07-Flink 中的时间和窗口
Flink 官网主页地址:https://flink.apache.org
Flink 官方中文地址:https://nightlies.apache.org/flink/flink-docs-stable/zh/
在批处理统计中,我们可以等待一批数据都到齐后,统一处理。但是在实时处理统计中,我们是来一条就得处理一条,那么我们怎么统计最近一段时间内的数据呢?引入“窗口”。
所谓的“窗口”,一般就是划定的一段时间范围,也就是“时间窗”;对在这范围内的数据进行处理,就是所谓的窗口计算。所以窗口和时间往往是分不开的。接下来我们就深入了解一下中的时间语义和窗口的应用。
1、窗口(Window)的概念
Flink 是一种流式计算引擎,主要是来处理无界数据流的,数据源源不断、无穷无尽。想要更加方便高效地处理无界流,一种方式就是将无限数据切割成有限的“数据块”进行处理,这就是所谓的“窗口”(Window)。
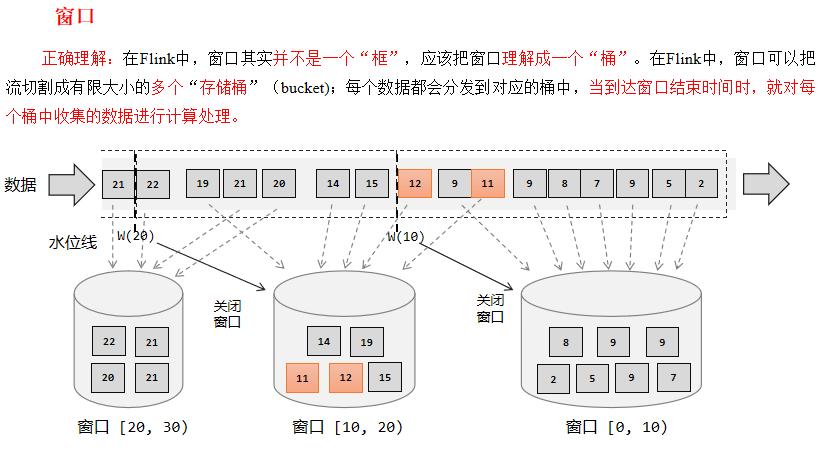
注意:Flink 中窗口并不是静态准备好的,而是动态创建——当有落在这个窗口区间范围的数据达到时,才创建对应的窗口。另外,这里我们认为到达窗口结束时间时,窗口就触发计算并关闭,事实上“触发计算”和“窗口关闭”两个行为也可以分开。
2、窗口的分类
在 Flink 中,窗口的应用非常灵活,我们可以使用各种不同类型的窗口来实现需求。接下来我们就从不同的角度,对 Flink 中内置的窗口做一个分类说明。
2.1、按照驱动类型分类
窗口本身是截取有界数据的一种方式,所以窗口一个非常重要的信息其实就是“怎样截取数据”。换句话说,就是以什么标准来开始和结束数据的截取,我们把它叫作窗口的“驱动类型”。
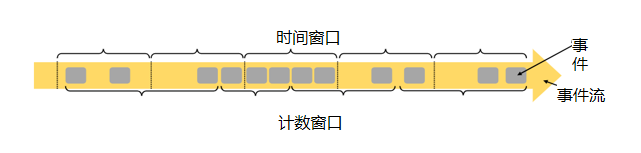
时间窗口(Time Window)
时间窗口以时间点来定义窗口的开始(start)和结束(end),所以截取出的就是某一时间段的数据。到达结束时间时,窗口不再收集数据,触发计算输出结果,并将窗口关闭销毁。所以可以说基本思路就是“定点发车”。
计数窗口(Count Window)
计数窗口基于元素的个数来截取数据,到达固定的个数时就触发计算并关闭窗口。每个窗口截取数据的个数,就是窗口的大小。基本思路是“人齐发车”。
2.2、按照窗口分配数据的规则分类
根据分配数据的规则,窗口的具体实现可以分为四类:滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)、会话窗口(Session Window)以及全局窗口(Global Window)。
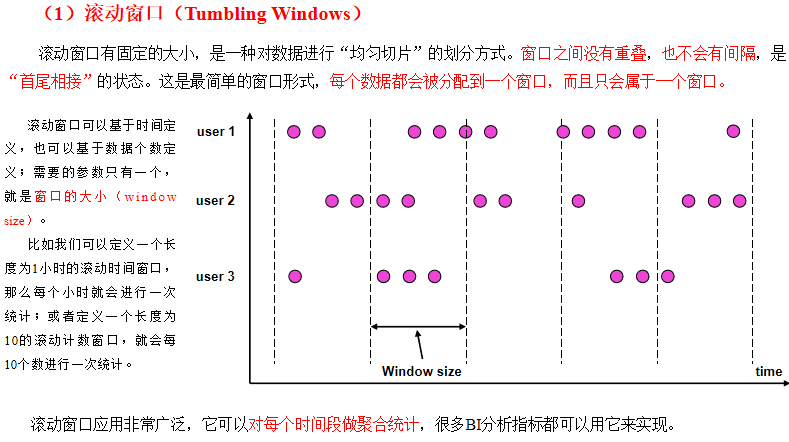
滚动窗口(Tumbling Window)
滚动窗口有固定的大小,是一种对数据进行“均匀切片”的划分方式。窗口之间没有重叠,也不会有间隔,是“首尾相接”的状态。这是最简单的窗口形式,每一个数据都会被分配到一个窗口,而且只会属于一个窗口。
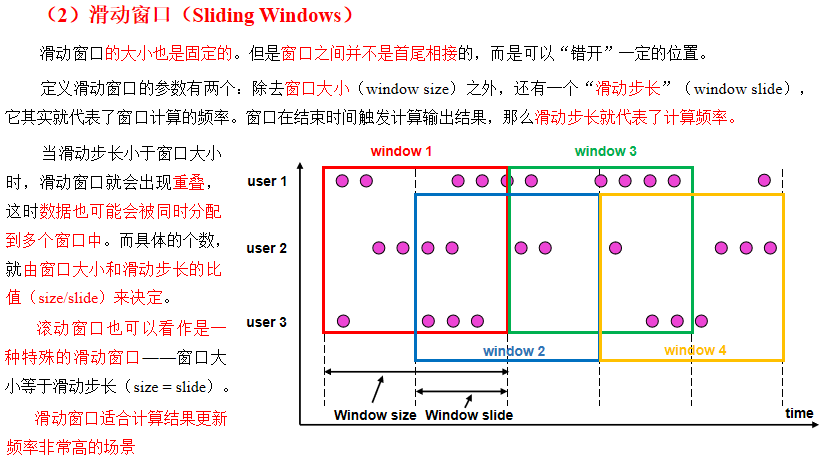
滑动窗口(Sliding Window)
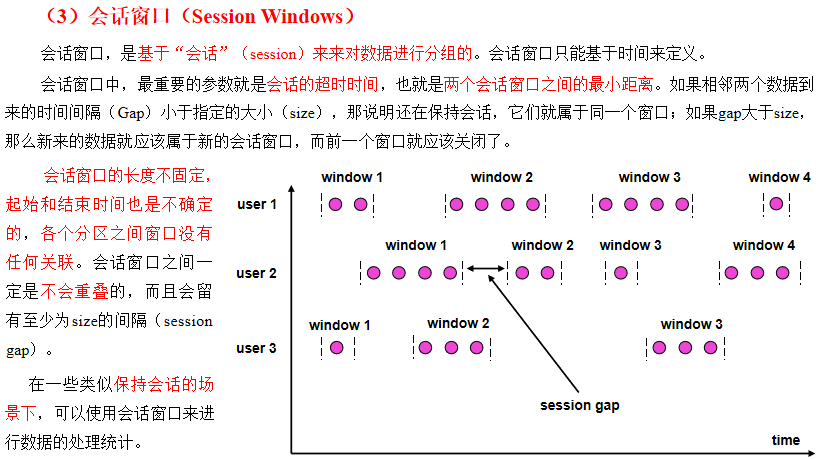
会话窗口
全局窗口
