1、背景
当训练新的 ML 模型时,大多数据科学家和 ML 工程师会开发一些新的 Python 脚本或交互式 notebook,以进行数据提取和预处理,来构建用于训练模型的数据集;
然后创建几个其他脚本或 notebook 来尝试不同类型的模型或机器学习框架;
最后收集、调试指标,评估每个模型在测试数据集上的运行情况,来确定要部署到生产中的模型。
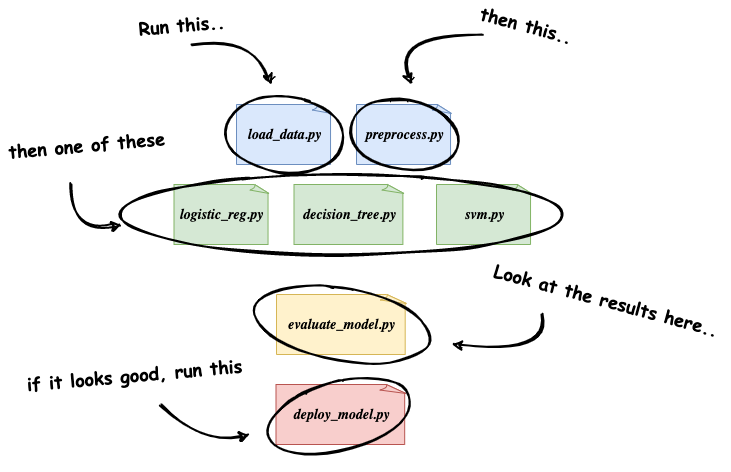
上图极大的简化了真正的机器学习工作流程,在实际开发过程中需要大量的人参与,但是除了最初开发该方法的工程师之外,其他人都无法轻易重复使用其中的内容。但是我们可以使用 KubeFlow Pipelines 来解决这些问题。
与其将数据准备、模型训练、模型验证和模型部署视为特定模型中的单一代码库,不如将其视为一系列独立的模块化步骤,让每个步骤都专注于具体任务。下图是 KubeFlow Pipelines。
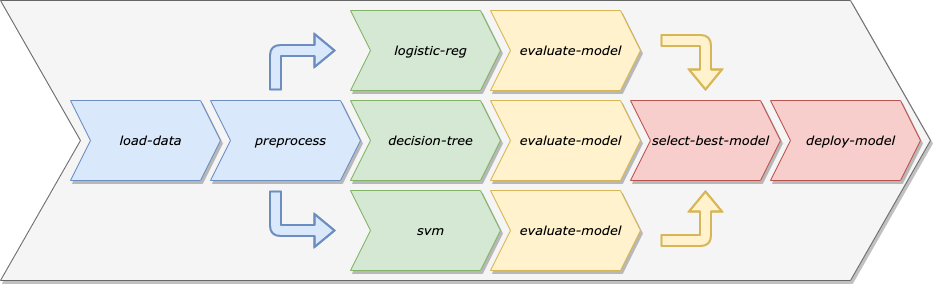
将机器学习工作流程建模为机器学习流水线有很多好处:
- 自动化:通过消除手动干预的需求,我们可以安排流水线按照需求重新训练模型,从而确保模型能够适应随时间变化的训练数据。
- 重复使用:由于流水线的步骤与流水线本身是分开的,所以我们可以轻松地在多个流水线中重复使用单个步骤。
- 重复性:任何数据科学家或工程师都可以通过手动工作流程重新运行流水线,这样就很清楚需要以什么顺序运行不同的脚本或 notebook。
- 环境解耦:通过保持机器学习流水线的步骤解耦,我们可以在不同类型的环境中运行不同的步骤。例如,某些数据准备步骤可能需要在大型计算机集群上运行,而模型部署步骤则可能在单个计算机上运行。
2、什么是 Kubeflow
Kubeflow 是一个基于 Kubernetes 的开源平台,旨在简化机器学习系统的开发和部署。Kubeflow 在官方文档中被称为 “Kubernetes 机器学习工具包”,它由几个组件(component)组成,这些组件跨越了机器学习开发生命周期的各个步骤,包括了 notebook developent environment、超参数调试、功能管理、模型服务以及 ML Pipelines。Kubeflow 中央仪表板如下图所示
3、Kubeflow Pipelines
Kubeflow 中的流水线由一个或多个组件(component)组成,它们代表流水线中的各个步骤。每个组件都在其自己的 Docker 容器中运行,这意味着流水线中的每个步骤都具有自己的一组依赖关系,与其他组件无关。
我们需要:
- 对于开发的每个组件,我们创建一个单独的 Docker 镜像,该镜像会接收输入、执行操作、输出。
