MySQL 主从复制
主从复制的原理和步骤
简单的说:
master 将数据库的改变写入二进制日志(binlog),slave 同步这些二进制日志并重新执行一遍,这样 slave 上的数据就和 master 上的数据相同了。
详细的说:
master 启用二进制日志(binlog),记录任何修改数据库数据的事件。
当 slave 执行
start slave命令之后,slave 会开启两个线程(I/O 线程和 SQL 线程),I/O 线程用来连接 master,并请求从指定日志文件(MASTER_LOG_FILE)的指定位置(MASTER_LOG_POS)(或者从最开始的日志)之后的日志内容。
I/O 线程 与 master 建立的是长连接。当 slave 连接 master 时,master 会为 slave 启动一个线程(Binlog Dump 线程),检查自己二进制日志中的事件,根据请求信息 读取 指定日志指定位置(file,pos)之后的日志信息,返回给 slave。
如果不带请求位置参数,则 master 就会从第一个日志文件中的第一个事件开始发送给 slave。
返回信息中除了日志之外,还包括本次返回的信息的 bin-log file 的以及 bin-log position(bin-log 中的下一个指定更新位置)。slave 接收到 master 发送过来的数据把它放置到中继日志(Relay log)文件的最末端。并在 master-info 文件中记录 本次请求到 master 的二进制日志文件名和位置。以便在下一次读取。
slave SQL 线程 把中继日志(Relay log)中的事件读取出来,并在本地再执行一次。在执行的过程中,会在 relay-log-info 文件中记录当前应用中继日志的文件名和位置点。
后续当二进制日志(binlog)有变动时,Binlog Dump 线程 会通知所有的 salve 节点,并将相应的 binlog 内容推送给 slave 节点。
其原理图如下:
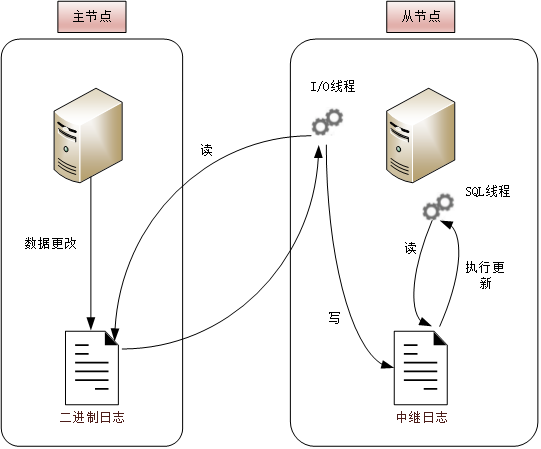
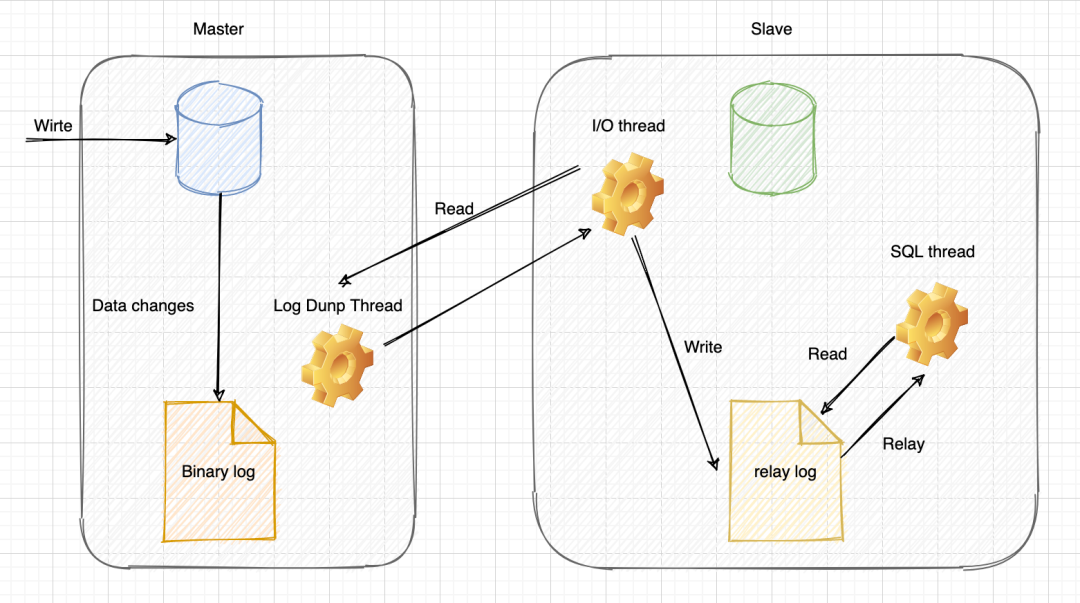
相关线程
slave:
- I/O 线程
- 当 slave 上执行 start slave 命令之后,slave 会创建一个 I/O 线程用来连接 master,请求主库中更新的 Binlog。I/O 线程接收到 master的 log dump 线程发来的更新之后,保存到本地中继日志(relay log)
- SQL 线程
- 当 slave 上执行 start slave 命令之后,slave 会创建一个SQL 线程从中继日志中读取日志事件,并在本地再执行一次。
master:
- Binlog Dump 线程
