--SemanticException:Expression not in GROUP BY key 'deaths' --deaths不是分组字段 报错 --state是分组字段 可以直接出现在select_expr中 select state,deaths from t_usa_covid19_p where count_date = "2021-01-28"groupby state;
--被聚合函数应用 select state,count(deaths) from t_usa_covid19_p where count_date = "2021-01-28"groupby state;
--having --统计死亡病例数大于10000的州 --where语句中不能使用聚合函数 语法报错 select state,sum(deaths) from t_usa_covid19_p where count_date = "2021-01-28"andsum(deaths) >10000groupby state;
--先where分组前过滤(此处是分区裁剪),再进行group by分组(含聚合), 分组后每个分组结果集确定 再使用having过滤 select state,sum(deaths) from t_usa_covid19_p where count_date = "2021-01-28" groupby state havingsum(deaths) > 10000;
--这样写更好 即在group by的时候聚合函数已经作用得出结果 having直接引用结果过滤 不需要再单独计算一次了 select state,sum(deaths) as cnts from t_usa_covid19_p where count_date = "2021-01-28" groupby state having cnts> 10000;
在Hive 2.1.0和更高版本中,支持在“ order by”子句中为每个列指定null类型结果排序顺序。ASC顺序的默认空排序顺序为NULLS FIRST,而DESC顺序的默认空排序顺序为NULLS LAST。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
---order by --根据字段进行排序 select * from t_usa_covid19_p where count_date = "2021-01-28" and state ="California" orderby deaths; --默认asc null first
select * from t_usa_covid19_p where count_date = "2021-01-28" and state ="California" orderby deaths desc; --指定desc null last
--强烈建议将LIMIT与ORDER BY一起使用。避免数据集行数过大 --当hive.mapred.mode设置为strict严格模式时,使用不带LIMIT的ORDER BY时会引发异常。 select * from t_usa_covid19_p where count_date = "2021-01-28" and state ="California" orderby deaths desc limit3;
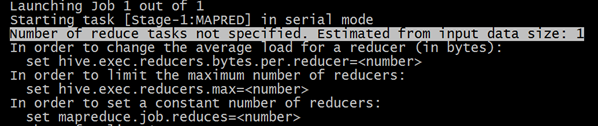
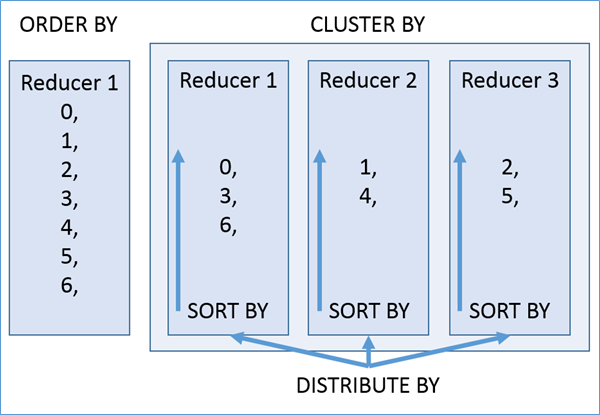
--cluster by select * from student; --不指定reduce task个数 --日志显示:Number of reduce tasks not specified. Estimated from input data size: 1 select * from student cluster by sno;
--手动设置reduce task个数 set mapreduce.job.reduces =2; select * from student cluster by sno;
--如果要将ORDER BY,SORT BY,CLUSTER BY,DISTRIBUTE BY或LIMIT应用于单个SELECT --请将子句放在括住SELECT的括号内 SELECT sno,sname FROM (select sno,sname from student_local LIMIT2) subq1 UNION SELECT sno,sname FROM (select sno,sname from student_hdfs LIMIT3) subq2
--如果要将ORDER BY,SORT BY,CLUSTER BY,DISTRIBUTE BY或LIMIT子句应用于整个UNION结果 --请将ORDER BY,SORT BY,CLUSTER BY,DISTRIBUTE BY或LIMIT放在最后一个之后。 select sno,sname from student_local UNION select sno,sname from student_hdfs orderby sno desc;
--where子句中子查询(Subqueries) --不相关子查询,相当于IN、NOT IN,子查询只能选择一个列。 --(1)执行子查询,其结果不被显示,而是传递给外部查询,作为外部查询的条件使用。 --(2)执行外部查询,并显示整个结果。 SELECT * FROM student_hdfs WHERE student_hdfs.num IN (selectnumfrom student_local limit2);
--相关子查询,指EXISTS和NOT EXISTS子查询 --子查询的WHERE子句中支持对父查询的引用 SELECT A FROM T1 WHEREEXISTS (SELECT B FROM T2 WHERE T1.X = T2.Y);
--选择语句中的CTE with q1 as (select sno,sname,sage from student where sno = 95002) select * from q1;
-- from风格 with q1 as (select sno,sname,sage from student where sno = 95002) from q1 select *;
-- chaining CTEs 链式 with q1 as ( select * from student where sno = 95002), q2 as ( select sno,sname,sage from q1) select * from (select sno from q2) a;
-- union案例 with q1 as (select * from student where sno = 95002), q2 as (select * from student where sno = 95004) select * from q1 unionallselect * from q2;
--视图,CTAS和插入语句中的CTE -- insert createtable s1 like student;
with q1 as ( select * from student where sno = 95002) from q1 insert overwrite table s1 select *;
