12-Flink 流控和反压之反压解决思路
Flink 官网主页地址:https://flink.apache.org
Flink 官方中文地址:https://nightlies.apache.org/flink/flink-docs-stable/zh/
Flink 反压:https://nightlies.apache.org/flink/flink-docs-release-1.19/zh/docs/ops/monitoring/back_pressure/
反压的原因
反压(BackPressure)通常产生于这样的场景:短时间的负载高峰导致系统接收数据的速率远高于它处理数据的速率。
反压其实就是 task 处理不过来,算子的 sub-task 需要处理的数据量 > 能够处理的数据量,比如:
当前某个 sub-task 只能处理 1w qps 的数据,但实际上到来 2w qps 的数据,但是实际只能处理 1w 条,从而反压
常见原因有:
数据倾斜:数据分布不均,个别 task 处理数据过多
算子性能问题:可能某个节点逻辑很复杂,比如 sink 节点很慢,lookup join 热查询慢
流量陡增:比如大促时流量激增,或者使用了数据炸开的函数
反压的危害
任务处理性能出现瓶颈:以消费 Kafka 为例,大概率会出现消费 Kafka Lag。
整个任务完全卡住。比如在 TUMBLE 窗口算子的任务中,反压后可能会导致下游算子的 input pool 和上游算子的 output pool 满了,这时候如果下游窗口的 watermark 一直对不齐,窗口触发不了计算的话,下游算子就永远无法触发窗口计算了,整个任务卡住