- 当 slave 连接 master 时,master 会为其创建一个 Binlog Dump 线程,用于读取和发送 Binlog 的内容。
- 当 master 有多个 slave 时,为每个 Slave 的 I/O 线程 启动一个 dump 线程。
- 在读取 Binlog 中的操作时,dump 线程会对 master 上的 Binlog 加锁;当读取完成发送给slave之前,锁会被释放。
- 如果 slave 需要作为其他节点的 master 时,是需要开启二进制日志文件的。这种情况叫做级联复制。如果只是作为 slave,则不需要创建二进制文件。
Mysql 上的 relay log 有存在的价值吗?IO 线程 和 SQL线程 需要分开吗?
MySQL 分两个线程是有必要的!因为SQL语句的执行时间很难估计,有些操作的执行时间会非常长(例如 UPDATE 全表,或者没有命中索引的修改操作),如果没有 Relay Log 而是直接由缓冲区接收,那么缓冲区很容易积压满,master 就无法继续同步数据过来,从而导致同步延时增加。所以把接收数据和执行操作两个步骤拆分开来进行解耦,尽可能让同步消息先落地到 Relay log 中是非常有必要的。
主从架构
一主一从
一主多从
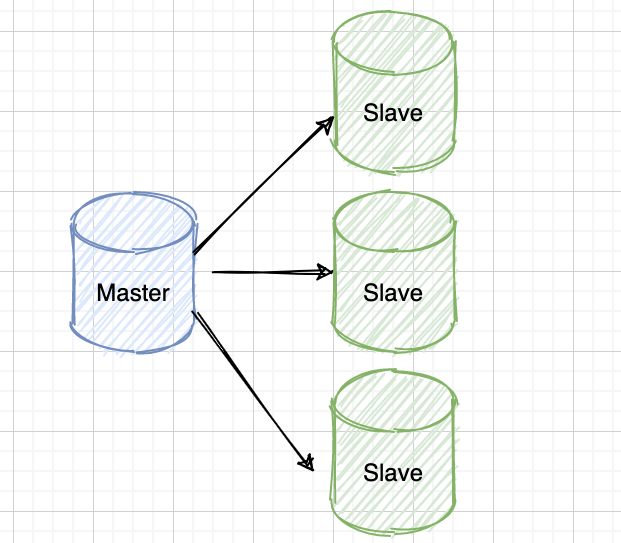
一主一从和一主多从是最常见的主从架构,使用起来简单有效,不仅可以实现 HA,而且还能读写分离,进而提升集群的并发能力。多主一从

多主一从可以将多个 MySQL 数据库备份到一台存储性能比较好的服务器上。双主复制
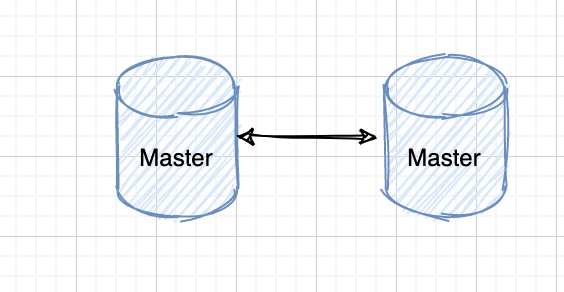
双主复制,也就是可以互做主从复制,每个 master 既是 master,又是另外一台服务器的 salve。这样任何一方所做的变更,都会通过复制应用到另外一方的数据库中。级联复制
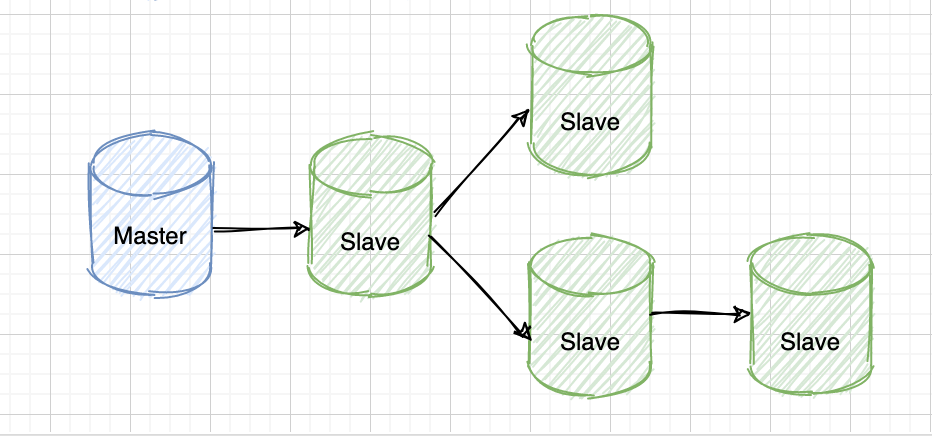
级联复制模式下,部分 slave 的数据同步不连接 master,而是连接 slave。
因为如果 master 有太多的 slave,就会损耗一部分性能用于 replication,我们可以让 3~5 个 slave 连接 master,其它 slave 作为二级或者三级与 slave 连接。这样不仅可以缓解 master 压力,并且对数据一致性没有负面影响。
级联复制解决了一主多从场景下多个从库复制对主库的压力,带来的弊端就是数据同步延迟比较大。
binlog 三种格式
STATEMENT
STATEMENT 格式 Binlog 记录的是 SQL 语句,而不是行数据。
优点:
- Binlog 文件相对较小。当更新或删除影响许多行时,这将大大减少日志文件所需的存储空间。这也意味着从备份中获取和恢复可以更快地完成。
