Flink 历史服务器
Flink 官网主页地址:https://flink.apache.org
Flink 官方中文地址:https://nightlies.apache.org/flink/flink-docs-stable/zh/
历史服务器
运行 Flink job 的集群一旦停止,只能去 yarn 或本地磁盘上查看日志,不再可以查看作业挂掉之前的运行的 Web UI,很难清楚知道作业在挂的那一刻到底发生了什么。如果我们还没有 Metrics 监控的话,那么完全就只能通过日志去分析和定位问题了,所以如果能还原之前的 Web UI,我们可以通过 UI 发现和定位一些问题。
Flink 提供了历史服务器,用来在相应的 Flink 集群关闭后查询已完成作业的统计信息。我们都知道只有当作业处于运行中的状态,才能够查看到相关的 WebUI 统计信息。通过 History Server 我们才能查询这些已完成作业的统计信息,无论是正常退出还是异常退出。
此外,它对外提供了 REST API,它接受 HTTP 请求并使用 JSON 数据进行响应。Flink 任务停止后,JobManager 会将已经完成任务的统计信息进行存档,History Server 进程则在任务停止后可以对任务统计信息进行查询。比如:最后一次的 Checkpoint、任务运行时的相关配置。
创建存储目录
1
hadoop fs -mkdir -p /logs/flink-job在
flink-config-yaml中添加如下配置1
2
3
4
5jobmanager.archive.fs.dir: hdfs://hadoop102:8020/logs/flink-job
historyserver.web.address: hadoop102
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://hadoop102:8020/logs/flink-job
historyserver.archive.fs.refresh-interval: 5000启动历史服务器
1
bin/historyserver.sh start停止历史服务器
1
bin/historyserver.sh stop在浏览器地址栏输入:http://hadoop102:8082 查看已经停止的 job 的统计信息
4、Flink运行时架构
4.1、系统架构
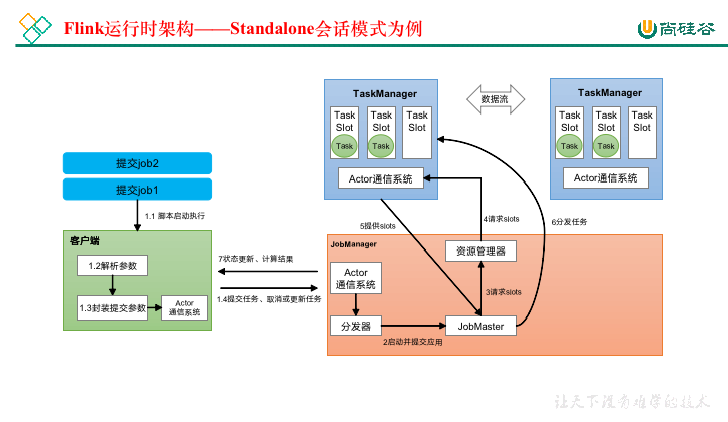
- 作业管理器(JobManager)
JobManager是一个Flink集群中任务管理和调度的核心,是控制应用执行的主进程。也就是说,每个应用都应该被唯一的JobManager所控制执行。
JobManger又包含3个不同的组件。
1. JobMaster
JobMaster是JobManager中最核心的组件,**负责处理单独的作业(Job)**。所以JobMaster和具体的Job是一一对应的,多个Job可以同时运行在一个Flink集群中, 每个Job都有一个自己的JobMaster。需要注意在早期版本的Flink中,没有JobMaster的概念;而JobManager的概念范围较小,实际指的就是现在所说的JobMaster。
在作业提交时,JobMaster会先接收到要执行的应用。JobMaster会把JobGraph转换成一个物理层面的数据流图,这个图被叫作“执行图”(ExecutionGraph),它包含了所有可以并发执行的任务。JobMaster会向资源管理器(ResourceManager)发出请求,申请执行任务必要的资源。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的TaskManager上。
而在运行过程中,JobMaster会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调。
2. 资源管理器(Resource Manager)
ResourceManager主要**负责资源的分配和管理**,在Flink 集群中只有一个。所谓“资源”,主要是指TaskManager的任务槽(task slots)。任务槽就是Flink集群中的资源调配单元,包含了机器用来执行计算的一组CPU和内存资源。每一个任务(Task)都需要分配到一个slot上执行。
