数据定义语言(DDL)概述 DDL语法的作用 数据定义语言 (Data Definition Language, DDL),是SQL语言集中对数据库内部的对象结构进行创建,删除,修改等的操作语言,这些数据库对象包括database(schema)、table、view、index等。
核心语法由CREATE 、ALTER 与DROP 三个所组成。DDL并不涉及表内部数据的操作。
在某些上下文中,该术语也称为数据描述语言,因为它描述了数据库表中的字段和记录。
Hive 中 DDL 使用 Hive SQL(HQL)与SQL的语法大同小异,基本上是相通的,学过SQL的使用者可以无痛使用Hive SQL。只不过在学习HQL语法的时候,特别要注意Hive自己特有的语法知识点,比如partition相关的DDL操作。
基于Hive的设计、使用特点,HQL中create语法(尤其create table)将是学习掌握DDL语法的重中之重 。
可以说建表是否成功直接影响数据文件是否映射成功,进而影响后续是否可以基于SQL分析数据。
Hive DDL建表基础 完整建表语法树 1 2 3 4 5 6 7 8 9 CREATE [TEMPORARY ] [EXTERNAL ] TABLE [IF NOT EXISTS ] [db_name.]table_nameCOMMENT col_comment], ... ]COMMENT table_comment]BY (col_name data_type [COMMENT col_comment], ...)]BY (col_name, col_name, ...) [SORTED BY (col_name [ASC |DESC ], ...)] INTO num_buckets BUCKETS]ROW FORMAT DELIMITED |SERDE serde_name WITH SERDEPROPERTIES (property_name=property_value,...)]STORED AS file_format]
[]中括号的语法表示可选。
|表示使用的时候,左右语法二选一。
建表语句中的语法顺序要和上述语法规则保持一致。
Hive读写文件机制 SerDe是什么? SerDe是Serializer、Deserializer的简称,目的是用于序列化和反序列化。序列化是对象转化为字节码的过程;而反序列化是字节码转换为对象的过程。
Hive使用SerDe(和FileFormat)读取和写入行对象。
需要注意的是 ,“key” 部分在读取时会被忽略,而在写入时 key 始终是常数。基本上 行对象存储在“value”中 。
可以通过 desc formatted tablename 查看表的相关 SerDe 信息。默认如下:
Hive读写文件流程 Hive 读取文件机制:首先调用InputFormat(默认TextInputFormat),返回一条一条kv键值对记录(默认是一行对应一条记录)。然后调用SerDe(默认LazySimpleSerDe)的Deserializer,将一条记录中的value根据分隔符切分为各个字段。
Hive 写文件机制:将Row写入文件时,首先调用SerDe(默认LazySimpleSerDe)的Serializer将对象转换成字节序列,然后调用OutputFormat将数据写入HDFS文件中。
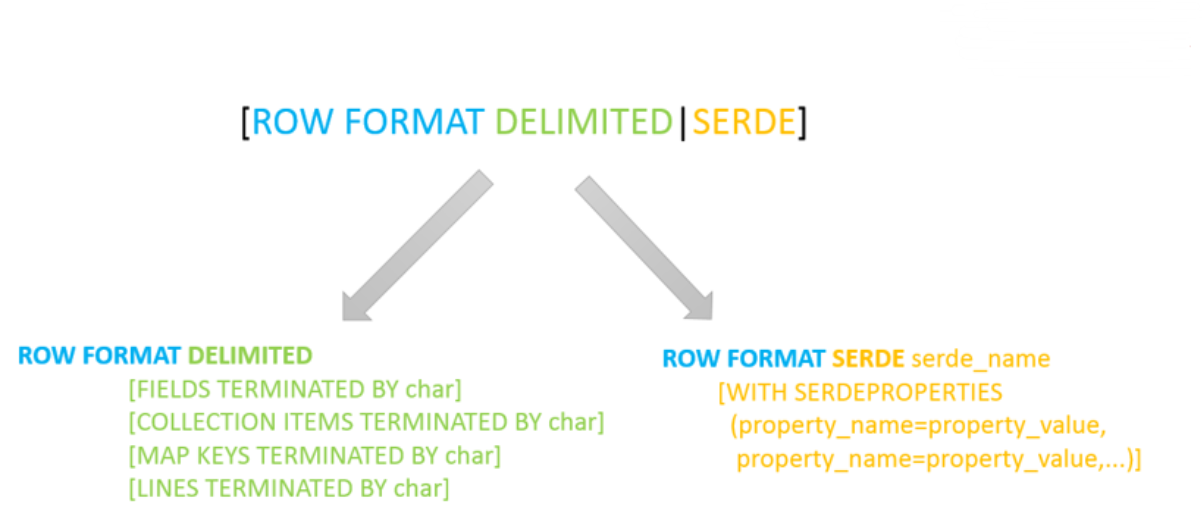
SerDe相关语法 在Hive的建表语句中,和SerDe相关的语法为:
其中ROW FORMAT是语法关键字,DELIMITED和SERDE二选其一。
如果使用 delimited 表示使用默认的 LazySimpleSerDe 类来处理数据。如果数据文件格式比较特殊可以使用 ROW FORMAT SERDE serde_name 指定其他的Serde类来处理数据,甚至支持用户自定义SerDe类。
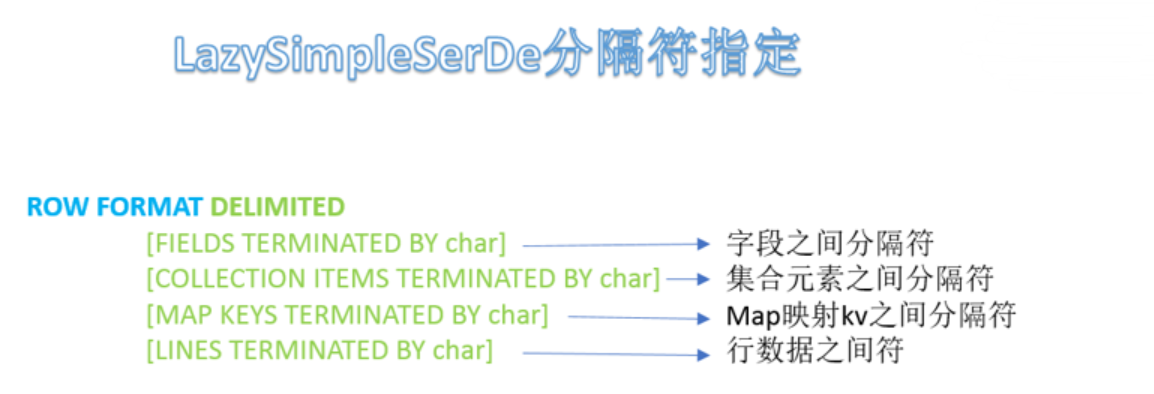
LazySimpleSerDe分隔符指定 LazySimpleSerDe是Hive 默认的序列化类,包含4种子语法,分别用于指定 字段之间 、集合元素之间 、map映射 kv之间 、换行 的分隔符号。在建表的时候可以根据数据的特点灵活搭配使用。
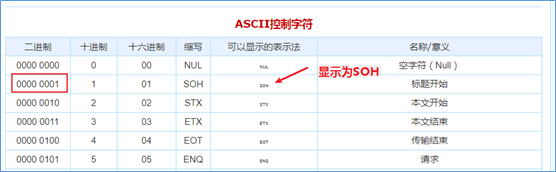