就是把所有数据当做在同一个窗口。这种窗口没有结束的时候,默认是不会做触发计算的。如果希望它能对数据进行计算处理,还需要自定义触发器。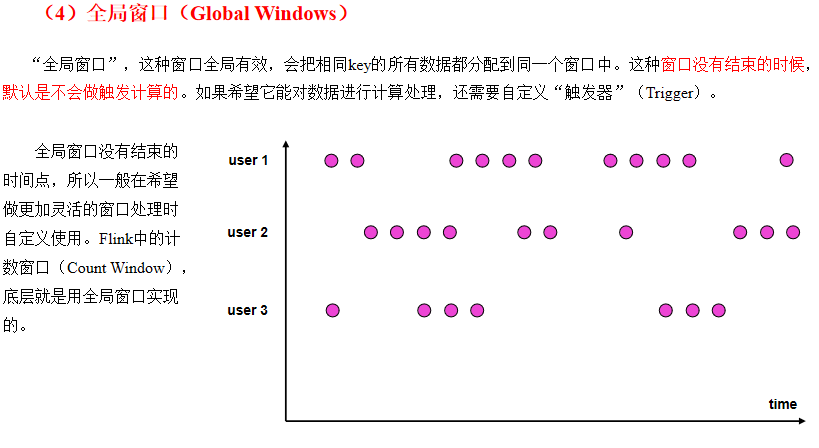
3、窗口 API 概览
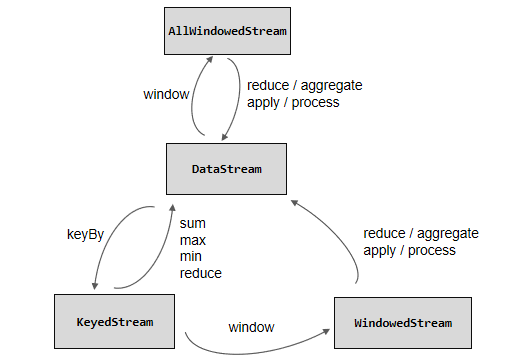
3.1、按键分区(Keyed)和非按键分区(Non-Keyed)
在定义窗口操作之前,首先要确定,到底是基于按键分区(Keyed)的数据流 KeyedStream 来开窗,还是直接在没有按键分区的 DataStream 上开窗。也就是说,在调用窗口算子之前,是否有 keyBy 操作。
按键分区窗口(Keyed Window)
经过按键分区 KeyBy 操作后,数据流会按照 key 被分为多条逻辑流(Logical Streams),这就是 KeyedStream。基于 KeyedStream 进行窗口操作时,窗口计算会在多个并行子任务上同时执行。相同 key 的数据会被发送到一个并行子任务,而窗口操作会基于每个 key 进行单独的处理。所以可以认为,每个 key 上都定义了一组窗口,各自独立地进行统计计算。
在代码实现上,我们需要先对 DataStream 调用.keyBy()进行按键分区,然后再调用.window()定义窗口。1
2stream.keyBy(...)
.window(...)非按键分区
如果没有进行 keyBy,那么原始的 DataStream 就不会分成多条逻辑流。这时窗口逻辑只能在一个任务(task)上执行,就相当于并行度变成了 1。
在代码中,直接基于 DataStream 调用.windowAll()定义窗口。1
stream.windowAll(...)注意:对于非按键分区的窗口操作,手动调大窗口算子的并行度也是无效的,windowAll 本身就是一个非并行的操作。
3.2、代码中窗口 API 的调用
窗口操作主要有两个部分:窗口分配器(Window Assigners)和窗口函数(Window Functions)。
1 | |
其中 .window() 方法需要传入一个窗口分配器,它指明了窗口的类型;而后面的 .aggregate() 方法传入一个窗口函数作为参数,它用来定义窗口具体的处理逻辑。窗口分配器有各种形式,而窗口函数的调用方法也不止 .aggregate() 一种。
4、窗口分配器(Window Assigner)
定义窗口分配器(Window Assaginer)是构建窗口算子的第一步,它的作用就是定义数据应该被分配到哪个窗口。所以可以说,窗口分配器其实就是在指定窗口的类型。
窗口分配器最通用的定义方式,就是调用 .window() 方法。这个方法需要传入一个 WindowAssiger 作为参数,返回 WindowedStream。如果是非按键分区窗口,那么直接调用 .windowAll() 方法,同样传入一个 WindowAssigner,返回的是 AllWindowedStream。
窗口按照驱动类型可以分成时间窗口和计数窗口,而按照具体的分配规则,又有滚动窗口、滑动窗口、会话窗口、全局窗口四种。除去需要自定义的全局窗口外,其他常用的类型 Flink 中都给出了内置的分配器的实现。
4.1、时间窗口
时间窗口是最常用的窗口类型,又可以细分为滚动、滑动和会话三种。
滚动处理时间窗口
窗口分配器由类 TumblingProcessingTimeWindows 提供,需要调用它的静态方法 .of()。
