03-Flink 算子链(Operator Chain)
Flink 官网主页地址:https://flink.apache.org
Flink 官方中文地址:https://nightlies.apache.org/flink/flink-docs-stable/zh/
算子链(Operator Chain)
1、算子间的数据传输
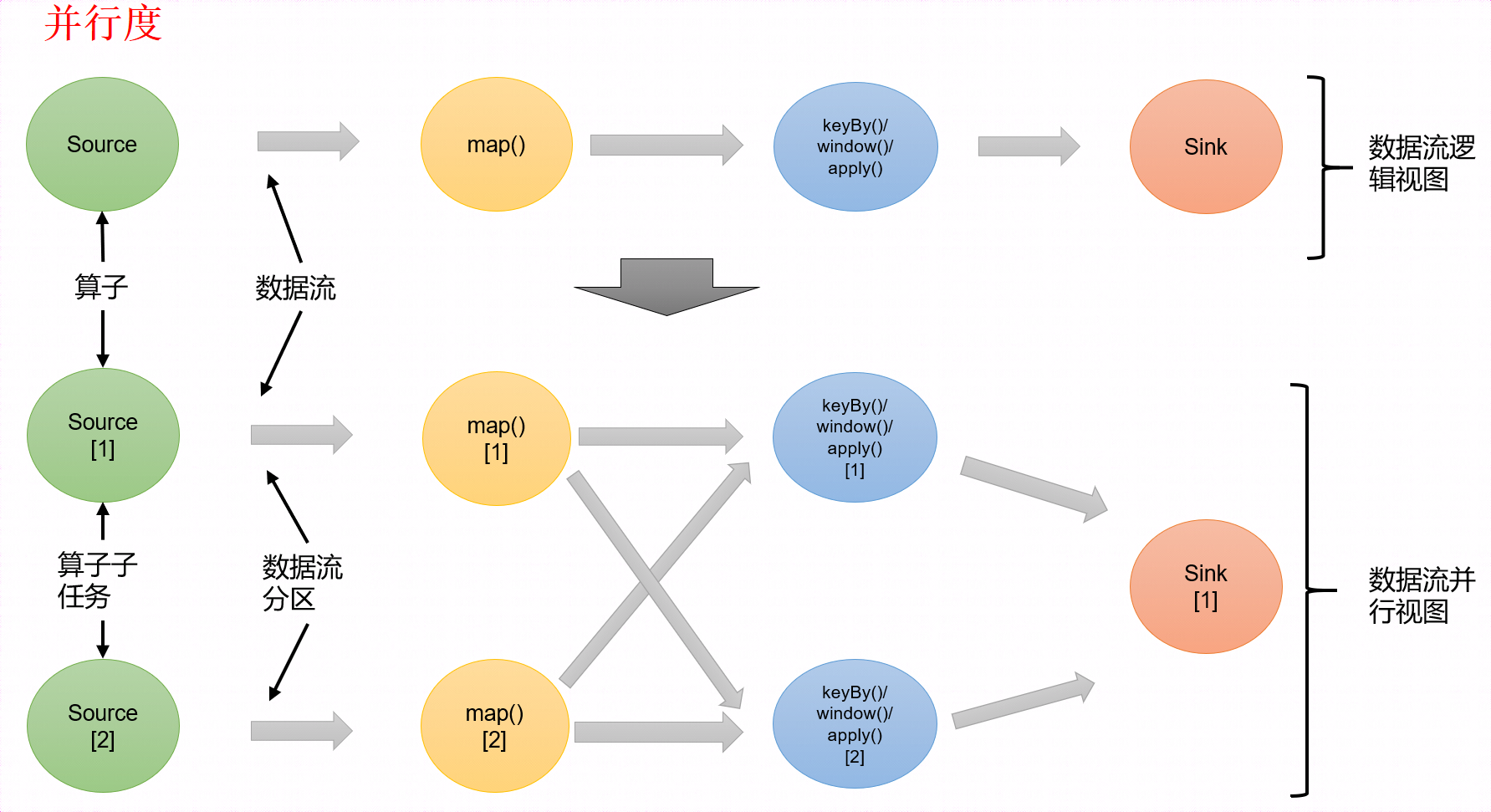
一个数据流在算子之间传输数据的形式可以是一对一(one-to-one)的直通 (forwarding)模式,也可以是打乱的重分区(redistributing)模式,具体是哪一种形式,取决于算子的种类。
2、一对一(One-to-one, forwarding)
这种关系类似于 Spark 中的窄依赖。
这种模式下,数据流维护着分区以及元素的顺序。
比如图中的 source 和 map 算子,source 算子读取数据之后,可以直接发送给 map 算子做处理,它们之间不需要重新分区,也不需要调整数据的顺序。这就意味着 map 算子的子任务,看到的元素个数和顺序跟 source 算子的子任务产生的完全一样,保证着“一对一”的关系。map、 filter、 flatMap 等算子都是这种 one-to-one 的对应关系。
3、重分区(Redistributing)
这种算子间的关系类似于 Spark 中的宽依赖。
在这种模式下,数据流的分区会发生改变。比图中的 map 和后面的 keyBy/window 算子之间(这里的 keyBy 是数据传输算子,后面的 window、apply 方法共同构成了 window 算子),以及 keyBy/window 算子和 Sink 算子之间,都是这样的关系。