Checkpoint 时间长或者失败:因为某些反压会导致 barrier 需要花很长时间才能对齐,任务稳定性差
反压如果不能得到正确的处理,可能会影响到 checkpoint 时长和 state 大小,甚至可能会导致资源耗尽甚至系统崩溃。
影响 checkpoint 时长。barrier 不会越过普通数据,数据处理被阻塞也会导致 checkpoint barrier 流经整个数据管道的时长变长,导致 checkpoint 总体时间(End toEnd Duration)变长。
state 变大:为保证 Exactly-Once 准确一次,对于有两个以上输入管道的 Operator,checkpoint barrier 需要对齐,即接受到较快的输入管道的 barrier 后,它后面数据会被缓存起来但不处理,直到较慢的输入管道的 barrier 也到达。这些被缓存的数据会被放到 state 里面,导致 checkpoint 变大。
checkpoint 是保证准确一次的关键,checkpoint 时间变长有可能导致 checkpoint 超时失败,而 state 大小可能拖慢 checkpoint 甚至导致 OOM。
怎么定位反压节点
查看WebUI
作业图的 UI 展示,会通过不同颜色和数值代表繁忙和反压的程度

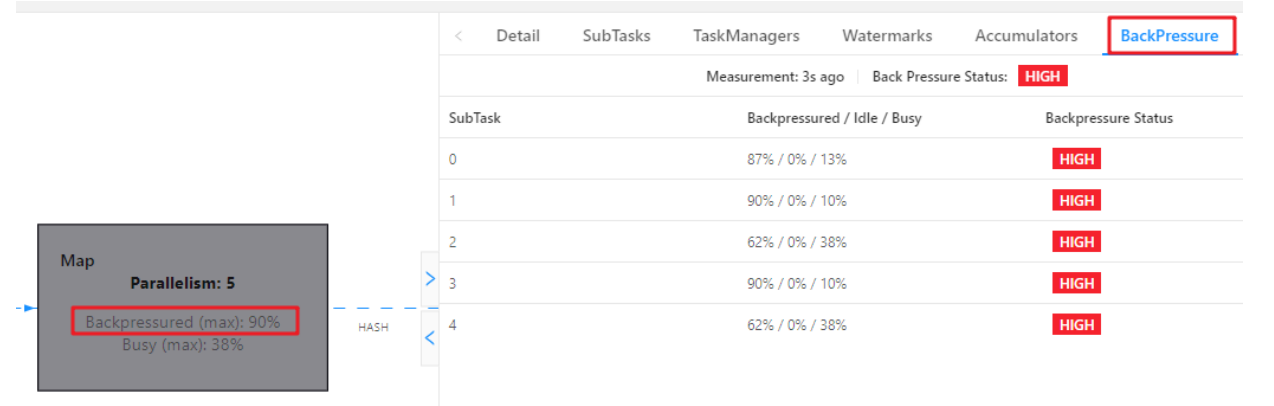
可以通过 BackPressure 查看 subtask 反压情况
还可以查看 Flink 任务的 Metrics
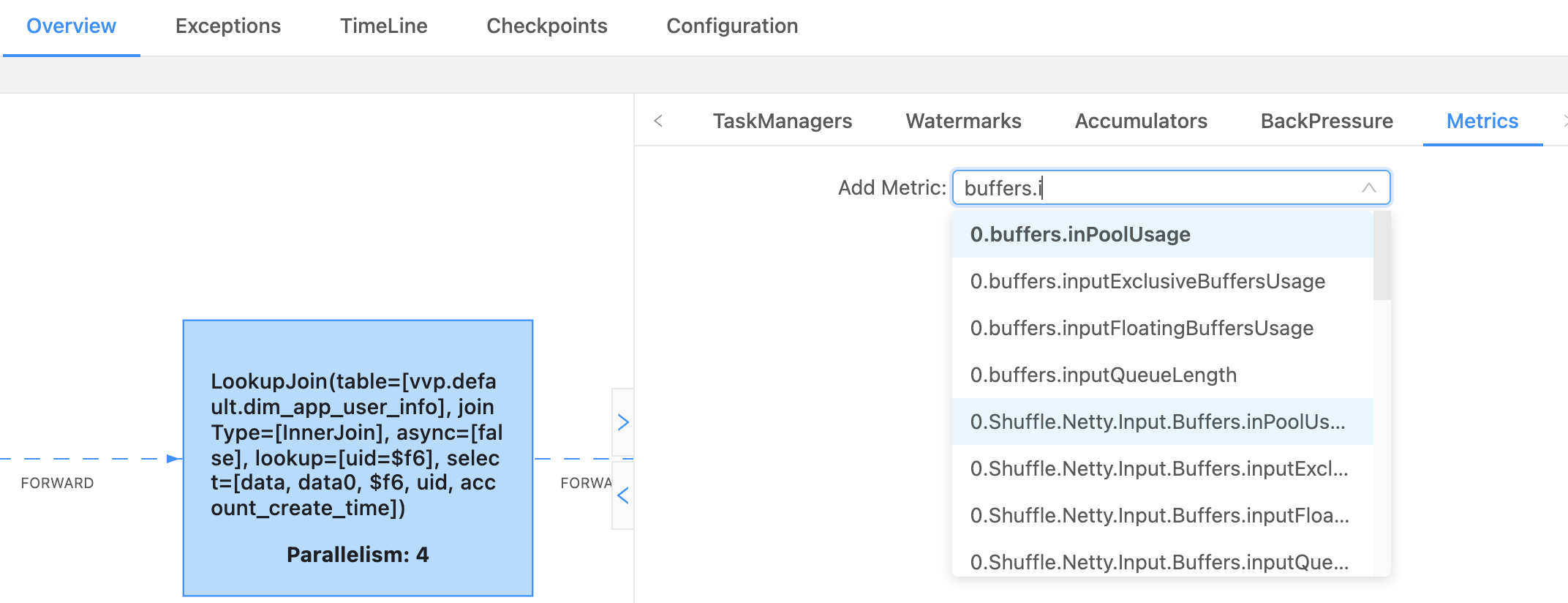
