05-Redis 多机之2 - 哨兵
Redis主从复制的作用有数据热备、负载均衡、故障恢复等;但主从复制存在的一个问题是故障恢复无法自动化。本文将要介绍的哨兵,它基于Redis主从复制,主要作用便是解决主节点故障恢复的自动化问题,进一步提高系统的高可用性。
1 Redis Sentinel 哨兵
在介绍哨兵之前,首先从宏观角度回顾一下Redis实现高可用相关的技术。它们包括:持久化、复制、哨兵和集群,其主要作用和解决的问题是:
- 持久化:持久化是最简单的高可用方法(有时甚至不被归为高可用的手段),主要作用是数据备份,即将数据存储在硬盘,保证数据不会因进程退出而丢失。
- 复制:复制是高可用Redis的基础,哨兵和集群都是在复制基础上实现高可用的。复制主要实现了数据的多机备份,以及对于读操作的负载均衡和简单的故障恢复。缺陷:故障恢复无法自动化;写操作无法负载均衡;存储能力受到单机的限制。
- 哨兵:在复制的基础上,哨兵实现了自动化的故障恢复。缺陷:写操作无法负载均衡;存储能力受到单机的限制。
- 集群:通过集群,Redis解决了写操作无法负载均衡,以及存储能力受到单机限制的问题,实现了较为完善的高可用方案。
下面说回哨兵。Redis Sentinel(即Redis哨兵)在Redis 2.8版本开始引入。哨兵的核心功能是主节点的自动故障转移。
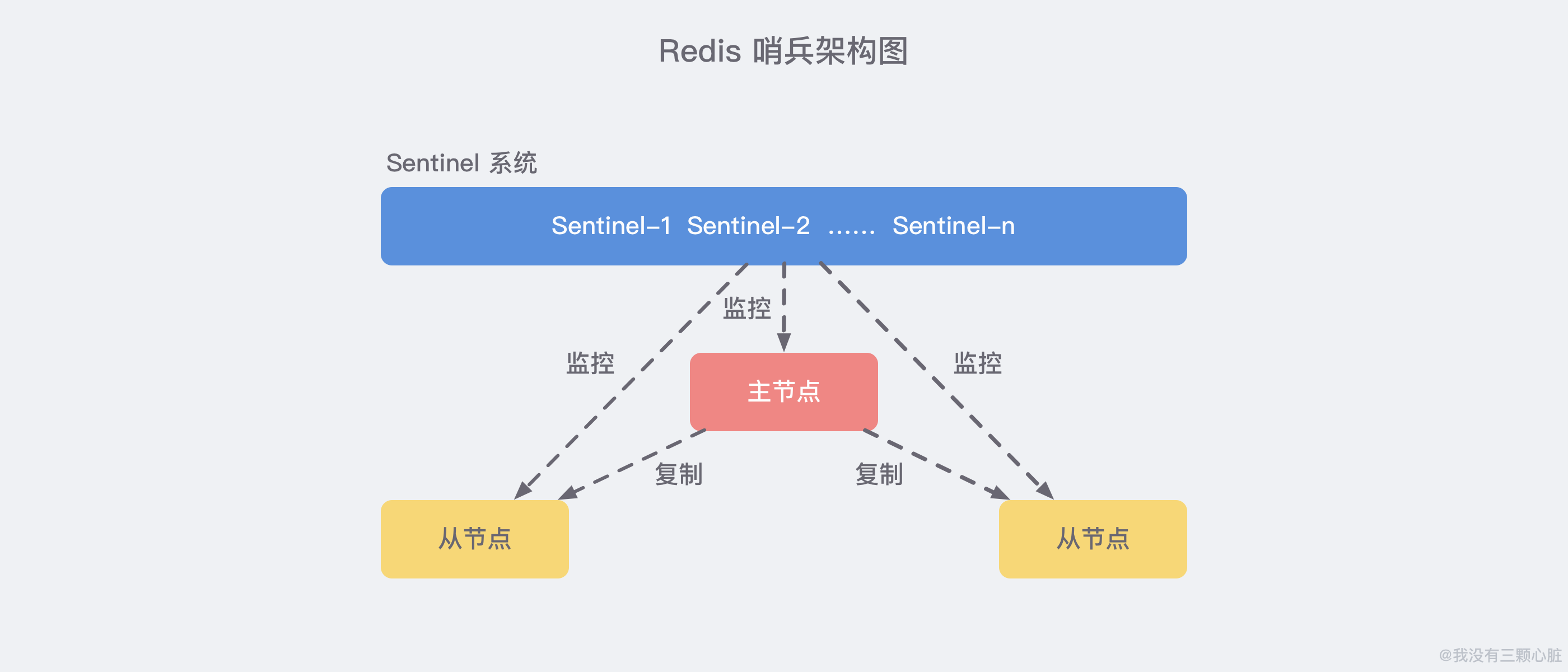
上图展示了一个典型的哨兵架构图,它由两部分组成,哨兵节点和数据节点:
- 哨兵节点: 哨兵系统由一个或多个哨兵节点组成,哨兵节点是特殊的 Redis 节点,不存储数据;
- 数据节点: 主节点和从节点都是数据节点;
在复制的基础上,哨兵实现了 自动化的故障恢复 功能,下方是官方对于哨兵功能的描述:
- 监控(Monitoring): 哨兵会不断地检查主节点和从节点是否运作正常。
- 自动故障转移(Automatic failover): 当 主节点 不能正常工作时,哨兵会开始 自动故障转移操作,它会将失效主节点的其中一个 从节点升级为新的主节点,并让其他从节点改为复制新的主节点。
- 配置提供者(Configuration provider): 客户端在初始化时,通过连接哨兵来获得当前 Redis 服务的主节点地址。
- 通知(Notification): 哨兵可以将故障转移的结果发送给客户端。
其中,监控和自动故障转移功能,使得哨兵可以及时发现主节点故障并完成转移。而配置提供者和通知功能,则需要在与客户端的交互中才能体现。
2 快速体验
我们部署一个简单的哨兵系统,包含1个主节点、2个从节点和3个哨兵节点。方便起见:所有这些节点都部署在一台机器上,使用端口号区分;节点的配置尽可能简化。
