Stream 持久化的发布/订阅系统
Redis Stream 从概念上来说,就像是一个 仅追加内容 的 消息链表,把所有加入的消息都一个一个串起来,每个消息都有一个唯一的 ID 和内容,这很简单,让它复杂的是从 Kafka 借鉴的另一种概念:消费者组(Consumer Group) (思路一致,实现不同):
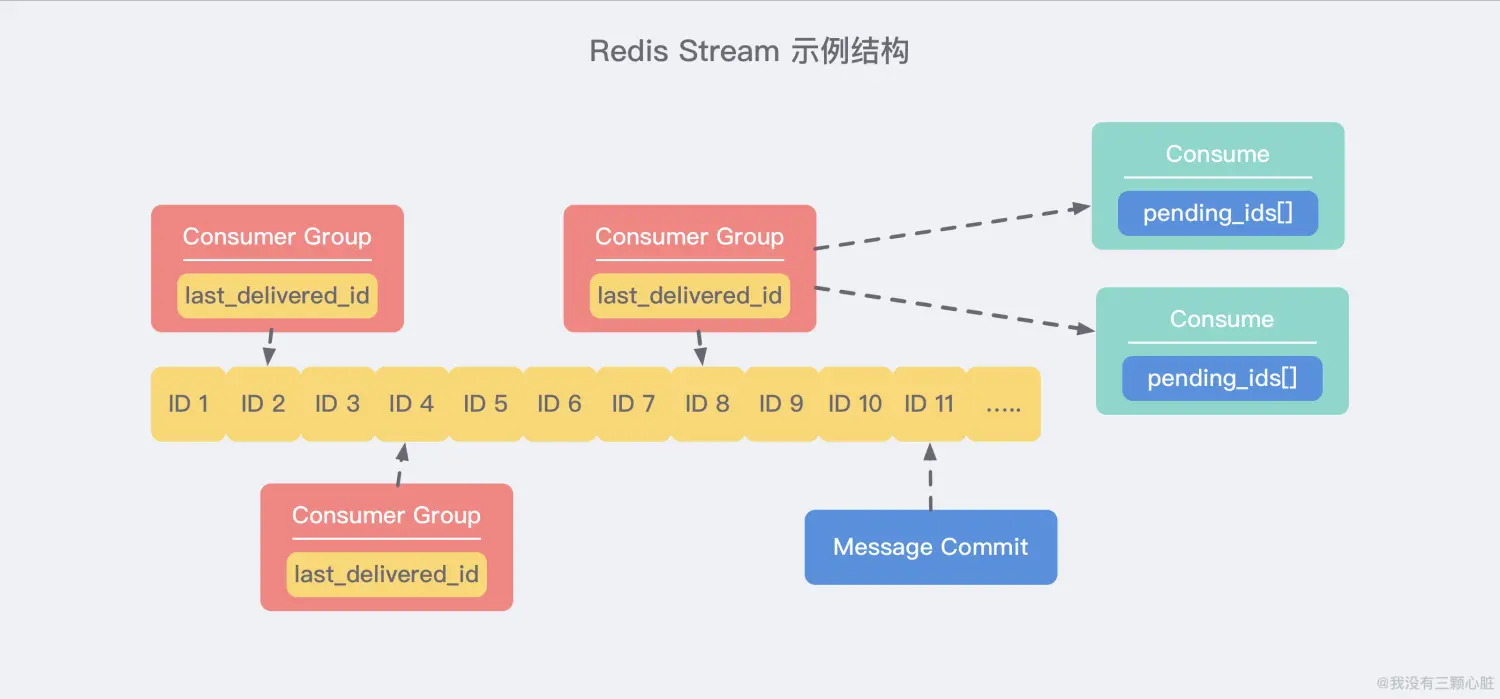
上图展示了一个典型的 Stream 结构。每个 Stream 都有唯一的名称,它就是 Redis 的 key,在我们首次使用 xadd 指令追加消息时自动创建。
我们对图中的一些概念做一下解释:
Consumer Group:消费者组,可以简单看成记录流状态的一种数据结构。
消费者既可以选择使用 XREAD 命令进行 独立消费,也可以多个消费者同时加入一个消费者组进行 组内消费。
同一个消费者组内的消费者共享所有的 Stream 信息,同一条消息只会有一个消费者消费到,这样就可以应用在分布式的应用场景中来保证消息的唯一性。
**last_delivered_id**:用来表示消费者组消费在 Stream 上 消费位置 的游标信息。
每个消费者组都有一个 Stream 内 唯一的名称,消费者组不会自动创建,需要使用 XGROUP CREATE 指令来显式创建,并且需要指定从哪一个消息 ID 开始消费,用来初始化 last_delivered_id 这个变量。
**pending_ids**:每个消费者内部都有的一个状态变量,用来表示 已经被客户端获取,但是还没有 ack 的消息。
记录的目的是为了 保证客户端至少消费了消息一次,而不会在网络传输的中途丢失而没有对消息进行处理。
如果客户端没有 ack,那么这个变量里面的消息 ID 就会越来越多,一旦某个消息被 ack,它就会对应开始减少。这个变量也被 Redis 官方称为 **PEL(Pending Entries List)**。
消息 ID 和消息内容
消息 ID
消息 ID 如果是由 XADD 命令返回自动创建的话,那么它的格式是:timestampInMillis-sequence (毫秒时间戳-序列号)。
例如 1527846880585-5,它表示当前的消息是在毫秒时间戳 1527846880585 时产生的,并且是该毫秒内产生的第 5 条消息。
这些 ID 的格式看起来有一些奇怪,为什么要使用时间来当做 ID 的一部分呢?