我这个是并行度是 4 ,所以会有 0、1、2、3 代表是哪个 subTask(task 下每个并行 task),其中看到的比较多的是这两个,outPutUsage 代表发送端 Buffer 的使用率,inPutusage 代表的接收端 Buffer 的使用率

然后就很好定位了,基本上常出现反压的就那么几个算子
还不行就设置 pipeline.operator-chaining: false,禁用 operator chains ,这时候一个算子就是一个 task ,在根据定位到具体算子
排查反压原因
我们生产环境中,会遇到负载高峰、CheckPoint、作业重启引起的数据积压而导致反压,这种情况反压如果是暂时的,我们可以忽略它
除了定位反压节点,还需要排查原因
- 节点有性能瓶颈,可能是该节点所在的机器有网络,磁盘等等故障,机器的网络延迟和磁盘不足,频繁GC,数据热点等原因
- 数据源生产的数据过快,计算框架处理不及时。
- Flink 算子间并行度不同,下游算子相比上游算子过小
- 发生数据倾斜
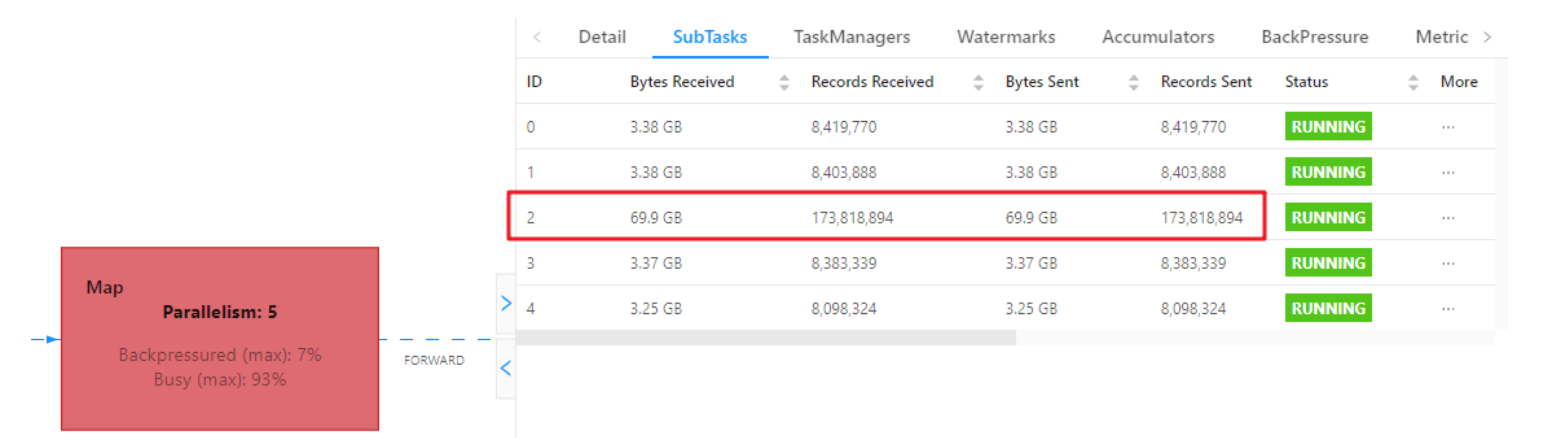
数据倾斜
我们可以用 Web UI 查看该节点每个 SubTask 的 Record Send 和 Record Received 来看是否数据倾斜,也可以通过 Checkpoint 每个 Subtask 的 state 的 size 大小
火焰图
在代码提交时设置开启火焰图,然后可以在 Web UI 里面查看
1 | |
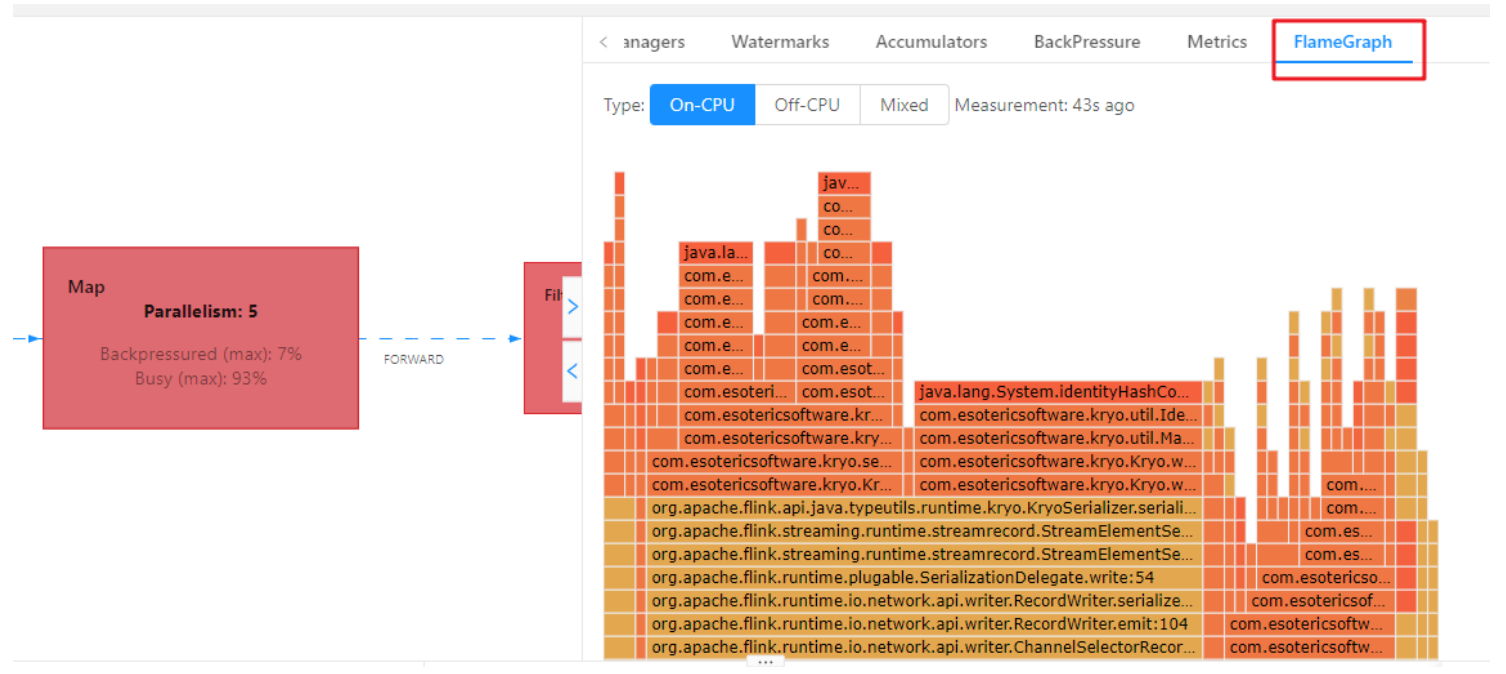
纵向是调用链,从下往上,顶部就是正在执行的函数
不是用颜色代表的,而是横向长度,代表出现次数或者说执行时长,某个函数过宽,出现了平顶,那这个函数可能有性能问题
分析 GC