select * from s1;
-- ctas createtable s2 as with q1 as ( select * from student where sno = 95002) select * from q1;
-- view createview v1 as with q1 as ( select * from student where sno = 95002) select * from q1;
SELECT a.* FROM a JOIN b ON (a.id = b.id) SELECT a.* FROM a JOIN b ON (a.id = b.id AND a.department = b.department) SELECT a.* FROM a LEFTOUTERJOIN b ON (a.id <> b.id)
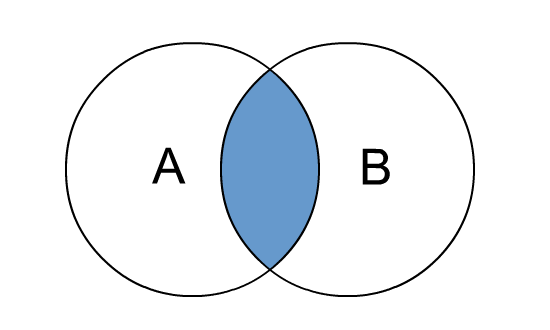
--1、inner join select e.id,e.name,e_a.city,e_a.street from employee e innerjoin employee_address e_a on e.id =e_a.id; --等价于 inner join=join select e.id,e.name,e_a.city,e_a.street from employee e join employee_address e_a on e.id =e_a.id;
--等价于 隐式连接表示法 select e.id,e.name,e_a.city,e_a.street from employee e , employee_address e_a where e.id =e_a.id;
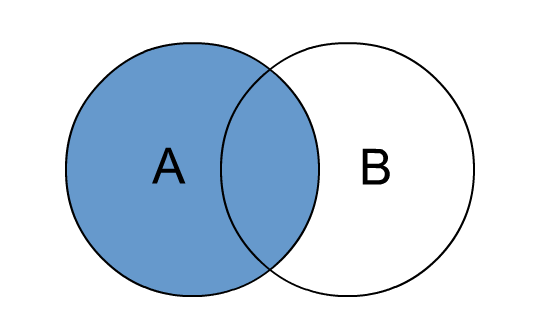
Hive left join
left join中文叫做是左外连接(Left Outer Jion)或者左连接,其中outer可以省略,left outer join是早期的写法。
--3、right join select e.id,e.name,e_conn.phno,e_conn.email from employee e rightjoin employee_connection e_conn on e.id =e_conn.id;
--等价于 right outer join select e.id,e.name,e_conn.phno,e_conn.email from employee e rightouterjoin employee_connection e_conn on e.id =e_conn.id;
Hive full outer join
full outer join 等价 full join ,中文叫做全外连接或者外连接。包含左、右两个表的全部行,不管另外一边的表中是否存在与它们匹配的行 在功能上,它等价于对这两个数据集合分别进行左外连接和右外连接,然后再使用消去重复行的操作将上述两个结果集合并为一个结果集。
1 2 3 4 5 6 7 8
--4、full outer join select e.id,e.name,e_a.city,e_a.street from employee e fullouterjoin employee_address e_a on e.id =e_a.id; --等价于 select e.id,e.name,e_a.city,e_a.street from employee e fulljoin employee_address e_a on e.id =e_a.id;
--6、cross join --下列A、B、C 执行结果相同,但是效率不一样: --A: select a.*,b.* from employee a,employee_address b where a.id=b.id; --B: select * from employee a crossjoin employee_address b on a.id=b.id; select * from employee a crossjoin employee_address b where a.id=b.id;
--C: select * from employee a innerjoin employee_address b on a.id=b.id;
SELECT a.* FROM a JOIN b ON (a.id = b.id) SELECT a.* FROM a JOIN b ON (a.id = b.id AND a.department = b.department) SELECT a.* FROM a LEFTOUTERJOIN b ON (a.id <> b.id)
b) 同一查询中可以连接2个以上的表
1
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
c) 如果每个表在联接子句中使用相同的列,则Hive将多个表上的联接转换为单个MR作业
1 2 3 4
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1) --由于联接中仅涉及b的key1列,因此被转换为1个MR作业来执行 SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2) --会转换为两个MR作业,因为在第一个连接条件中使用了b中的key1列,而在第二个连接条件中使用了b中的key2列。第一个map / reduce作业将a与b联接在一起,然后将结果与c联接到第二个map / reduce作业中。
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1) --由于联接中仅涉及b的key1列,因此被转换为1个MR作业来执行,并且表a和b的键的特定值的值被缓冲在reducer的内存中。然后,对于从c中检索的每一行,将使用缓冲的行来计算联接。 SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2) --计算涉及两个MR作业。其中的第一个将a与b连接起来,并缓冲a的值,同时在reducer中流式传输b的值。 在第二个MR作业中,将缓冲第一个连接的结果,同时将c的值通过reducer流式传输。
SELECT/*+ STREAMTABLE(a) */ a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1) --a,b,c三个表都在一个MR作业中联接,并且表b和c的键的特定值的值被缓冲在reducer的内存中。然后,对于从a中检索到的每一行,将使用缓冲的行来计算联接。如果省略STREAMTABLE提示,则Hive将流式传输最右边的表。
f) join在WHERE条件之前进行。
g) 如果除一个要连接的表之外的所有表都很小,则可以将其作为仅map作业执行
1 2
SELECT/*+ MAPJOIN(b) */ a.key, a.value FROM a JOIN b ON a.key = b.key --不需要reducer。对于A的每个Mapper,B都会被完全读取。限制是不能执行FULL / RIGHT OUTER JOIN b。