一方面,我们要 满足 ID 自增 的属性,另一方面,也是为了 支持范围查找 的功能。由于 ID 和生成消息的时间有关,这样就使得在根据时间范围内查找时基本上是没有额外损耗的。
当然消息 ID 也可以由客户端自定义,但是形式必须是 **整数-整数**,而且后面加入的消息的 ID 必须要大于前面的消息 ID。
消息内容
消息内容就是普通的键值对,形如 hash 结构的键值对。
增删改查简单示例
增删改查命令很简单,详情如下:
xadd:追加消息xdel:删除消息,这里的删除仅仅是设置了标志位,不影响消息总长度xrange:获取消息列表,会自动过滤已经删除的消息xlen:消息长度del:删除Stream
使用示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
| # * 号表示服务器自动生成ID,后面顺序跟着一堆key/value
127.0.0.1:6379> xadd codehole * name laoqian age 30 # 名字叫laoqian,年龄30岁
1527849609889-0 # 生成的消息ID
127.0.0.1:6379> xadd codehole * name xiaoyu age 29
1527849629172-0
127.0.0.1:6379> xadd codehole * name xiaoqian age 1
1527849637634-0
127.0.0.1:6379> xlen codehole
(integer) 3
127.0.0.1:6379> xrange codehole - + # -表示最小值, +表示最大值
1) 1) 1527849609889-0
2) 1) "name"
2) "laoqian"
3) "age"
4) "30"
2) 1) 1527849629172-0
2) 1) "name"
2) "xiaoyu"
3) "age"
4) "29"
3) 1) 1527849637634-0
2) 1) "name"
2) "xiaoqian"
3) "age"
4) "1"
127.0.0.1:6379> xrange codehole 1527849629172-0 + # 指定最小消息ID的列表
1) 1) 1527849629172-0
2) 1) "name"
2) "xiaoyu"
3) "age"
4) "29"
2) 1) 1527849637634-0
2) 1) "name"
2) "xiaoqian"
3) "age"
4) "1"
127.0.0.1:6379> xrange codehole - 1527849629172-0 # 指定最大消息ID的列表
1) 1) 1527849609889-0
2) 1) "name"
2) "laoqian"
3) "age"
4) "30"
2) 1) 1527849629172-0
2) 1) "name"
2) "xiaoyu"
3) "age"
4) "29"
127.0.0.1:6379> xdel codehole 1527849609889-0
(integer) 1
127.0.0.1:6379> xlen codehole # 长度不受影响
(integer) 3
127.0.0.1:6379> xrange codehole - + # 被删除的消息没了
1) 1) 1527849629172-0
2) 1) "name"
2) "xiaoyu"
3) "age"
4) "29"
2) 1) 1527849637634-0
2) 1) "name"
2) "xiaoqian"
3) "age"
4) "1"
127.0.0.1:6379> del codehole # 删除整个Stream
(integer) 1
|
独立消费示例
我们可以在不定义消费组的情况下进行 Stream 消息的 独立消费,当 Stream 没有新消息时,甚至可以阻塞等待。
Redis 设计了一个单独的消费指令 xread,可以将 Stream 当成普通的消息队列(list)来使用。使用 xread 时,我们可以完全忽略 消费组(Consumer Group) 的存在,就好比 Stream 就是一个普通的列表(list):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| # 从Stream头部读取两条消息
127.0.0.1:6379> xread count 2 streams codehole 0-0
1) 1) "codehole"
2) 1) 1) 1527851486781-0
2) 1) "name"
2) "laoqian"
3) "age"
4) "30"
2) 1) 1527851493405-0
2) 1) "name"
2) "yurui"
3) "age"
4) "29"
# 从Stream尾部读取一条消息,毫无疑问,这里不会返回任何消息
127.0.0.1:6379> xread count 1 streams codehole $
(nil)
# 从尾部阻塞等待新消息到来,下面的指令会堵住,直到新消息到来
127.0.0.1:6379> xread block 0 count 1 streams codehole $
# 我们从新打开一个窗口,在这个窗口往Stream里塞消息
127.0.0.1:6379> xadd codehole * name youming age 60
1527852774092-0
# 再切换到前面的窗口,我们可以看到阻塞解除了,返回了新的消息内容,而且还显示了一个等待时间,这里我们等待了93s
127.0.0.1:6379> xread block 0 count 1 streams codehole $
1) 1) "codehole"