默认分隔符 hive建表时如果没有row format语法。此时**字段之间默认的分割符是’\001’**,是一种特殊的字符,使用的是ascii编码的值,键盘是打不出来的。
在vim编辑器中,连续按下Ctrl+v/Ctrl+a即可输入’\001’ ,显示 ^A
在一些文本编辑器中将以SOH的形式显示:
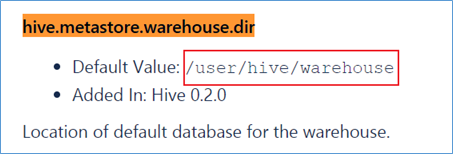
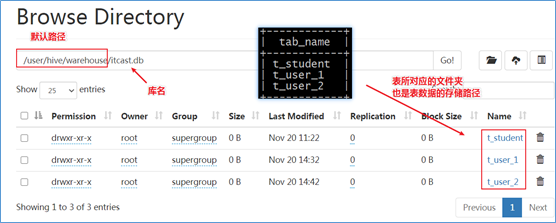
Hive 数据存储路径 默认存储路径 Hive表默认存储路径是由 ${HIVE_HOME}/conf/hive-site.xml 配置文件的 hive.metastore.warehouse.dir 属性指定。默认值是:/user/hive/warehouse。
在该路径下,文件将根据所属的库、表,有规律的存储在对应的文件夹下。
指定存储路径 在 Hive 建表的时候,可以通过location语法来更改数据在HDFS上的存储路径 ,使得建表加载数据更加灵活方便。
语法:LOCATION '<hdfs_location>'。
对于已经生成好的数据文件,使用location指定路径将会很方便。
案例 原生数据类型案例 文件 archer.txt 中记录了手游《王者荣耀》射手的相关信息,内容如下所示,其中字段之间分隔符为制表符\t,要求在Hive中建表映射成功该文件。
1 2 3 4 5 6 7 8 9 10 1 后羿 5986 1784 396 336 remotely archer
字段含义:id、name(英雄名称)、hp_max(最大生命)、mp_max(最大法力)、attack_max(最高物攻)、defense_max(最大物防)、attack_range(攻击范围)、role_main(主要定位)、role_assist(次要定位)。
分析一下:字段都是基本类型,字段的顺序需要注意一下。字段之间的分隔符是制表符,需要使用row format语法进行指定。
建表语句 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 create database itcast;use itcast;create table t_archer(id int comment "ID" ,name string comment "英雄名称" ,int comment "最大生命" ,int comment "最大法力" ,int comment "最高物攻" ,int comment "最大物防" ,string comment "攻击范围" ,string comment "主要定位" ,string comment "次要定位" comment "王者荣耀射手信息" row format delimited fields terminated by "\t" ;
建表成功之后,在Hive的默认存储路径下就生成了表对应的文件夹,把archer.txt文件上传到对应的表文件夹下。
1 hadoop fs -put archer.txt /user/hive/warehouse/honor_of_kings.db/t_archer
复杂数据类型案例 文件 hot_hero_skin_price.txt 中记录了手游《王者荣耀》热门英雄的相关皮肤价格信息,内容如下,要求在 Hive 中建表映射成功该文件。
1 2 3 4 5 1,孙悟空,53,西部大镖客:288-大圣娶亲:888-全息碎片:0-至尊宝:888-地狱火:1688
字段:id、name(英雄名称)、win_rate(胜率)、skin_price(皮肤及价格)
分析一下:前3个字段原生数据类型、最后一个字段复杂类型map。需要指定字段之间分隔符、集合元素之间分隔符、map kv之间分隔符。
建表语句 1 2 3 4 5 6 7 8 9 10 create table t_hot_hero_skin_price(id int ,name string ,int ,map <string ,int >row format delimited fields terminated by ',' terminated by '-' map keys terminated by ':' ;
建表成功后,把hot_hero_skin_price.txt文件上传到对应的表文件夹下。