2.1 第一步:创建主从节点配置文件并启动
安装好 Redis 之后,我们去 Redis 的安装目录,找到 redis.conf 文件复制三份分别命名为 redis-master.conf/redis-slave1.conf/redis-slave2.conf,分别作为 1 个主节点和 2 个从节点的配置文件。
下面分别是主节点(port=6379)和2个从节点(port=6380/6381)的配置文件,配置都比较简单:
1 | |
然后我们执行 redis-server <config file path> 来根据配置文件启动不同的 Redis 实例,依次启动主从节点:
1 | |
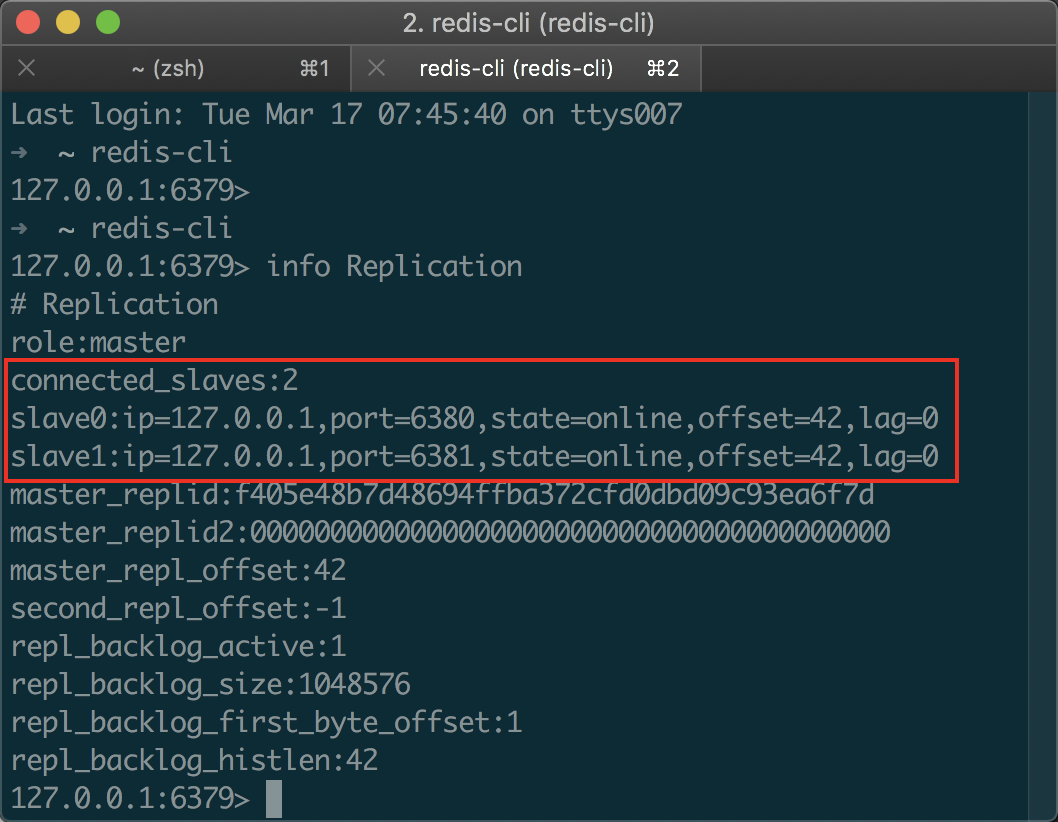
节点启动后,我们执行 redis-cli 默认连接到我们端口为 6379 的主节点执行 info Replication 检查一下主从状态是否正常:_(可以看到下方正确地显示了两个从节点)_
2.2 第二步:创建哨兵节点配置文件并启动
按照上面同样的方法,我们给哨兵节点也创建三个配置文件,主要区别在于端口号的不同(26379/26380/26381)。
哨兵节点本质上是特殊的 Redis 节点,所以配置几乎没什么差别,只是在端口上做区分
1 | |
其中,sentinel monitor mymaster 127.0.0.1 6379 2 配置的含义是:该哨兵节点监控 127.0.0.1:6379 这个主节点,该主节点的名称是 mymaster,最后的 2 的含义与主节点的故障判定有关:至少需要 2 个哨兵节点同意,才能判定主节点故障并进行故障转移。
执行下方命令将哨兵节点启动起来:
1 | |
使用 redis-cil 工具连接哨兵节点,并执行 info Sentinel 命令来查看是否已经在监视主节点了:
1 | |
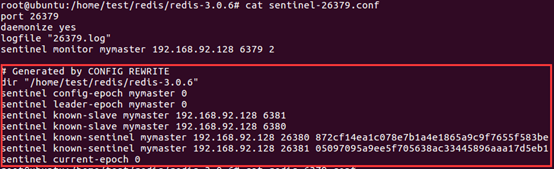
此时如果查看哨兵节点的配置文件,会发现一些变化,以26379为例:
{kind=link}
其中:
- dir只是显式声明了数据和日志所在的目录(在哨兵语境下只有日志);
- known-slave和known-sentinel显示哨兵已经发现了从节点和其他哨兵;
- 带有epoch的参数与配置纪元有关(配置纪元是一个从0开始的计数器,每进行一次领导者哨兵选举,都会+1;领导者哨兵选举是故障转移阶段的一个操作)。
2.3 第三步:演示故障转移
首先,我们使用 kill -9 命令来杀掉主节点,同时 在哨兵节点中执行 info Sentinel 命令来观察故障节点的过程:
1 | |
如果 刚杀掉瞬间 在哨兵节点中执行 info 命令来查看,会发现主节点还没有切换过来,因为哨兵发现主节点故障并转移需要一段时间:
1 | |
一段时间之后你再执行 info 命令,查看,你就会发现主节点已经切换成了 6381 端口的从节点:
1 | |
同时还可以发现,哨兵节点认为新的主节点仍然有两个从节点 _(上方 slaves=2)_,这是因为哨兵在将 6381 切换成主节点的同时,将 6379 节点置为其从节点。虽然 6379 从节点已经挂掉,但是由于 哨兵并不会对从节点进行客观下线,因此认为该从节点一直存在。当 6379 节点重新启动后,会自动变成 6381 节点的从节点。
另外,在故障转移的阶段,哨兵和主从节点的配置文件都会被改写:
- 对于主从节点: 主要是
slaveof配置的变化,新的主节点没有了slaveof配置,其从节点则slaveof新的主节点。 - 对于哨兵节点: 除了主从节点信息的变化,纪元(epoch) (记录当前集群状态的参数) 也会变化,纪元相关的参数都 +1 了。
3 客户端访问哨兵系统代码演示
上面我们感受到了服务端自己对于当前主从节点的自动化治理,下面我们以 Java 代码为例,来演示一下客户端如何访问我们的哨兵系统:
1 | |
3.1 客户端原理
Jedis 客户端对哨兵提供了很好的支持。如上述代码所示,我们只需要向 Jedis 提供哨兵节点集合和 masterName ,构造 JedisSentinelPool 对象,然后便可以像使用普通 Redis 连接池一样来使用了:通过 pool.getResource() 获取连接,执行具体的命令。
在整个过程中,我们的代码不需要显式的指定主节点的地址,就可以连接到主节点;代码中对故障转移没有任何体现,就可以在哨兵完成故障转移后自动的切换主节点。之所以可以做到这一点,是因为在 JedisSentinelPool 的构造器中,进行了相关的工作;主要包括以下两点:
- 遍历哨兵节点,获取主节点信息: 遍历哨兵节点,通过其中一个哨兵节点 +
masterName获得主节点的信息;该功能是通过调用哨兵节点的sentinel get-master-addr-by-name命令实现; - 增加对哨兵的监听: 这样当发生故障转移时,客户端便可以收到哨兵的通知,从而完成主节点的切换。具体做法是:利用 Redis 提供的 发布订阅 功能,为每一个哨兵节点开启一个单独的线程,订阅哨兵节点的 + switch-master 频道,当收到消息时,重新初始化连接池。
4 基本原理
前面介绍了哨兵部署、使用的基本方法,本部分介绍哨兵实现的基本原理。
4.1 哨兵节点支持的命令