- 日志文件包含所有变更语句,因此它们可用于审计数据库。
缺点:
- 不够精确,因为某些操作可能无法精确还原。比如使用随机函数或非确定性存储过程。
- 某些 SQL 在恢复时会,需要更多的行级锁,影响恢复效率。
1 | |
ROW
在 ROW 模式下,Binlog 记录的是实际行数据的更改。具体来说,它会记录哪些行被插入、更新或删除,以及这些行的新值。
优点:
- 复制数据非常精确,不会出现非确定函数或存储过程、存储函数、触发器的调用导致数据不一致。
- 某些类型的语句,恢复时需要更少的行锁,从而实现更高的并发性。
1 | |
缺点:
- 但生成的 Binlog 文件通常较大,比如 UPDATE 或 DELETE 操作。
- 在某些情况下可能会影响主库的性能,尤其是在大量更新操作时。
MIXED
STATEMENT 和 ROW 格式各有优缺点,MIXED 格式结合了二者的优点,在保证「数据完整性」的情况下提供最佳的「复制性能」。
MIXED 格式会根据具体情况来选择使用 ROW 记录或 STATEMENT 记录。这意味着对于某些更改,它将记录每一行数据的变化;而对于其他更改,它将记录执行的 SQL 语句。
这种模式在保持精确的同时,可以减小 Binlog 文件的大小。
从 MySQL 5.1 版本开始,MIXED 成为了默认的 binlog 格式,以兼顾 STATEMENT 和 ROW 两种格式的优点。
主从复制方式
异步复制
MySQL 主从复制默认是异步复制。
master 执行写操作后,并将变更写入 binlog,不等待 slave 应用这些变更,而是立即向客户端返回结果。
后续 master 通过 log dump 线程将 binlog 并发送给 slave。slave 把 binlog 存储到本地的 relay log 中,然后执行 relay log 的更新内容。
这个过程是异步的,所以称为异步复制。
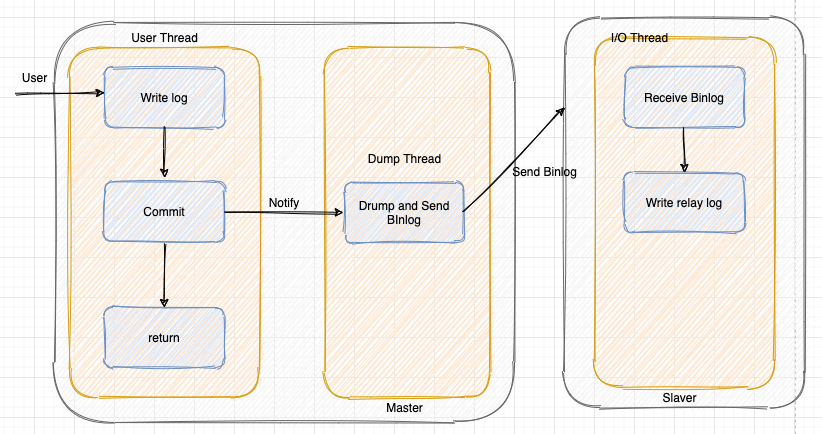
这样就会有一个问题,master 崩溃,此时 master 上已经提交的事务可能并没有传到 slave 上。如果此时强行将从提升为主,可能导致新 master 上的数据不完整。
全同步复制
当 master 执行完一个事务,然后所有的 slave 都复制了该事务的 binlog 并写到 relay log,master 才返回成功信息给客户端。
因为需要等待所有 slave 执行完该事务才能返回成功,所以全同步复制的性能必然会受到严重的影响。
半同步复制
介于异步复制和全同步复制之间,master 在执行完客户端提交的事务后不是立刻返回客户端,而是等待至少一个 slave 接收到 binlog 并写到 relay log 中才返回成功信息给客户端,保证 master 的 binlog 至少传输到了一个 slave 上。