每一个算子的子任务,会根据数据传输的策略,把数据发送到不同的下游目标任务。例如,keyBy 是分组操作,本质上基于键(key)的哈希值(hashCode)进行了重分区;而当并行度改变时,比如从并行度为 2 的 window 算子,要传递到并行度为 1 的 Sink 算子,这时的数据传输方式是再平衡(rebalance),会把数据均匀地向下游子任务分发出去。这些传输方式都会引起重分区(redistribute)的过程,这一过程类似于 Spark 中的 shuffle。
4、合并算子链
在 Flink 中,并行度相同的一对一(one to one)算子操作,可以直接链接在一起形成一个 “大”的任务(task),这样原来的算子就成为了真正任务里的一部分,如图所示。每个 task 会被一个线程执行。这样的技术被称为 “算子链”(Operator Chain)。
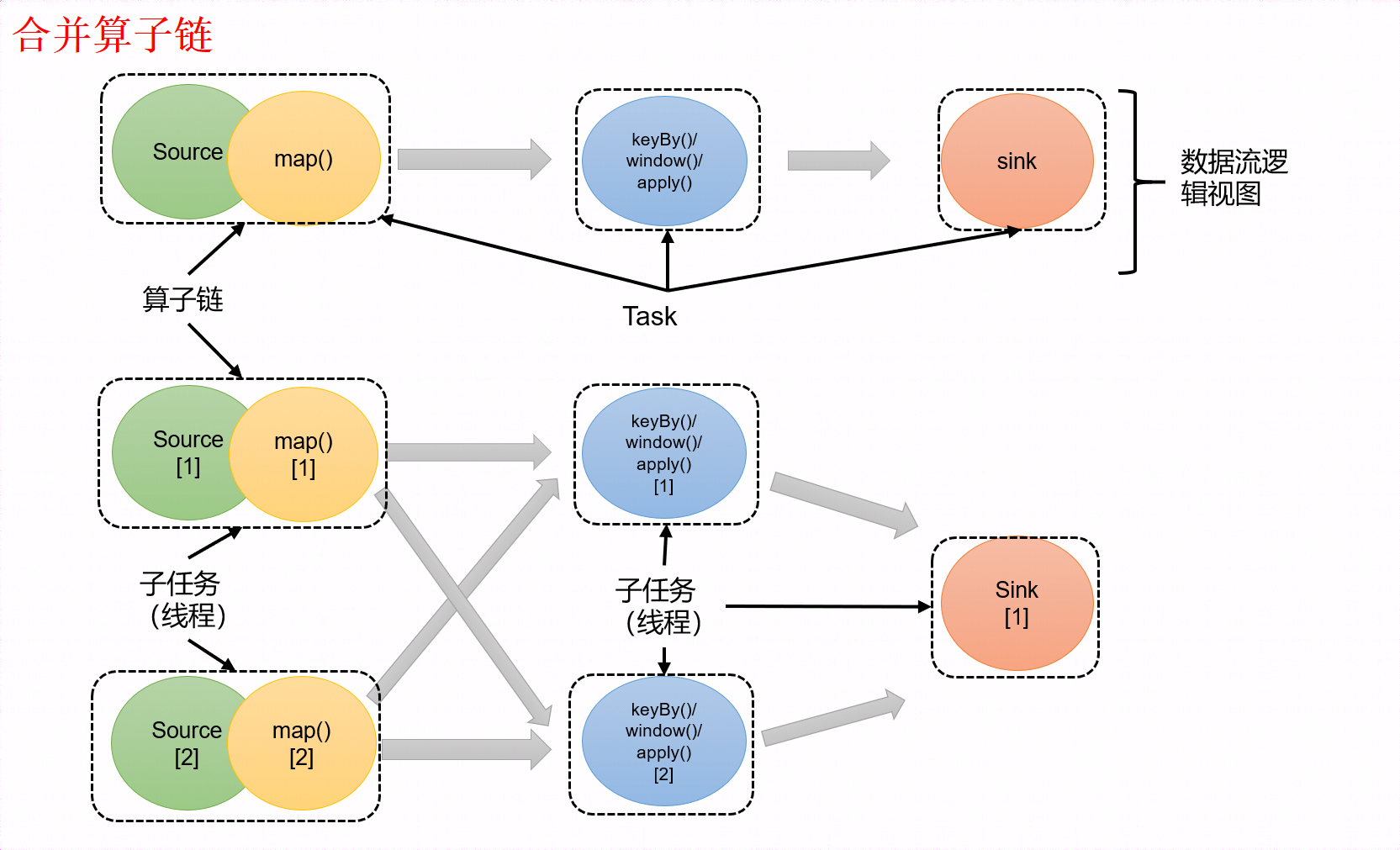
比如在上图中的例子中,Source 和 map 之间满足了算子链的要求,所以可以直接合并在一起,形成了一个任务;因为并行度为 2,所以合并后的任务也有两个并行子任务。这样,这个数据流图所表示的作业最终会有 5 个任务,由 5 个线程并行执行。
Flink 为什么要有算子链这样一个设计呢?这是因为将算子链接成 task 是非常有效的优化:可以减少线程之间的切换和基于缓存区的数据交换,在减少时延的同时提升吞吐量。
Flink 默认会按照算子链的原则进行链接合并,如果我们想要禁止合并或者自行定义,也可以在代码中对算子做一些特定的设置:
1 | |