1 hadoop fs -put hot_hero_skin_price.txt /user/hive/warehouse/honor_of_kings.db/t_hot_hero_skin_price
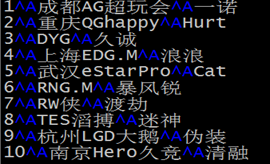
默认分隔符案例 文件 team_ace_player.txt 中记录了手游《王者荣耀》主要战队内最受欢迎的王牌选手信息,内容如下,要求在Hive中建表映射成功该文件。
字段:id、team_name(战队名称)、ace_player_name(王牌选手名字)
分析一下:数据都是原生数据类型,且字段之间分隔符是\001,因此在建表的时候可以省去row format语句,因为Hive默认的分隔符就是\001。
建表语句 1 2 3 4 5 create table t_team_ace_player(id int ,string ,string
建表成功后,把 team_ace_player.txt 文件上传到对应的表文件夹下。
1 hadoop fs -put team_ace_player.txt /user/hive/warehouse/honor_of_kings.db/t_team_ace_player
Hive DDL 其他语法 Database|schema(数据库) DDL操作 Hive 中 DATABASE 的概念和 RDBMS 中类似,我们称之为数据库。在 Hive 中, DATABASE 和 SCHEMA是可互换的,使用 DATABASE 或 SCHEMA 都可以。
1 2 3 4 CREATE (DATABASE |SCHEMA ) [IF NOT EXISTS ] database_nameCOMMENT database_comment]WITH DBPROPERTIES (property_name=property_value, ...)];
COMMENT :数据库的注释说明语句LOCATION :指定数据库在HDFS存储位置,默认/user/hive/warehouseWITH DBPROPERTIES :用于指定一些数据库的属性配置。
创建一个数据库:itcast
1 2 3 4 create database if not exists itcastcomment "this is my first db" "/user/hive/warehouse/itcast.db" with dbproperties ('createdBy' ='AllenWoon' );
注意:使用 location 指定路径的时候,最好是一个新创建的空文件夹。
Desc/Use/ALTER/DROP相关操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 use itcast;ALTER DATABASE itcast SET DBPROPERTIES ("createDate" ="20240827" );ALTER DATABASE itcast SET OWNER USER zhengchubin;ALTER DATABASE itcast SET LOCATION "hdfs:///data/itcast.db" ;DROP DATABASE IF EXISTS itcast;DROP DATABASE IF EXISTS itcast CASCADE ;
Table(表)DDL操作 Describe table Hive中的DESCRIBE table 语句用于显示Hive中表的元数据信息。
1 2 describe formatted [db_name.]table_name;describe extended [db_name.]table_name;
如果指定了EXTENDED关键字,则它将以Thrift序列化形式显示表的所有元数据。如果指定了FORMATTED关键字,则它将以表格格式显示元数据。
Drop table DROP TABLE删除该表的元数据和数据。如果已配置垃圾桶(且未指定PURGE),则该表对应的数据实际上将移动到.Trash/Current目录,而元数据完全丢失。删除EXTERNAL表时,该表中的数据不会从文件系统中删除,只删除元数据。
如果指定了PURGE,则表数据不会进入.Trash/Current目录,跳过垃圾桶直接被删除。因此如果DROP失败,则无法挽回该表数据。