也可能是 TaskManager 的内存引起的 GC 问题,也会导致反压,我们一般使用 G1 回收机制,有可能是 TaskManager JVM 各区内存分配不合理导致频繁的 Full GC
我们可以提交任务时设置打印 GC 日志然后查看 Web UI GC 情况或者直接看日志
1 | |

外部组件交互
如果发现 Source 端数据读取性能比较低或者 Sink 端写入性能较差,需要检查第三方组件是否遇到瓶颈,还有就是做维表 join 时的性能问题。
例如:Kafka 集群是否需要扩容,Kafka 连接器是否并行度较低,HBase 的 rowkey 是否遇到热点问题,是否请求处理不过来,ClickHouse 并发能力较弱,是否达到瓶颈……
关于第三方组件的性能问题,需要结合具体的组件来分析,最常用的思路:
1)异步 io+热缓存来优化读写性能
2)先攒批再读写
常见处理方案
- 很多时候反压就是资源不足导致的,给任务加资源
- 如果是数据倾斜、算子性能问题之类,那就去解决这些问题
- 如果确实是流量过大消费不过来,就整任务链中每个算子的并行度,以匹配系统的吞吐能力和处理能力(如果是 Kafka,需要同时调大 Kafka 分区数)
- 限制数据源的消费数据速度。比如在事件时间窗口的应用中,可以自己设置在数据源处加一些限流措施,让每个数据源都能够够匀速消费数据,避免出现有的 Source 快,有的 Source 慢,导致窗口 input pool 打满,watermark 对不齐导致任务卡住
- 关闭 Checkpoint。关闭 Checkpoint 可以将 barrier 对齐这一步省略掉,促使任务能够快速回溯数据。然后等数据回溯完成之后,再将 Checkpoint 打开