- 我们要有一个单独的 Python 脚本,
pipeline.py 脚本会从每个 Docker 镜像创建 Pipelines 组件,然后使用这些组件构造流水线(Pipeline)。
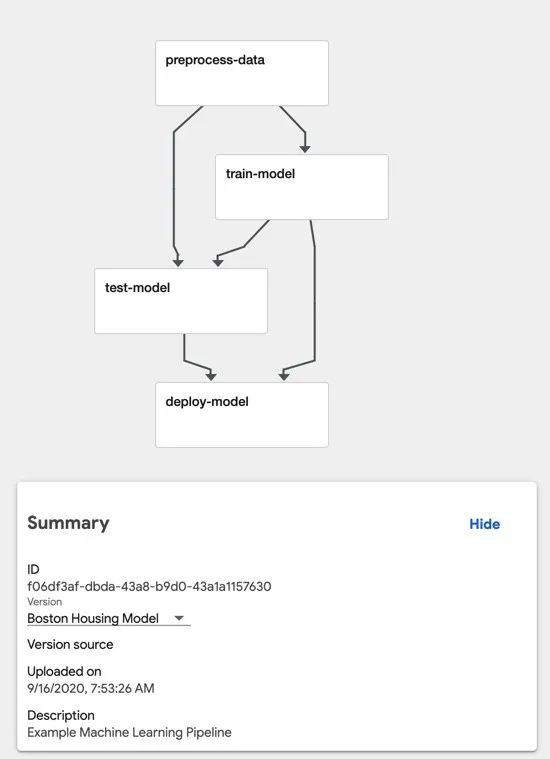
我们总共创建四个组件:
- preprocess-data:该组件将从
sklearn.datasets 中加载 Boston Housing 数据集,然后将其拆分为训练集和测试集。
- train-model:该组件将训练模型,以使用“Boston Housing”数据集来预测 Boston 房屋的中位数。
- test-model:该组件会在测试数据集上计算并输出模型的均方误差。
- deploy-model:在本文中,我们不会专注于模型的部署和服务,因此该组件将仅记录一条消息,指出它正在部署模型。实际情况下,这可能是将任何模型部署到 QA 或生产环境的通用组件。
4、环境
我们可以在任何安装了 Kubeflow 的 Kubernetes 集群上运行示例代码。本地唯一需要的依赖是 Kubeflow Pipelines SDK,使用 pip 安装:pip install kfp。
5、具体步骤
Kubeflow 示例共分以下几步。
- 制作流水线中组件所使用的镜像。
- 编写组件的脚本。
- 使用流水线接口把组件的脚本组装起来。
5.1、制作docker 镜像
preprocess-data 镜像
第一个是 preprocess-data 用到的镜像。
首先创建一个 Python 脚本,脚本作用是用 sklearn.datasets 加载 Boston Housing 数据集,用 Sci-kit Learn.train_test_split 函数将此数据集分为训练集和测试集,然后用 np.save 将数据集保存到磁盘。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
def _preprocess_data():
X, y = datasets.load_boston(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33)
np.save('x_train.npy', X_train)
np.save('x_test.npy', X_test)
np.save('y_train.npy', y_train)
np.save('y_test.npy', y_test)
if __name__ == '__main__':
print('Preprocessing data...')
_preprocess_data()
|
有了脚本之后,我们需要创建一个执行该脚本的 Docker 镜像,Dockerfile 如下:
1
2
3
4
5
| FROM python:3.7-slim
WORKDIR /app
RUN pip install -U scikit-learn numpy
COPY preprocess.py ./preprocess.py
ENTRYPOINT [ "python", "preprocess.py" ]
|
然后将镜像上传到 Kubernetes 集群可以访问的镜像仓库。
1
2
3
4
5
| # 构建镜像
docker build -t lepeng/boston_pipeline_preprocess:v1 -f Dockerfile .
# 推送镜像到远程仓库
docker push lepeng/boston_pipeline_preprocess:v1
|
train 镜像
第二个是 train 用到的镜像。
创建一个 Python 脚本,该脚本使用 Sci-kit Learn 来训练回归模型。这类似于 preprocess-data 的 Python 脚本,其中最大的区别是这里用 argparse 来接受训练数据的文件路径以作为命令行参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| # train.py
import argparse
import joblib
import numpy as np
from sklearn.linear_model import SGDRegressor
def train_model(x_train, y_train):
x_train_data = np.load(x_train)
y_train_data = np.load(y_train)
model = SGDRegressor(verbose=1)
model.fit(x_train_data, y_train_data)
joblib.dump(model, 'model.pkl')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--x_train')
parser.add_argument('--y_train')
args = parser.parse_args()
train_model(args.x_train, args.y_train)
|
创建执行该脚本的 Docker 镜像,Dockerfile 如下:
1
2
3
4
5
| FROM python:3.7-slim
WORKDIR /app
RUN pip install -U scikit-learn numpy
COPY train.py ./train.py
ENTRYPOINT [ "python", "train.py" ]
|
1
2
| docker build -t lepeng/boston_pipeline_train:v1 -f Dockerfile .
docker push lepeng/boston_pipeline_train:v1
|
test 镜像
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| import argparse
import joblib
import numpy as np
from sklearn.metrics import mean_squared_error
def test_model(x_test, y_test, model_path):
x_test_data = np.load(x_test)
y_test_data = np.load(y_test)
model = joblib.load(model_path)
y_pred = model.predict(x_test_data)
err = mean_squared_error(y_test_data, y_pred)
with open('output.txt', 'a') as f:
f.write(str(err))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--x_test')
parser.add_argument('--y_test')
parser.add_argument('--model')
args = parser.parse_args()
test_model(args.x_test, args.y_test, args.model)
|
Dockerfile 如下:
1
2
3
4
5
| FROM python:3.7-slim
WORKDIR /app
RUN pip install -U scikit-learn numpy
COPY test.py ./test.py
ENTRYPOINT [ "python", "test.py" ]
|
1
2
| docker build -t lepeng/boston_pipeline_test:v1 -f Dockerfile .
docker push lepeng/boston_pipeline_test:v1
|
deploy_model 镜像
1
2
3
4
5
6
7
8
9
10
11
12
13
|
import argparse
def deploy_model(model_path):
print(f'deploying model {model_path}...')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--model')
args = parser.parse_args()
deploy_model(args.model)
|
Dockerfile 如下:
1
2
3
4
| FROM python:3.7-slim
WORKDIR /app
COPY deploy_model.py ./deploy_model.py
ENTRYPOINT [ "python", "deploy_model.py" ]
|
1
2
| docker build -t lepeng/boston_pipeline_deploy_model:v1 -f Dockerfile .