1 DROP TABLE [IF EXISTS ] table_name [PURGE ];
Truncate table 从表中删除所有行。可以简单理解为清空表的所有数据但是保留表的元数据结构。如果HDFS启用了垃圾桶,数据将被丢进垃圾桶,否则将被删除。
1 TRUNCATE [TABLE ] table_name;
Alter table 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 ALTER TABLE table_name RENAME TO new_table_name;ALTER TABLE table_name SET TBLPROPERTIES (property_name = property_value, ... );ALTER TABLE student SET TBLPROPERTIES ('comment' = "new comment for student table" );ALTER TABLE table_name SET SERDE serde_class_name [WITH SERDEPROPERTIES (property_name = property_value, ... )];ALTER TABLE table_name [PARTITION partition_spec] SET SERDEPROPERTIES serde_properties;ALTER TABLE table_name SET SERDEPROPERTIES ('field.delim' = ',' );ALTER TABLE table_name [PARTITION partition_spec] UNSET SERDEPROPERTIES (property_name, ... );ALTER TABLE table_name SET FILEFORMAT file_format;ALTER TABLE table_name SET LOCATION "new location" ;CREATE TABLE test_change (a int , b int , c int );change column a's name to a1. ALTER TABLE test_change CHANGE a a1 INT; // Next change column a1' s name to a2, its data type to string , and put it after column b.ALTER TABLE test_change CHANGE a1 a2 STRING AFTER b;change column c's name to c1, and put it as the first column. ALTER TABLE test_change CHANGE c c1 INT FIRST; // The new table' s structure is : c1 int , b int , a2 string.Add a comment to column a1ALTER TABLE test_change CHANGE a1 a1 INT COMMENT 'this is column a1' ;ALTER TABLE table_name ADD |REPLACE COLUMNS (col_name data_type,...);
Partition(分区)DDL操作 Add partition 分区值仅在为字符串时才应加引号。位置必须是数据文件所在的目录。ADD PARTITION会更改表元数据,但不会加载数据。如果分区位置中不存在数据,查询将不会返回任何结果。
1 2 3 4 5 6 7 8 ALTER TABLE table_name ADD PARTITION (dt='20170101' ) location'/user/hadoop/warehouse/table_name/dt=20170101' ; ALTER TABLE table_name ADD PARTITION (dt='2008-08-08' , country='us' ) location '/path/to/us/part080808' PARTITION (dt='2008-08-09' , country='us' ) location '/path/to/us/part080809' ;