1 | |
这里 .of() 方法需要传入一个 Time 类型的参数 size,表示滚动窗口的大小,我们这里创建了一个长度为5秒的滚动窗口。
另外,.of() 还有一个重载方法,可以传入两个 Time 类型的参数:size 和 offset。第一个参数还是窗口大小,第二个参数则表示窗口起始点的偏移量。
滑动处理时间窗口
窗口分配器由类 SlidingProcessingTimeWindows 提供,同样需要调用它的静态方法 .of()。
1 | |
这里 .of() 方法需要传入两个Time类型的参数:size 和 slide,前者表示滑动窗口的大小,后者表示滑动窗口的滑动步长。我们这里创建了一个长度为10秒、滑动步长为5秒的滑动窗口。
滑动窗口同样可以追加第三个参数,用于指定窗口起始点的偏移量,用法与滚动窗口完全一致。
处理时间会话窗口
窗口分配器由类 ProcessingTimeSessionWindows 提供,需要调用它的静态方法 .withGap() 或者 .withDynamicGap()。
1 | |
这里 .withGap() 方法需要传入一个 Time 类型的参数 size,表示会话的超时时间,也就是最小间隔 session gap。我们这里创建了静态会话超时时间为10秒的会话窗口。
另外,还可以调用 withDynamicGap() 方法定义 session gap 的动态提取逻辑。
滚动事件时间窗口
窗口分配器由类 TumblingEventTimeWindows 提供,用法与滚动处理事件窗口完全一致。
1 | |
滑动事件时间窗口
窗口分配器由类 SlidingEventTimeWindows 提供,用法与滑动处理事件窗口完全一致。
1 | |
事件时间会话窗口
窗口分配器由类 EventTimeSessionWindows 提供,用法与处理事件会话窗口完全一致。
1 | |
4.2、计数窗口
计数窗口概念非常简单,本身底层是基于全局窗口(Global Window)实现的。Flink 为我们提供了非常方便的接口:直接调用 .countWindow() 方法。根据分配规则的不同,又可以分为滚动计数窗口和滑动计数窗口两类,下面我们就来看它们的具体实现。
滚动计数窗口
滚动计数窗口只需要传入一个长整型的参数 size,表示窗口的大小。
1 | |
我们定义了一个长度为 10 的滚动计数窗口,当窗口中元素数量达到 10 的时候,就会触发计算执行并关闭窗口。
滚动计数窗口
与滚动计数窗口类似,不过需要在 .countWindow() 调用时传入两个参数:size 和 slide,前者表示窗口大小,后者表示滑动步长。
1 | |
我们定义了一个长度为10、滑动步长为3的滑动计数窗口。每个窗口统计10个数据,每隔3个数据就统计输出一次结果。
全局窗口
全局窗口是计数窗口的底层实现,一般在需要自定义窗口时使用。它的定义同样是直接调用 .window(),分配器由 GlobalWindows 类提供。
1 | |
需要注意使用全局窗口,必须自行定义触发器才能实现窗口计算,否则起不到任何作用。
5、窗口函数
定义了窗口分配器,我们只是知道了数据属于哪个窗口,可以将数据收集起来了;至于收集起来到底是要做什么,还得看窗口函数。所以在窗口分配器之后,必须再接上一个定义窗口如何计算的操作,这就是所谓的“窗口函数”(Window Functions)。
