Kafka 水位和 leader epoch
Kafka复制机制
Kafka 的主题被分为多个分区,分区是基本的数据块。分区存储在单个磁盘上,Kafka 可以保证分区里的事件是有序的,分区可以在线(可用),也可以离线(不可用)。每个分区可以有多个副本,其中一个副本是 leader 副本。所有的生产者请求和消费者请求都经过 leader 副本,leader 副本以外的副本都是 follower 副本,follower 副本不处理来自客户端的请求,它们唯一的任务就是从 leader 副本那里复制消息,保持与 leader 副本一致的状态。如果 leader 副本发生崩溃,其中的一个 follower 副本会被提升为新的 leader 副本。
当然,由于网络问题、broker 崩溃等导致 follower 副本复制滞后,这时它肯定不能成为新的 leade r副本。那么符合哪些条件的 follower 副本才可以成为leader副本呢?答案是“同步副本”,同步副本是满足如下条件的副本:
- leader 副本是同步副本
- 与 zookeeper 之间有一个活跃的会话,也即在过去6S(可配置)内向zookeeper发送过心跳。
- 在过去的 10S 内(可配置)从 leader 副本那里获得过信息。
- 在过去 10S 内从 leader 副本那里获取过最新的信息。(光从 leader 那里获取信息是不够的,还必须是几乎零延迟的)
leader 会跟踪与其保持同步的副本列表,该列表称为ISR(即in-sync Replica)。如果一个 follower 宕机,或者落后太多,leader 将把它从 ISR 中移除。这里所描述的“落后太多”指 Follower 复制的消息落后于 Leader 后的条数超过预定值(该值可在 server.properties 中通过 replica.lag.max.messages 配置,其默认值是 4000)或者 Follower 超过一定时间(该值可在 server.properties 中通过 replica.lag.time.max.ms 来配置,其默认值是 10000)未向 Leader 发送 fetch 请求。
举例说明:
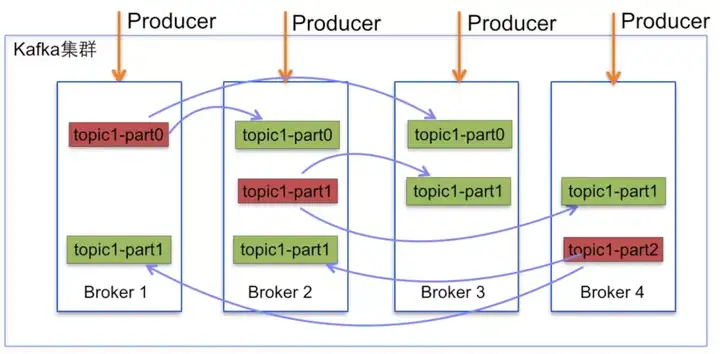
上图的Kafka集群,有个topic1的主题,有3个分区,每个分区副本为3。其中红色的是leader副本,绿色的是follower副本。这里涉及到副本分配算法,如下:
- 将所有 N Broker 和待分配的 i 个 Partition 排序.
- 将第 i 个 Partition 分配到第 (i mod n) 个 Broker 上.
- 将第 i 个 Partition 的第 j 个副本分配到第 ((i + j) mod n) 个 Broker 上.