rename partition 1 2 3 ALTER TABLE table_name PARTITION partition_spec RENAME TO PARTITION partition_spec;ALTER TABLE table_name PARTITION (dt='2008-08-09' ) RENAME TO PARTITION (dt='20080809' );
delete partition 可以使用ALTER TABLE DROP PARTITION删除表的分区。这将删除该分区的数据和元数据。
1 2 3 ALTER TABLE table_name DROP [IF EXISTS ] PARTITION (dt='2008-08-08' , country='us' );ALTER TABLE table_name DROP [IF EXISTS ] PARTITION (dt='2008-08-08' , country='us' ) PURGE ;
msck partition Hive将每个表的分区列表信息存储在其metastore中。但是,如果将新分区直接添加到HDFS(例如通过使用hadoop fs -put命令)或从HDFS中直接删除分区文件夹,则除非用户ALTER TABLE table_name ADD/DROP PARTITION在每个新添加的分区上运行命令,否则metastore(也就是Hive)将不会意识到分区信息的这些更改。
但是,用户可以使用修复表选项运行metastore check命令。
1 2 REPAIR ] TABLE table_name [ADD /DROP /SYNC PARTITIONS ];
MSC命令的默认选项是“添加分区”。使用此选项,它将把HDFS上存在但元存储中不存在的所有分区添加到元存储中。DROP PARTITIONS选项将从已经从HDFS中删除的metastore中删除分区信息。
SYNC PARTITIONS选项等效于调用ADD和DROP PARTITIONS。
如果存在大量未跟踪的分区,则可以批量运行MSCK REPAIR TABLE,以避免OOME(内存不足错误)。
alter partition 1 2 3 4 5 ALTER TABLE table_name PARTITION (dt='2008-08-09' ) SET FILEFORMAT file_format;ALTER TABLE table_name PARTITION (dt='2008-08-09' ) SET LOCATION "new location" ;
Hive Show 显示语法 Show 相关的语句提供了一种查询 Hive metastore 的方法。可以帮助用户查询相关信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 show databases ;show schemas;show tables ;SHOW TABLES [IN database_name]; Show Views;SHOW VIEWS 'test_*' ; SHOW VIEWS FROM test1; SHOW VIEWS [IN /FROM database_name];SHOW MATERIALIZED VIEWS [IN /FROM database_name];show partitions table_name;SHOW TABLE EXTENDED [IN |FROM database_name] LIKE table_name;show table extended like student;SHOW TBLPROPERTIES table_name;show tblproperties student;SHOW CREATE TABLE ([db_name.]table_name|view_name);show create table student;SHOW COLUMNS (FROM |IN ) table_name [(FROM |IN ) db_name];show columns in student;show functions;describe database database_name;