窗口函数定义了要对窗口中收集的数据做的计算操作,根据处理的方式可以分为两类:增量聚合函数和全窗口函数。
5.1、增量聚合函数(ReduceFunction/AggregateFunction)
窗口将数据收集起来,最基本的处理操作当然就是进行聚合。我们可以每来一个数据就在之前结果上聚合一次,这就是“增量聚合”。
典型的增量聚合函数有两个:ReduceFunction 和 AggregateFunction。
1、归约聚合(ReduceFunction)
代码示例(求水位累加值):
1 | |
测试截图:

2、聚合函数(AggregateFunction)
ReduceFunction 可以解决大多数归约聚合的问题,但是这个接口有一个限制,就是聚合状态的类型、数据结果的类型必须和输入数据类型一样。
Flink Window API 中的 aggragate 就突破了这个限制,可以定义更加灵活的窗口聚合操作。这个方法需要传入一个 AggregateFunction 的实现类作为参数。
AggregateFunction 可以看作是 ReduceFunction 通用版本,这里有三种类型:输入类型(IN)、累加器类型(ACC)和输出类型(OUT)。输入类型IN 就是输入流中元素的数据类型;累加器类型ACC 则是我们进行聚合的中间状态类型;而数据类型当然就是最终计算结果的类型了。
接口中有四个方法:
createAccumulator():创建一个累加器,这就是为聚合创建一个初始状态,每个聚合任务只会调用一次。add():将输入的元素添加到累加器中。getResult():从累加器中提取聚合的输出结果merge():合并两个累加器,并将合并后的状态作为一个累加器返回
所以可以看到,AggregateFunction 的工作原理是:先调用 createAccumulator() 方法为任务初始化一个状态(累加器);而后每来一个数据就调用一次 add() 方法,对数据进行聚合,得到的结果保存在状态中;等到了窗口需要输出时,再调用 getResult 方法得到计算结果。很明显,与 ReduceFunction 相同,AggregateFunction 也是增量式的聚合;而由于输入、中间状态、输出的类型可以不同,使得应用更加灵活方便。
代码实现:
1 | |
测试截图:
另外,Flink 也为窗口的聚合提供了一系列预定义的简单聚合方法,可以直接基于 WindowedStream 调用。主要包括 .sum()/max()/maxBy()/min()/minBy(),与 KeyedStream 的简单聚合非常相似。它们的底层,其实都是通过 AggregateFunction 来实现的。
5.2、全窗口函数(Full Window Functions)
有些场景下,我们要做的计算必须基于全部的数据才有效,这时做增量聚合就没什么意义了;另外,输出的结果可能要包含上下文中的一些信息(比如窗口的起始时间),这是增量聚合函数做不到的。
所以我们还需要有更丰富的窗口计算方式。窗口操作中的另一大类就是全窗口函数。与增量函数不同,全局窗口函数首先需要收集窗口中的数据,并在内部缓存起来,等到窗口要输出结果的时候再取出数据进行计算。
在 Flink 中,全局窗口函数也是有两种:WindowFunction 和 ProcessWindowFunction。