哨兵节点作为运行在特殊模式下的redis节点,其支持的命令与普通的redis节点不同。在运维中,我们可以通过这些命令查询或修改哨兵系统;不过更重要的是,哨兵系统要实现故障发现、故障转移等各种功能,离不开哨兵节点之间的通信,而通信的很大一部分是通过哨兵节点支持的命令来实现的。
下面介绍哨兵节点支持的主要命令。
基础查询:通过这些命令,可以查询哨兵系统的拓扑结构、节点信息、配置信息等。
info sentinel:获取监控的所有主节点的基本信息sentinel masters:获取监控的所有主节点的详细信息sentinel master mymaster:获取监控的主节点mymaster的详细信息sentinel slaves mymaster:获取监控的主节点mymaster的从节点的详细信息sentinel sentinels mymaster:获取监控的主节点mymaster的哨兵节点的详细信息sentinel get-master-addr-by-name mymaster:获取监控的主节点mymaster的地址信息,前文已有介绍sentinel is-master-down-by-addr:哨兵节点之间可以通过该命令询问主节点是否下线,从而对是否客观下线做出判断
增加/移除对主节点的监控
sentinel monitor mymaster2 192.168.92.128 16379 2:与部署哨兵节点时配置文件中的sentinel monitor功能完全一样,不再详述sentinel remove mymaster2:取消当前哨兵节点对主节点mymaster2的监控
强制故障转移
sentinel failover mymaster:该命令可以强制对mymaster执行故障转移,即便当前的主节点运行完好;例如,如果当前主节点所在机器即将报废,便可以提前通过failover命令进行故障转移。
4.2 基本原理
关于哨兵的原理,关键是了解以下几个概念。
定时任务:每个哨兵节点维护了3个定时任务。
- 每隔10s,每个S节点(哨兵节点)会向主节点和从节点发送info命令获取最新的拓扑结构,并通过分析 INFO 命令的回复来获取主服务器本身的信息和主服务器所属从服务器的信息。
当 Sentinel 发现主服务器有新的从服务器出现时,Sentinel 除了会为这个新的从服务器创建相应的实例结构之外,Sentinel 还会创建连接到从服务器的命令连接和订阅连接。 - 每隔 2s,每个S节点会向某频道上发送该S节点对于主节点的判断以及当前Sl节点的信息。
同时每个S节点也会订阅该频道,来了解其他S节点以及它们对主节点的判断(做客观下线依据)。 - 每隔 1s,每个S节点会向主节点、从节点、其余S节点发送一条ping命令做一次心跳检测(心跳检测机制),来确认这些节点当前是否可达。