2) 1) 1) 1527852774092-0
2) 1) "name"
2) "youming"
3) "age"
4) "60"
(93.11s)
|
客户端如果想要使用 xread 进行 顺序消费,一定要 记住当前消费 到哪里了,也就是返回的消息 ID。下次继续调用 xread 时,将上次返回的最后一个消息 ID 作为参数传递进去,就可以继续消费后续的消息。
block 0 表示永远阻塞,直到消息到来,block 1000 表示阻塞 1s,如果 1s 内没有任何消息到来,就返回 nil:
1
2
3
| 127.0.0.1:6379> xread block 1000 count 1 streams codehole $
(nil)
(1.07s)
|
创建消费者组示例
Stream 通过 xgroup create 指令创建消费组(Consumer Group),需要传递起始消息 ID 参数用来初始化 last_delivered_id 变量:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| 127.0.0.1:6379> xgroup create codehole cg1 0-0 # 表示从头开始消费
OK
# $表示从尾部开始消费,只接受新消息,当前Stream消息会全部忽略
127.0.0.1:6379> xgroup create codehole cg2 $
OK
# 获取Stream信息
127.0.0.1:6379> xinfo codehole
1) length
2) (integer) 3 # 共3个消息
3) radix-tree-keys
4) (integer) 1
5) radix-tree-nodes
6) (integer) 2
7) groups
8) (integer) 2 # 两个消费组
9) first-entry # 第一个消息
10) 1) 1527851486781-0
2) 1) "name"
2) "laoqian"
3) "age"
4) "30"
11) last-entry # 最后一个消息
12) 1) 1527851498956-0
2) 1) "name"
2) "xiaoqian"
3) "age"
4) "1"
# 获取Stream的消费组信息
127.0.0.1:6379> xinfo groups codehole
1) 1) name
2) "cg1"
3) consumers
4) (integer) 0 # 该消费组还没有消费者
5) pending
6) (integer) 0 # 该消费组没有正在处理的消息
2) 1) name
2) "cg2"
3) consumers # 该消费组还没有消费者
4) (integer) 0
5) pending
6) (integer) 0 # 该消费组没有正在处理的消息
|
组内消费示例
Stream 提供了 xreadgroup 指令可以进行消费组的组内消费,需要提供 消费组名称、消费者名称和起始消息 ID。它同 xread 一样,也可以阻塞等待新消息。读到新消息后,对应的消息 ID 就会进入消费者的 PEL(正在处理的消息) 结构里,客户端处理完毕后使用 xack 指令 通知服务器,本条消息已经处理完毕,该消息 ID 就会从 PEL 中移除,下面是示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
| # > 号表示从当前消费组的 last_delivered_id 后面开始读
# 每当消费者读取一条消息 last_delivered_id 变量就会前进
# xreadgroup GROUP 组名 消费者名 count num streams streams名
127.0.0.1:6379> xreadgroup GROUP cg1 c1 count 1 streams codehole >
1) 1) "codehole"
2) 1) 1) 1527851486781-0
2) 1) "name"
2) "laoqian"
3) "age"
4) "30"
127.0.0.1:6379> xreadgroup GROUP cg1 c1 count 1 streams codehole >
1) 1) "codehole"
2) 1) 1) 1527851493405-0
2) 1) "name"
2) "yurui"
3) "age"
4) "29"
127.0.0.1:6379> xreadgroup GROUP cg1 c1 count 2 streams codehole >
1) 1) "codehole"
2) 1) 1) 1527851498956-0
2) 1) "name"
2) "xiaoqian"
3) "age"
4) "1"
2) 1) 1527852774092-0
2) 1) "name"
2) "youming"
3) "age"
4) "60"
# 再继续读取,就没有新消息了
127.0.0.1:6379> xreadgroup GROUP cg1 c1 count 1 streams codehole >
(nil)
# 阻塞等待
127.0.0.1:6379> xreadgroup GROUP cg1 c1 block 0 count 1 streams codehole >
# 开启另一个窗口,往里塞消息
127.0.0.1:6379> xadd codehole * name lanying age 61
1527854062442-0
# 回到前一个窗口,发现阻塞解除,收到新消息了
127.0.0.1:6379> xreadgroup GROUP cg1 c1 block 0 count 1 streams codehole >