1、窗口函数(WindowFunction)
WindowFunction 字面上就是“窗口函数”,它其实是老版本的通用窗口函数接口。我们可以基于 WindowedStream 调用 .apply() 方法,传入一个WindowFunction 的实现类。
1 | |
这个类中可以获取到包含窗口所有数据的可迭代集合(Iterable),还可以拿到窗口(Window)本身的信息。
不过 WindowFunction 能提供的上下文信息比较少,也没有更高级的功能。事实上,它的作用可以被 ProcessWindowFunction 全覆盖,所以之后可能会逐渐弃用。
2、处理窗口函数(ProcessWindowFunction)
ProcessWindowFunction 是 Window API 中最底层的通用窗口函数接口。之所以说它“最底层”,是因为除了可以拿到窗口中的所有数据之外,ProcessWindowFunction 还可以获取到一个“上下文对象”(Context)。这个上下文对象非常强大,不仅能够获取窗口信息,还可以访问当前的时间和状态信息。这里的时间就包括了处理时间(processing time)和事件时间水位线(event time watermark)。这就使得 ProcessWindowFunction 更加灵活、功能更加丰富,其实就是一个增强版的 WindowFunction。
1 | |
测试截图:

5.3、增量聚合和全窗口函数的结合使用
在实际应用中,我们往往希望兼具这两者的优点,把它们结合在一起使用。Flink 的 Window API 就给我们实现了这样的用法。
我们之前在调用 WindowedStream 的 .reduce() 和 .aggregate() 方法时,只是简单地直接传入了一个 ReduceFunction 或 AggregateFunction 进行增量聚合。除此之外,其实还可以传入第二个参数:一个全窗口函数,可以是 WindowFunction 或者 ProcessWindowFunction。
1 | |
这样调用的处理机制是:基于第一个参数(增量聚合函数)来处理窗口数据,每来一个数据就做一次聚合;等到窗口需要触发计算的时候,就调用第二个参数(全局窗口函数)的处理逻辑输出结果。需要注意的是,这里的全窗口函数就不再缓存所有数据了,而是直接将增量聚合函数的结果拿来当做了Iterable 类型的输入。
1 | |
测试截图:
6、其它API
对于一个窗口算子而言,窗口分配器和窗口函数是必不可少的。除此之外,Flink 还提供了其他一些可选的 API,让我们可以更加灵活地控制窗口行为。
触发器和移除器在日常使用中很少会用到,这里仅仅简单介绍其语法格式。
6.1、触发器(Trigger)
触发器主要是用来控制窗口什么时候触发计算。所谓的“触发计算”,本质上就是执行窗口函数,所以可以认为是计算得到的结果并输出的过程。
基于 WindowedStream 调用 .triggrt() 方法,就可以传入一个自定义的窗口触发器(Trigger·)。
1 | |
6.2、移除器(Evictor)
移除器主要用来定义移除某些数据的逻辑。基于 WindowedStream 调用 .evictor() 方法,就可以传人一个自定义的移除器(Evictor)。Evictor 是一个接口,不同的窗口类型都有各自预实现的移除器。
1 | |