在本例中 N=4,i=0,1,2。可以看到符合副本分配算法。
Kafka 的 LEO 和 HW
Kafka 所有副本都有的两个重要属性:LEO 和 HW。
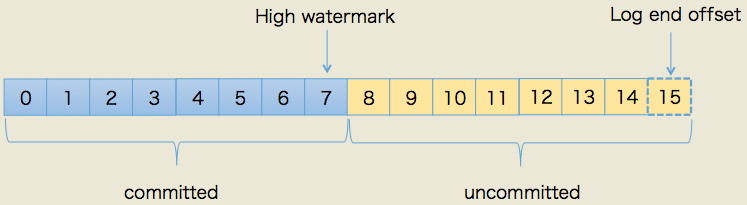
- LEO:即日志末端位移(log end offset),记录了该副本底层日志(log)中下一条消息的位移值。注意是下一条消息!也就是说,如果 LEO=10,那么表示该副本保存了 10 条消息,位移值范围是
[0, 9]。 - High Watermark(高水位线)以下简称 HW,表示消息被 leader 和 ISR 内的 follower 都确认 commit 写入本地 log,所以在 HW 位置以下的消息都可以被消费(不会丢失)。
举个例子,正常情况下,如下图:
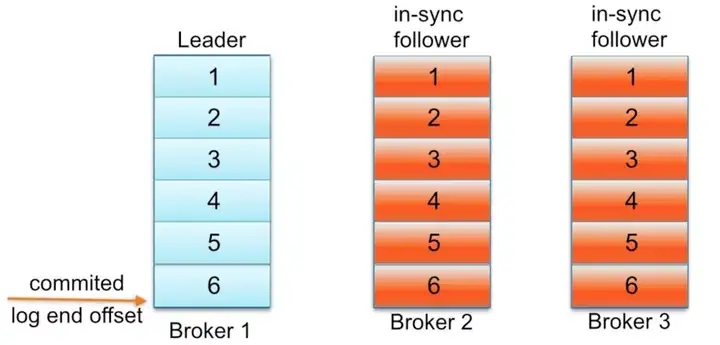
当 follower 可能由于 IO 耗时过高,经历了一次 full gc 耗时很多时,达到了不满足同步副本的条件,follower 被移除了 ISR 列表。此时的 HW 还是6,leader 上的 LEO 是 10。消费者只能消费 offset 到 6。 等待 broker 回复正常,又加入 ISR 列表。所以 ISR 列表是动态的。维护好 ISR 列表,就能保证 leader 不可用时,可以从 ISR 中选一个 replication 作为 leader 继续工作。
高水位的问题
0.11 版本之前,0.11 之前副本备份机制主要依赖水位(或水印)的概念,而 0.11 采用了leader epoch来标识备份进度。
首先说一下 Kafka 0.11 之前的复制协议:
Kafka 复制协议有两个阶段,第一阶段,follower 从 leader 获取到消息;第二阶段,在下一轮的 RPC 中向 leader 发送 fetch request 确认收到消息。假设其他的 follower 也都确认了,那么 leader 会更新 HW,并在接下来的 RPC 中响应给 follower。
由于 Kafka 的复制协议分两个阶段,导致使用高水位会出现数据丢失和数据不一致的问题,下面我们分别讲一下这两种问题:
数据丢失【Scenario 1: High Watermark Truncation followed by Immediate Leader Election】
假设有 A、B 两个 Broker,初始时 B 为leader,A 从 B 中取到消息 m2,所以 A 中有消息 m2 了,但是由于在下一轮 RPC 中,A 才会更新自己的 HW,所以此时 A 的 HW 没变。如果这时候 A 重启了,他截取自己的日志到 HW 并发送一个 fetch request 到 B。不幸的是,B 这时宕机了,A 成了新的 leader,那么此时消息 m2 就会永久的丢失了。