1) 1) "codehole"
2) 1) 1) 1527854062442-0
2) 1) "name"
2) "lanying"
3) "age"
4) "61"
(36.54s)
# 观察消费组信息
127.0.0.1:6379> xinfo groups codehole
1) 1) name
2) "cg1"
3) consumers
4) (integer) 1 # 一个消费者
5) pending
6) (integer) 5 # 共5条正在处理的信息还有没有ack
2) 1) name
2) "cg2"
3) consumers
4) (integer) 0 # 消费组cg2没有任何变化,因为前面我们一直在操纵cg1
5) pending
6) (integer) 0
# 如果同一个消费组有多个消费者,我们可以通过xinfo consumers指令观察每个消费者的状态
127.0.0.1:6379> xinfo consumers codehole cg1 # 目前还有1个消费者
1) 1) name
2) "c1"
3) pending
4) (integer) 5 # 共5条待处理消息
5) idle
6) (integer) 418715 # 空闲了多长时间ms没有读取消息了
# 接下来我们ack一条消息
127.0.0.1:6379> xack codehole cg1 1527851486781-0
(integer) 1
127.0.0.1:6379> xinfo consumers codehole cg1
1) 1) name
2) "c1"
3) pending
4) (integer) 4 # 变成了5条
5) idle
6) (integer) 668504
# 下面ack所有消息
127.0.0.1:6379> xack codehole cg1 1527851493405-0 1527851498956-0 1527852774092-0 1527854062442-0
(integer) 4
127.0.0.1:6379> xinfo consumers codehole cg1
1) 1) name
2) "c1"
3) pending
4) (integer) 0 # pel空了
5) idle
6) (integer) 745505
|
一些问题
1:Stream 消息太多怎么办? | Stream 的上限
要是消息积累太多,Stream 的链表岂不是很长,内容会不会爆掉?。而且 xdel 指令也不会删除消息,它只是给消息做了个标志位。
Redis 自然考虑到了这一点,所以它提供了一个定长 Stream 功能。在 xadd 的指令提供一个定长长度 maxlen,就可以将老的消息干掉,确保最多不超过指定长度,使用起来也很简单:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| > XADD mystream MAXLEN 2 * value 1
1526654998691-0
> XADD mystream MAXLEN 2 * value 2
1526654999635-0
> XADD mystream MAXLEN 2 * value 3
1526655000369-0
> XLEN mystream
(integer) 2
> XRANGE mystream - +
1) 1) 1526654999635-0
2) 1) "value"
2) "2"
2) 1) 1526655000369-0
2) 1) "value"
2) "3"
|
如果使用 MAXLEN 选项,当 Stream 的达到指定长度后,老的消息会自动被淘汰掉,因此 Stream 的大小是恒定的。目前还没有选项让 Stream 只保留给定数量的条目,因为为了一致地运行,这样的命令必须在很长一段时间内阻塞以淘汰消息。_(例如在添加数据的高峰期间,你不得不长暂停来淘汰旧消息和添加新的消息)_
另外使用 MAXLEN 选项的花销是很大的,Stream 为了节省内存空间,采用了一种特殊的结构表示,而这种结构的调整是需要额外的花销的。所以我们可以使用一种带有 ~ 的特殊命令:
1
| XADD mystream MAXLEN ~ 1000 * ... entry fields here ...
|
它会基于当前的结构合理地对节点执行裁剪,来保证至少会有 1000 条数据,可能是 1010 也可能是 1030。
2:PEL 是如何避免消息丢失的?
在客户端消费者读取 Stream 消息时,Redis 服务器将消息回复给客户端的过程中,客户端突然断开了连接,消息就丢失了。但是 PEL 里已经保存了发出去的消息 ID,待客户端重新连上之后,可以再次收到 PEL 中的消息 ID 列表。
不过此时 xreadgroup 的起始消息 ID 不能为参数 > ,而必须是任意有效的消息 ID,一般将参数设为 0-0,表示读取所有的 PEL 消息以及自 last_delivered_id 之后的新消息。
Redis Stream Vs Kafka
Redis 基于内存存储,这意味着它会比基于磁盘的 Kafka 快上一些,也意味着使用 Redis 我们 不能长时间存储大量数据。
如果您想以 最小延迟 实时处理消息的话,您可以考虑 Redis,但是如果 消息很大并且应该重用数据 的话,则应该首先考虑使用 Kafka。
从某些角度来说,Redis Stream 也更适用于小型、廉价的应用程序,因为 Kafka 相对来说更难配置一些。
参考资料
- https://www.cnblogs.com/wmyskxz/p/12499532.html
- Introduction to Redis Streams【官方文档】 - https://redis.io/topics/streams-intro