09-Flink 处理函数之广播流
Flink 官网主页地址:https://flink.apache.org
Flink 官方中文地址:https://nightlies.apache.org/flink/flink-docs-stable/zh/
Broadcast State 是 Flink 1.5 引入的功能。Flink 中的广播流(Broadcast Stream)是一种特殊的数据流,它允许将一个流的数据广播到其他所有的流上。从而实现在不同任务间共享数据的目的。广播流在处理配置信息、小数据集或者全局变量等场景下特别有用,因为这些数据需要在所有任务中保持一致且实时更新。
使用场景示例:
应用配置更新:将配置信息广播到多个数据流,当配置发生变化时,可以实时更新所有使用该配置的数据流处理逻辑。
- 例如,我们需要依赖一个不断变化的控制规则来处理主数据流的数据,主数据流数据量比较大,只能分散到多个算子实例上,控制规则数据相对比较小,可以分发到所有的算子实例上。
- 例如,当需要从 MySQL 数据库中实时查询和更新某些关键字过滤规则时,如果直接在计算函数中进行查询,可能会阻塞整个计算过程甚至导致任务停止。通过使用广播流,可以将这些配置信息广播到所有相关任务的实例中,然后在计算过程中直接使用这些配置信息,从而提高计算效率和实时性。
查询规则更新:将查询规则广播到数据流,进行实时的规则检测和响应。
缓存数据更新:将缓存的数据或者参数广播到数据流,进行实时的数据缓存更新。
Broadcast State 与直接在时间窗口进行两个数据流的 Join 的不同点在于,控制规则数据量较小,可以直接放到每个算子实例里,这样可以大大提高主数据流的处理速度。
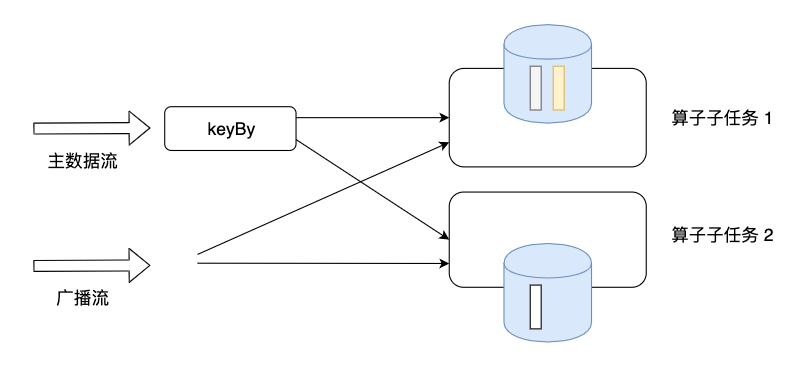
广播流的使用通常涉及以下步骤:
定义MapStateDescriptor:首先需要定义一个 MapStateDescriptor 来描述要广播的数据的格式。这个描述器指定了数据的键值对类型。
创建广播流:然后,需要将一个普通的流转换为广播流。这通常通过调用流的
broadcast()方法实现,并将 MapStateDescriptor 作为参数传入。连接广播流与非广播流:一旦有了广播流,就可以将其与一个或多个非广播流(无论是 Keyed 流还是 Non-Keyed 流)连接起来。这通过调用非广播流的
connect()方法完成,并将广播流作为参数传入。连接后的流是一个BroadcastConnectedStream,它提供了process()方法用于处理数据。处理数据:在
process()方法中,可以编写逻辑来处理非广播流和广播流的数据。根据非广播流的类型(Keyed或Non-Keyed),需要传入相应的KeyedBroadcastProcessFunction或BroadcastProcessFunction类型的处理函数。
总的来说,Flink 的广播流提供了一种有效的方式来实现不同任务间的数据共享和实时更新,适用于各种需要全局数据或配置的场景。
案例
将用户信息进行广播,从 Kafka 中读取用户访问记录,判断访问用户是否存在
1 | |
总结下来,使用 Broadcast State 需要进行下面三步:
- 接收一个普通数据流,并使用
broadcast()方法将其转换为BroadcastStream,因为 Broadcast State 目前只支持 Key-Value 结构,需要使用MapStateDescriptor描述它的数据结构。 - 将
BroadcastStream与一个DataStream或KeyedStream使用connect()方法连接到一起。 - 实现一个
ProcessFunction,如果主流是DataStream,则需要实现BroadcastProcessFunction;如果主流是KeyedStream,则需要实现KeyedBroadcastProcessFunction。这两种函数都提供了时间和状态的访问方法。
在 KeyedBroadcastProcessFunction 个函数类中,有两个函数需要实现:
processElement:处理主数据流(非Broadcast流)中的每条元素,输出零到多个数据。ReadOnlyContext可以获取时间和状态,但是只能以只读的形式读取Broadcast State,不能修改,以保证每个算子实例上的Broadcast State都是相同的。processBroadcastElement:处理流入的广播流,可以输出零到多个数据,一般用来更新Broadcast State。
此外,在 KeyedBroadcastProcessFunction 中可以注册 Timer,并在 onTimer 方法中实现回调逻辑。本例中为了保持代码简洁,没有使用,一般可以用来清空状态,避免状态无限增长下去。
Broadcast 使用注意事项
- 同一个 operator 的各个 task 之间没有通信,广播流侧(processBroadcastElement)可以能修改 broadcast state,而数据流侧(processElement)只能读 broadcast state.;
- 需要保证所有 Operator task 对 broadcast state 的修改逻辑是相同的,否则会导致非预期的结果;
- Operator tasks 之间收到的广播流元素的顺序可能不同:虽然所有元素最终都会下发给下游 tasks,但是元素到达的顺序可能不同,所以更新 state 时不能依赖元素到达的顺序;
- 每个 task 对各自的 Broadcast state 都会做快照,防止热点问题;
- 目前不支持 RocksDB 保存 Broadcast state:Broadcast state 目前只保存在内存中,需要为其预留合适的内存。