docker push lepeng/boston_pipeline_deploy_model:v1
|
5.2、构建组件
现在开始构建流水线所需的组件。每个组件都要定义为一个返回 ContainerOp 类型的对象(object)。preprocess-data 组件定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
import kfp
from kfp import dsl
def preprocess_op():
return dsl.ContainerOp(
name='Preprocess Data',
image='wintfru/boston_pipeline_preprocess:v1',
arguments=[],
file_outputs={
'x_train': '/app/x_train.npy',
'x_test': '/app/x_test.npy',
'y_train': '/app/y_train.npy',
'y_test': '/app/y_test.npy',
}
)
def train_op(x_train, y_train):
return dsl.ContainerOp(
name='Train Model',
image='wintfru/boston_pipeline_train:v1',
arguments=[
'--x_train', x_train,
'--y_train', y_train
],
file_outputs={
'model': '/app/model.pkl'
}
)
def test_op(x_test, y_test, model):
return dsl.ContainerOp(
name='Test Model',
image='wintfru/boston_pipeline_test:v1',
arguments=[
'--x_test', x_test,
'--y_test', y_test,
'--model', model
],
file_outputs={
'mean_squared_error': '/app/output.txt'
}
)
def deploy_model_op(model):
return dsl.ContainerOp(
name='Deploy Model',
image='wintfru/boston_pipeline_deploy:v1',
arguments=[
'--model', model
]
)
|
注意:在组件中对文件路径进行硬编码不是一个很好的做法,就如上面的代码中那样,这要求创建组件定义的人员要了解有关组件实现的特定细节。这会让组件接受文件路径作为命令行参数更加干净,定义组件的人员也可以完全控制输出文件的位置。
5.3、定义流水线
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
@dsl.pipeline(
name='Boston Housing Pipeline',
description='An example pipeline that trains and logs a regression model.'
)
def boston_pipeline():
_preprocess_op = preprocess_op()
_train_op = train_op(
dsl.InputArgumentPath(_preprocess_op.outputs['x_train']),
dsl.InputArgumentPath(_preprocess_op.outputs['y_train'])
).after(_preprocess_op)
_test_op = test_op(
dsl.InputArgumentPath(_preprocess_op.outputs['x_test']),
dsl.InputArgumentPath(_preprocess_op.outputs['y_test']),
dsl.InputArgumentPath(_train_op.outputs['model'])
).after(_train_op)
deploy_model_op(
dsl.InputArgumentPath(_train_op.outputs['model'])
).after(_test_op)
if __name__ == '__main__':
client = kfp.Client()
client.create_run_from_pipeline_func(boston_pipeline, arguments={})
|
流水线由一个注解 @dsl.pipeline 修饰的 Python 函数定义。在函数内,我们可以像使用其他任何函数一样使用组件。为了运行流水线,我们创建一个 kfp.Client 对象,再调用 create_run_from_pipeline_func 函数,并传入定义流水线的函数。
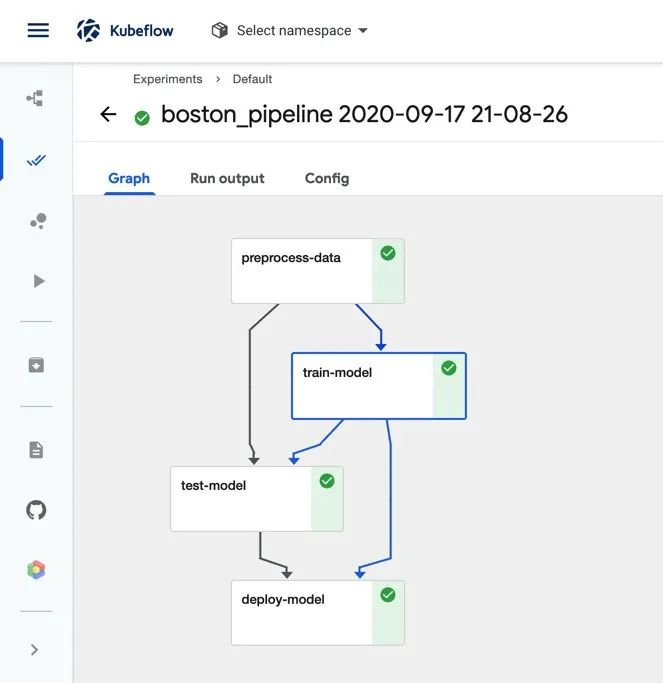
现在,如果我们执行 pipeline.py 并导航到 Kubeflow 中央仪表板中的“Pipelines UI”,我们可以看到流水线图中显示的所有四个组件。我们也可以查看每个组件的输入和输出结果以及控制台日志等。