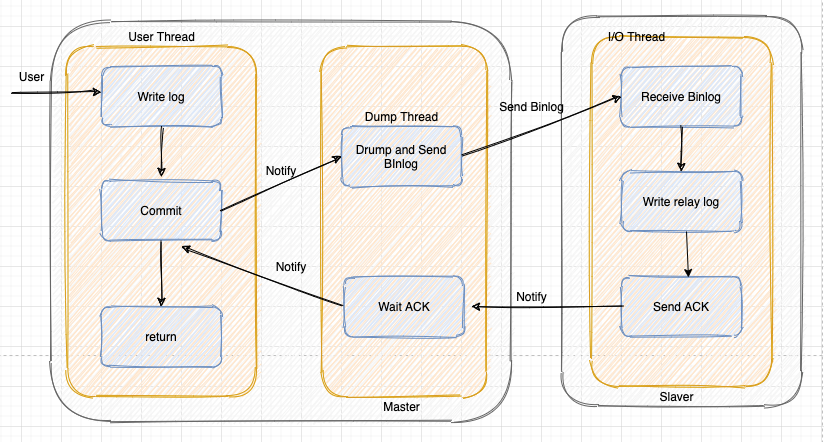
相对于异步与同步复制,半同步复制是对性能与数据一致性的权衡,保证主从最终一致。
半同步复制提高了数据的安全性,一定程度上保证了数据能成功备份到从库,同时它也造成了一定程度的延迟,但是比全同步模式延迟要低,这个延迟最少是一个 TCP/IP 往返的时间。所以,半同步复制最好在低延时的网络中使用。
半同步模式不是 MySQL 内置的,从 MySQL 5.5 开始集成,需要 master 和 slave 安装插件开启半同步模式。
配置 主从复制
确保主服务器开启二进制日志
修改主服务器上的 MySQL 配置文件(通常是
my.cnf):1
2
3
4log-bin=mysql-bin # 开启二进制日志记录
server-id=1 # 指定了主服务器的唯一标识
# binlog-do-db=DBAs # 需要同步的数据库
# binlog-ignore-db=mysql # 需要忽略的数据库设置从服务器
修改从服务器的 MySQL 配置文件中,配置如下参数:
1
2
3server-id=2 # 用于标识从服务器
relay-log=mysql-relay-bin # 用于指定从服务器中继日志的名称
log-slave-updates=1 # 用于允许从服务器记录自身的二进制日志连接主从服务器
在从服务器上,执行以下命令连接到主服务器:
1
2
3
4
5
6CHANGE MASTER TO
MASTER_HOST='master_host',
MASTER_USER='replication_user',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='mysql-bin.XXXXXX',
MASTER_LOG_POS=XXX;其中,
master_host是主服务器的地址,replication_user是用于复制的用户名,password是密码,mysql-bin.XXXXXX和XXX是主服务器当前的二进制日志文件名和位置。这些信息可以通过主服务器的SHOW MASTER STATUS;命令获取。此时从服务器的复制线程,I/O 线程 和 SQL 线程 都为 NO
启动复制
在从服务器上执行以下命令启动复制
1
START SLAVE;此时从服务器 的复制线程,I/O 线程 和 SQL 线程 都为 YES

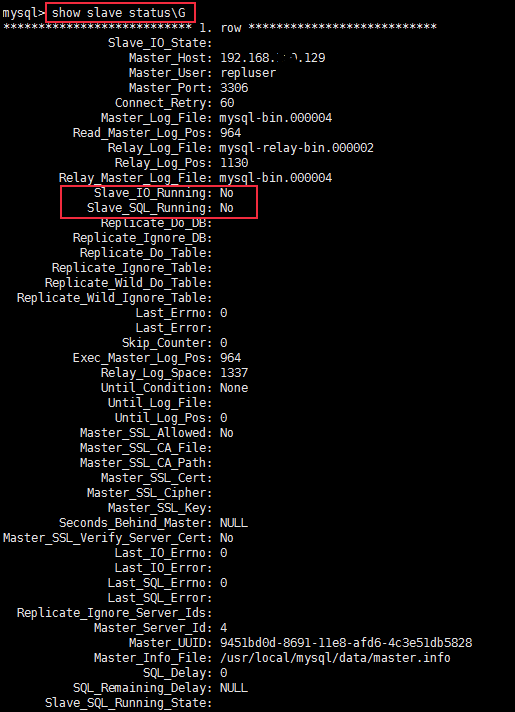
如何查看同步延迟状态
在 从服务器上通过 show slave status 查看具体的参数,有几个参数比较重要:
1 | |
主从复制问题
数据丢失
当主库宕机后,数据可能丢失。