这里注意要把Flink内置的ResourceManager和其他资源管理平台(比如YARN)的ResourceManager区分开。
3. 分发器(Dispatcher)
Dispatcher主要负责提供一个REST接口,**用来提交应用,并且负责为每一个新提交的作业启动一个新的JobMaster 组件**。Dispatcher也会启动一个Web UI,用来方便地展示和监控作业执行的信息。Dispatcher在架构中并不是必需的,在不同的部署模式下可能会被忽略掉。
- 任务管理器(TaskManager)
TaskManager是Flink中的工作进程,数据流的具体计算就是它来做的。Flink集群中必须至少有一个TaskManager;每一个TaskManager都包含了一定数量的任务槽(task slots)。Slot是资源调度的最小单位,slot的数量限制了TaskManager能够并行处理的任务数量。
启动之后,TaskManager会向资源管理器注册它的slots;收到资源管理器的指令后,TaskManager就会将一个或者多个槽位提供给JobMaster调用,JobMaster就可以分配任务来执行了。
在执行过程中,TaskManager可以缓冲数据,还可以跟其他运行同一应用的TaskManager交换数据。
4.2、核心概念
4.2.1、并行度(Parallelism)
- 并行子任务和并行度
当要处理的数据量非常大时,我们可以把一个算子操作,“复制”多份到多个节点,数据来了之后就可以到其中任意一个执行。这样一来,一个算子任务就被拆分成了多个并行的“子任务”(subtasks),再将它们分发到不同节点,就真正实现了并行计算。
在Flink执行过程中,每一个算子(operator)可以包含一个或多个子任务(operator subtask),这些子任务在不同的线程、不同的物理机或不同的容器中完全独立地执行。

一个特定算子的子任务(subtask)的个数被称之为其并行度(parallelism)。这样,包含并行子任务的数据流,就是并行数据流,它需要多个分区(stream partition)来分配并行任务。一般情况下,一个流程序的并行度,可以认为就是其所有算子中最大的并行度。一个程序中,不同的算子可能具有不同的并行度。
例如:如上图所示,当前数据流中有source、map、window、sink四个算子,其中sink算子的并行度为1,其他算子的并行度都为2。所以这段流处理程序的并行度就是2。
- 并行度的设置
在Flink中,可以用不同的方法来设置并行度,它们的有效范围和优先级别也是不同的。
1. 代码中设置
我们在代码中,可以很简单地在算子后跟着调用setParallelism()方法,来设置当前算子的并行度:
1
stream.map(word -> Tuple2.of(word, 1L)).setParallelism(2);
这种方式设置的并行度,只针对当前算子有效。
另外,我们也可以直接调用执行环境的setParallelism()方法,全局设定并行度:
1
env.setParallelism(2);
这样代码中所有算子,默认的并行度就都为2了。我们一般不会在程序中设置全局并行度,因为如果在程序中对全局并行度进行硬编码,会导致无法动态扩容。
这里要注意的是,由于keyBy不是算子,所以无法对keyBy设置并行度。
2. 提交应用时设置
在使用flink run命令提交应用时,可以增加-p参数来指定当前应用程序执行的并行度,它的作用类似于执行环境的全局设置:
1
2
bin/flink run –p 2 –c com.lepeng.wc.SocketStreamWordCount
./FlinkTutorial-1.0-SNAPSHOT.jar
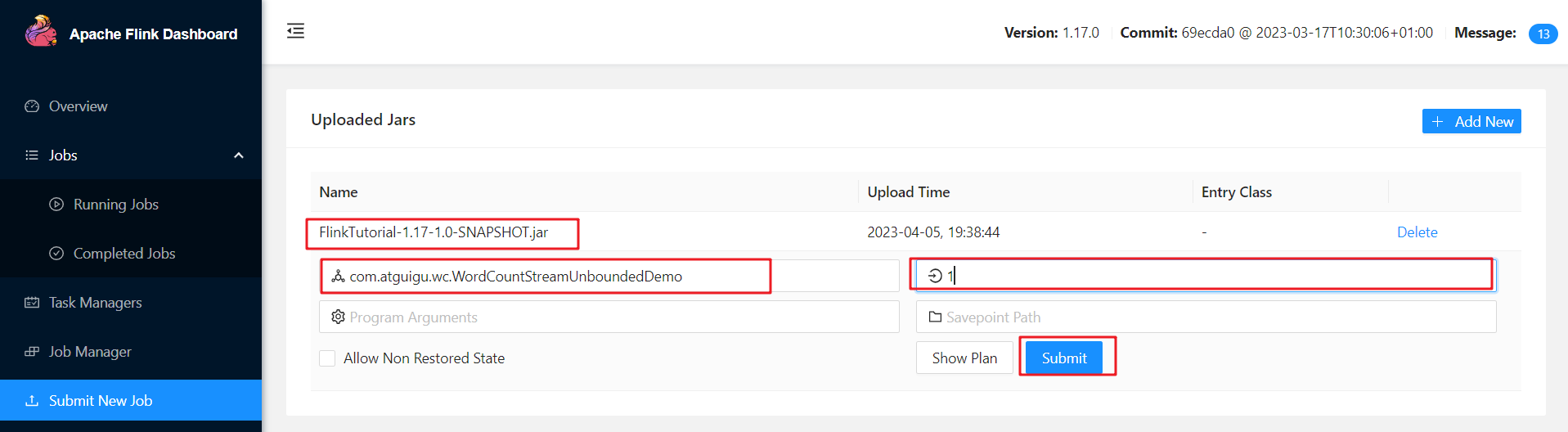
如果我们直接在Web UI上提交作业,也可以在对应输入框中直接添加并行度。
3. 配置文件中设置
我们还可以直接在集群的配置文件flink-conf.yaml中直接更改默认并行度:
1
parallelism.default: 2
这个设置对于整个集群上提交的所有作业有效,初始值为1。无论在代码中设置、还是提交时的-p参数,都不是必须的;所以在没有指定并行度的时候,就会采用配置文件中的集群默认并行度。在开发环境中,没有配置文件,默认并行度就是当前机器的CPU核心数。