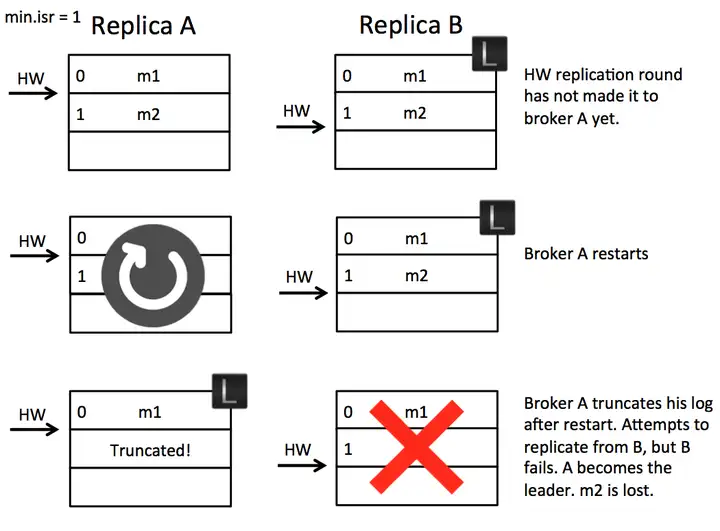
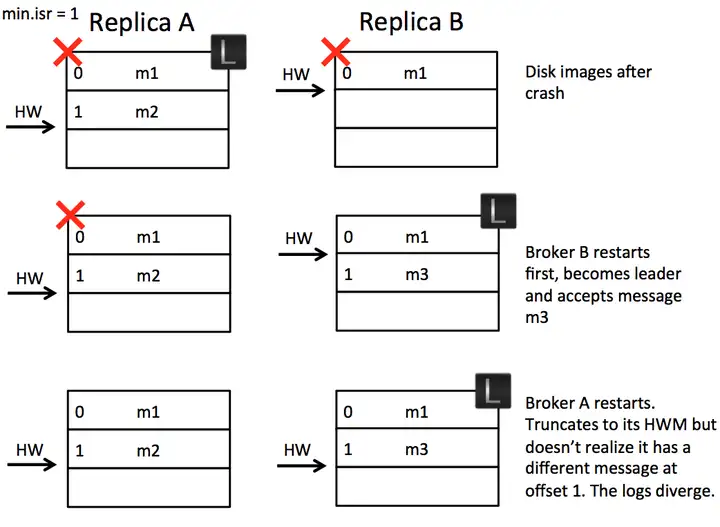
数据不一致:【Scenario 2: Replica Divergence on Restart after Multiple Hard Failures】
假设我们有两个 Broker,初始时 A 是 leader,B 是 follower。A 接收到 m2 消息,但 B 还没来得及复制时,断电了。过了一会,B 重启了,成为了leader,接收了 m3 消息,HW+1。然后 A 重启了,截断日志到高水位,但是此时的消息却出现了不一致。
leader epoch
在 0.11 版本使用 leader epoch 解决这两个问题。
- Leader Epoch: 32 位,单调递增的数字。代表单个分区所处的 leader 时代。每发生一次 leader 转换,就+1。例如 leader epoch =2,说明处于第二 leader 时代。
- Leader Epoch Start Offset: 该 epoch 版本的 leader 写入第一条消息的位移。
- Leader Epoch Sequence File: 存储 Leader Epoch 和 Leader Epoch Start Offset 对,类似如下形式:0,100 1,200 3,500
我们说一下 Leader epoch 的工作步骤,然后在分析上面两个例子。
使每个消息都包含一个4字节的 Leader Epoch number
每个 log 目录,创建 Leader Epoch Sequence file 用来存储 Leader Epoch 和 Start Offset。
当一个副本成为 leader,它首先在 Leader Epoch Sequence file 末尾添加一条新的记录,并把他 flush 到磁盘。每条新的消息就会被新的 Leader Epoch 标记。
当一个副本成为 follower 时(比如重启),它会做以下事情:
从 Leader Epoch Sequence file 恢复所有的 Leader Epoch。我的理解是,比如宕机太久,这期间换了好几次 leader,那么就要把这些 leader 时代的消息都恢复过来。
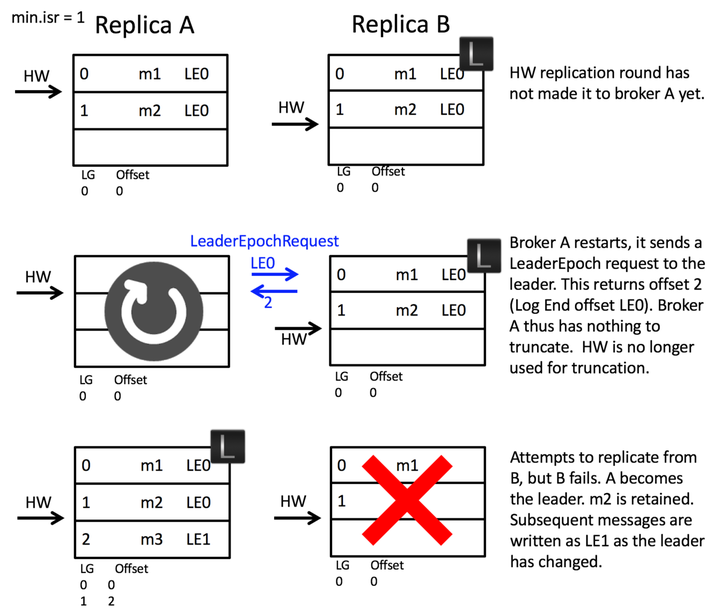
向分区 leader 发送一个 LeaderEpoch 请求,请求包含了该 follower 的 Leader Epoch Sequence 文件中最新的 Leader Epoch。