- 每隔10s,每个S节点(哨兵节点)会向主节点和从节点发送info命令获取最新的拓扑结构,并通过分析 INFO 命令的回复来获取主服务器本身的信息和主服务器所属从服务器的信息。
主观下线:在心跳检测的定时任务中(主要是第三个定时任务),如果其他节点超过一定时间没有回复,哨兵节点就会将其进行主观下线。
顾名思义,主观下线的意思是一个哨兵节点“主观地”判断下线。客观下线:哨兵节点在对主节点进行主观下线后,会通过
sentinel is-master-down-by-addr命令询问其他哨兵节点该主节点的状态;
如果判断主节点下线的哨兵数量达到一定数值,则对该主节点进行客观下线。
需要特别注意的是,客观下线是主节点才有的概念;如果从节点和哨兵节点发生故障,被哨兵主观下线后,不会再有后续的客观下线和故障转移操作。选举领导者哨兵节点。
当主节点被判断客观下线以后,各个哨兵节点会进行协商,选举出一个领导者哨兵节点,并由该领导者节点对其进行故障转移操作。
监视该主节点的所有哨兵都有可能被选为领导者,选举使用的算法是Raft算法;
Raft算法的基本思路是先到先得:即在一轮选举中,哨兵A向B发送成为领导者的申请,如果B没有同意过其他哨兵,则会同意A成为领导者。获得半数选票的则成为领导者。
选举的具体过程这里不做详细描述,一般来说,哨兵选择的过程很快,谁先完成客观下线,一般就能成为领导者。故障转移:选举出的领导者哨兵,开始进行故障转移操作,该操作大体可以分为3个步骤:
- 在从节点中选择新的主节点:选择的原则是,
- 首先过滤掉不健康的从节点;即那些被标记为主观下线、已断线、或者最后一次回复 PING 命令的时间大于五秒钟的从服务器都会被 过滤。
- 然后选择优先级最高的从节点(由slave-priority指定);
- 如果优先级无法区分,则选择复制偏移量最大的从节点;
- 如果复制偏移量仍无法区分,或者从服务器的复制偏移量相同,则选择runid(运行ID)最小的从节点。
- 更新主从状态:向这个从服务器发送
slaveof no one命令,将这个从服务器转换为主服务器;并通过slaveof命令让其他节点成为其从节点。 - 将已经下线的主节点(即6379)设置为新的主节点的从节点,当6379重新上线后,它会成为新的主节点的从节点。
- 在从节点中选择新的主节点:选择的原则是,
故障转移操作的第一步 要做的就是在已下线主服务器属下的所有从服务器中,挑选出一个状态良好、数据完整的从服务器,然后向这个从服务器发送 slaveof no one 命令,将这个从服务器转换为主服务器。但是这个从服务器是怎么样被挑选出来的呢?
5 配置与实践建议
5.1 配置
下面介绍与哨兵相关的几个配置。
sentinel monitor {masterName} {masterIp} {masterPort} {quorum}
sentinel monitor是哨兵最核心的配置,在前文讲述部署哨兵节点时已说明,其中:masterName指定了主节点名称,masterIp和masterPort指定了主节点地址,quorum是判断主节点客观下线的哨兵数量阈值:当判定主节点下线的哨兵数量达到quorum时,对主节点进行客观下线。
建议取值为哨兵数量的一半加1。sentinel down-after-milliseconds {masterName} {time}sentinel down-after-milliseconds与主观下线的判断有关:哨兵使用ping命令对其他节点进行心跳检测,如果其他节点超过down-after-milliseconds配置的时间没有回复,哨兵就会将其进行主观下线。该配置对主节点、从节点和哨兵节点的主观下线判定都有效。down-after-milliseconds的默认值是30000,即30s;可以根据不同的网络环境和应用要求来调整:值越大,对主观下线的判定会越宽松,好处是误判的可能性小,坏处是故障发现和故障转移的时间变长,客户端等待的时间也会变长。
例如,如果应用对可用性要求较高,则可以将值适当调小,当故障发生时尽快完成转移;如果网络环境相对较差,可以适当提高该阈值,避免频繁误判。sentinel parallel-syncs {masterName} {number}sentinel parallel-syncs与故障转移之后从节点的复制有关:它规定了每次向新的主节点发起复制操作的从节点个数。例如,假设主节点切换完成之后,有3个从节点要向新的主节点发起复制;如果parallel-syncs=1,则从节点会一个一个开始复制;如果parallel-syncs=3,则3个从节点会一起开始复制。parallel-syncs取值越大,从节点完成复制的时间越快,但是对主节点的网络负载、硬盘负载造成的压力也越大;应根据实际情况设置。
例如,如果主节点的负载较低,而从节点对服务可用的要求较高,可以适量增加parallel-syncs取值。parallel-syncs的默认值是1。sentinel failover-timeout {masterName} {time}sentinel failover-timeout与故障转移超时的判断有关,但是该参数不是用来判断整个故障转移阶段的超时,而是其几个子阶段的超时,例如如果主节点晋升从节点时间超过timeout,或从节点向新的主节点发起复制操作的时间(不包括复制数据的时间)超过timeout,都会导致故障转移超时失败。failover-timeout的默认值是180000,即180s;如果超时,则下一次该值会变为原来的2倍。
除上述几个参数外,还有一些其他参数,如安全验证相关的参数,有信心可以自己看官方文档。
5.2 实践建议
哨兵节点的数量应不止一个,一方面增加哨兵节点的冗余,避免哨兵本身成为高可用的瓶颈;另一方面减少对下线的误判。
此外,这些不同的哨兵节点应部署在不同的物理机上。哨兵节点的数量应该是奇数,便于哨兵通过投票做出“决策”:领导者选举的决策、客观下线的决策等。
各个哨兵节点的配置应一致,包括硬件、参数等;此外,所有节点都应该使用ntp或类似服务,保证时间准确、一致。
哨兵的配置提供者和通知客户端功能,需要客户端的支持才能实现,如前文所说的Jedis;如果开发者使用的库未提供相应支持,则可能需要开发者自己实现。
当哨兵系统中的节点在docker(或其他可能进行端口映射的软件)中部署时,应特别注意端口映射可能会导致哨兵系统无法正常工作,因为哨兵的工作基于与其他节点的通信,而docker的端口映射可能导致哨兵无法连接到其他节点。
例如,哨兵之间互相发现,依赖于它们对外宣称的IP和port,如果某个哨兵A部署在做了端口映射的docker中,那么其他哨兵使用A宣称的port无法连接到A。
参考资料
- https://www.cnblogs.com/wmyskxz/p/12511834.html
- 《Redis 设计与实现》 | 黄健宏 著 - http://redisbook.com/
- 深入学习Redis(4):哨兵 - https://www.cnblogs.com/kismetv/p/9609938.html