解决方法:使用半同步复制方式,可以解决数据丢失的问题。
同步延迟
我们通过 show slave status \G; 提供的 Seconds_Behind_Master 值来衡量 MySQL 主从同步的延迟情况。
主从延迟来自两个方面:从库进行 binlog 复制,从库日志回放。
从库复制 binlog 这个主要影响是网络带宽和网络稳定性,只能提高带宽来解决,没有什么更好的方式,所以这里更多讨论从库回放日志阶段导致的主从延迟。
从库一般是单线程重放 relay log,所以如果主库写并发较大,可能导致从库单线程重放 SQL 压力较大,主从复制延迟较高。
所以优化思路就有2个,降低主库写并发和多线程重放 SQL,提高重放效率。
(1)水平分库(降低主库写并发)
水平分库后单个分库的数据量降低,单个分库的写并发降低,从而降低从库重放 SQL 的排队时延,因而降低延迟。
(2)从库并行复制
升级至 MySQL 5.7 版本使用并行复制,官方称为 Enhanced Multi-threaded Slaves,即多线程重放 SQL,提高重放效率。
读写分离问题
主从同步有延迟,这个延迟期间读从库,会读到不一致的数据。
方法一:忽略。
大觉部分业务场景对主从同步延迟不敏感,如果业务可以接受,直接忽略。方法二:放弃读写分离,强制读主。
读和写都落到主库上,在业务层面采用缓存来提升系统读性能。方法三:选择性读主。
可以利用一个缓存 key 标记那些不容许主从不一致,也就是必须读主的数据,发生了更新,且设置缓存 key 的超时时间,超时时间设置为“主从同步时延”。同步延迟期间读主,同步完成后读从。
主从复制是推还是拉?
binlog 的同步可以是 slave 向 master 拉取(pull),也可以是 master 向 slave 推送(push),应该选择哪种方式?
“推”是指 MySQL 主库在有数据更新时推送变更给从库,这种方式只有在数据有变更的时候才会发生,资源消耗少,同步及时。
“拉”是指 MySQL 从库定期询问主库是否有数据更新,这种方式频繁询问,资源消耗多,效率低且同步延迟大。
那么 MySQL 具体是怎么同步 binlog 的呢?
slave 与 master 建立连接之后,会把当前哪个 binlog 文件(MASTER_LOG_FILE)和具体偏移位置(MASTER_LOG_POS) 告诉 master。对应的,主库会启动一个 log dump 线程,根据传过来的(file,pos)在本地的 binlog 中查找,并把剩下的 binlog 发送给 slave。这个过程是 pull 模式。
当主从数据一致之后,master 收到的修改类操作,都会实时传播(propagate)给 slave,此时属于 push 模式。
所以 MySQL 主从复制是推拉结合。
相关问题: