区间的成员列表。有序集成员按分数值递增(从小到大) 次序排列。ZREVRANGE从大到小
1 | |
zrem移除有序集中的一个或多个成员
1 | |
zcard命令用于计算集合中元素的数量
1 | |
zcount计算有序集合中指定分数区间的成员数量。
1 | |
zrank返回有序集中指定成员的排名。其中有序集成员按分数值递增(从小到大)顺序排列。
1 | |
zrevrank返回有序集中成员的排名。其中有序集成员按分数值递减(从大到小)排序
1 | |
代码实战
1 | |
内部实现
有序集合是由 ziplist (压缩列表) 或 skiplist (跳跃表) 组成的。
ziplist
当数据比较少时,有序集合使用的是 ziplist 存储的,如下代码所示:
1 | |
从结果可以看出,有序集合把 myset 键值对存储在 ziplist 结构中了。 有序集合使用 ziplist 格式存储必须满足以下两个条件:
- 有序集合保存的元素个数要小于 128 个;
- 有序集合保存的所有元素成员的长度都必须小于 64 字节。
如果不能满足以上两个条件中的任意一个,有序集合将会使用 skiplist 结构进行存储。 接下来我们来测试以下,当有序集合中某个元素长度大于 64 字节时会发生什么情况? 代码如下:
1 | |
通过以上代码可以看出,当有序集合保存的所有元素成员的长度大于 64 字节时,有序集合就会从 ziplist 转换成为 skiplist。
小贴士:可以通过配置文件中的 zset-max-ziplist-entries(默认 128)和 zset-max-ziplist-value(默认 64)来设置有序集合使用 ziplist 存储的临界值。
skiplist
skiplist 数据编码底层是使用 zset 结构实现的,而 zset 结构中包含了一个字典和一个跳跃表,源码如下:
1 | |
跳跃表的结构如下图所示:
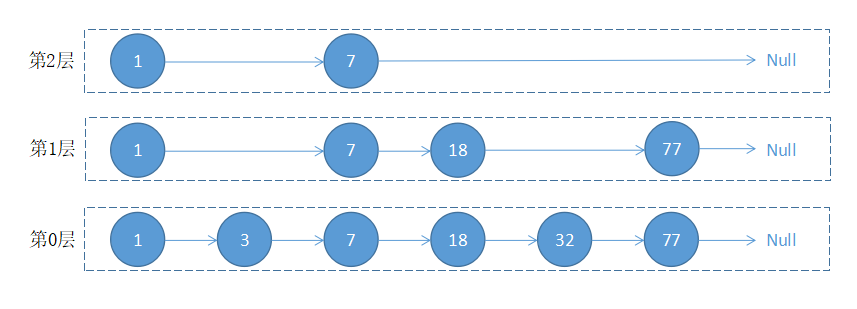
根据以上图片展示,当我们在跳跃表中查询值 32 时,执行流程如下:
- 从最上层开始找,1 比 32 小,在当前层移动到下一个节点进行比较;
- 7 比 32 小,当前层移动下一个节点比较,由于下一个节点指向 Null,所以以 7 为目标,移动到下一层继续向后比较;
- 18 小于 32,继续向后移动查找,对比 77 大于 32,以 18 为目标,移动到下一层继续向后比较;
- 对比 32 等于 32,值被顺利找到。
从上面的流程可以看出,跳跃表会想从最上层开始找起,依次向后查找,如果本层的节点大于要找的值,或者本层的节点为 Null 时,以上一个节点为目标,往下移一层继续向后查找并循环此流程,直到找到该节点并返回,如果对比到最后一个元素仍未找到,则返回 Null。
为什么是跳跃表?而非红黑树?
因为跳跃表的性能和红黑树基本相近,但却比红黑树更好实现,所有 Redis 的有序集合会选用跳跃表来实现存储。
再来一个解释
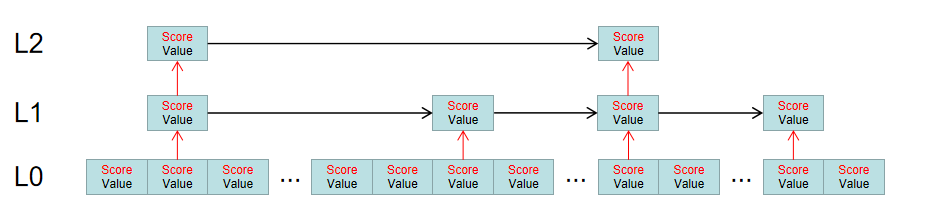
所有的元素都会在L0层的链表中,根据分数进行排序,同时会有一部分节点有机会被抽取到L1层中,作为一个稀疏索引,同样L1层中的索引也有一定机会被抽取到L2层中,组成一个更稀疏的索引列表。
这种跳跃表的实现,其实和二分查找的思路有点接近,只是一方面因为二分查找只能适用于数组,而无法适用于链表,所以为了让链表有二分查找类似的效率,就以空间换时间来达到目的。