Leader 向 follower 返回对应 LeaderEpoch 的 LastOffset。这个 LastOffset 有两种可能,一种是比 follower 发送的请求中的 Leader Epoch 大 1 的开始 offset,另一种是如果当前 leader epoch 与请求中的 leader epoch 相等,那么就返回当前 leader 的 LEO。
如果当前 follower 有任何 LeaderEpoch 的开始偏移量大于从 leader 中返回的 LastOffset 。那么他会重置 Leader Epoch Sequence 来和 leader 保持一直。
follower 截断 local log 到 leader 的 LastOffset 位置。
follower 开始从 leader获取数据
在获取数据时,如果 follower 发现消息中的 LeaderEpoch 比自己的最新的 LeaderEpoch 大,他会添加这个 LeaderEpoch 和开始偏移到LeaderEpochSequence 文件,并刷写到磁盘。然后 follower 继续获取数据。
我们用 leader epoch 的方式分析一下上面两个例子。
解决数据丢失:A 重启后,向 B 发送 LeaderEpochRequest 请求,此时由于 Leader Epoch 相等,所以 B 返回给 A 的是 B 的 LEO。此时 B 挂掉,A 接收到 LEO=2,与自己相同,所以不会截断,A 成为 leader,在文件中添加新的 Leader epoch 和开始偏移即可。
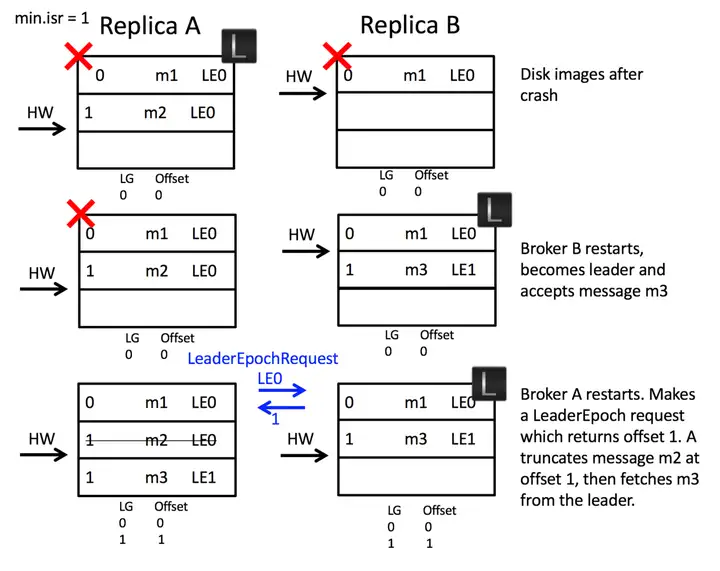
解决数据不一致问题: A、B 宕机后,B 先重启成为 leader,此时 Leader Epoch 由 0 变为 1,并且 LE 的开始偏移为 1。此时 A 重启,向 B 发送自己宕机时所处的 Leader Epoch,也就是 0。此时 B 返回 LE1 的开始偏移 1。A 发现自己的数据大于此值,便会截断自己的日志。从而保证数据的一致性。
相关配置
生产者端 生产者生产消息的时候,通过request.required.acks 参数来设置数据的可靠性。
request.required.acks=0 发过去就完事了,不关心broker是否处理成功,可能丢数据。
request.required.acks=1 当写Leader成功后就返回,其他的replica都是通过fetch去同步的,所以kafka是异步写,主备切换可能丢数据。
request.required.acks=-1 要等到ISR里所有机器同步成功,才能返回成功,延时取决于最慢的机器。强一致,不会丢数据。
Broker级别的配置 min.insync.replicas指定最少的ISR副本数量。