Hive 客户端使用
HiveServer、HiveServer2 服务
HiveServer、HiveServer2 都是 Hive 自带的两种服务,允许客户端在不启动 CLI 的情况下对 Hive 中的数据进行操作,且两个都允许远程客户端使用多种编程语言如 Java,Python 等向 Hive 提交请求,取回结果。
但是,HiveServer 不能处理多于一个客户端的并发请求。因此在 Hive-0.11.0 版本中重写了 HiveServer 代码得到了 HiveServer2,进而解决了该问题。HiveServer 已经被废弃。
HiveServer2 支持多客户端的并发和身份认证,旨在为开放 API 客户端如 JDBC、ODBC 提供更好的支持。
Hive Client、Hive Beeline Client
Hive 发展至今,总共历经了两代客户端工具。
第一代客户端(deprecated不推荐使用) :
$HIVE_HOME/bin/hive, 是一个 shellUtil。至多只能存在一个 hive shell 来操作 Hive,启动第二个会被阻塞,不支持并发操作。它的主要功能有两个:
- 用于以
交互式或批处理模式运行 Hive 查询,并且能够访问的是 Hive metastore 服务,而不是 hiveserver2 服务。 - 用于 Hive 相关服务的启动,比如 metastore 服务。
- 用于以
第二代客户端(recommended 推荐使用) :
$HIVE_HOME/bin/beeline,是一个 JDBC 客户端,是官方强烈推荐使用的 Hive 命令行工具,和第一代客户端相比,性能加强安全性提高。
Beeline Shell 在嵌入式模式和远程模式下均可工作。在嵌入式模式下,它运行嵌入式 Hive(类似于Hive Client),而远程模式下 beeline 通过 Thrift 连接到单独的 HiveServer2 服务上,这也是官方推荐在生产环境中使用的模式。
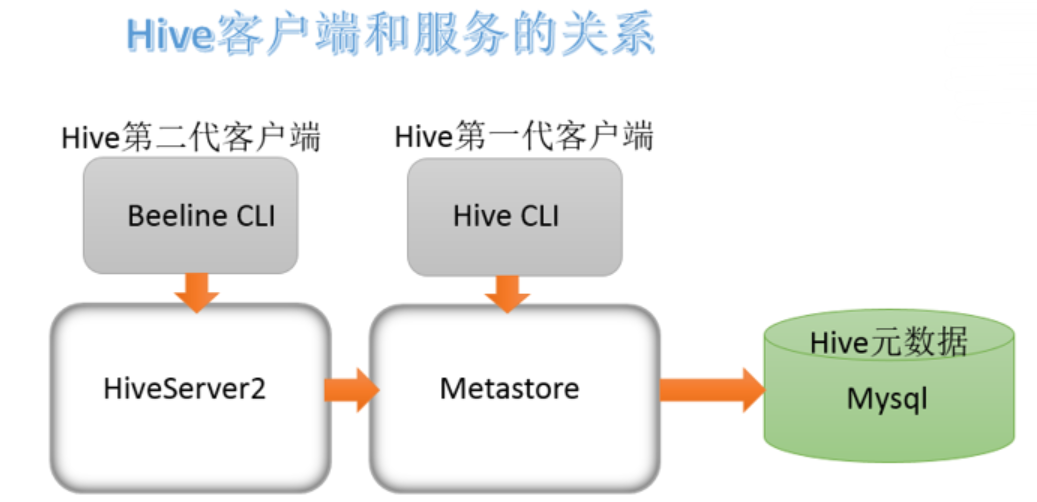
Hive 服务和客户端关系梳理
HiveServer2 通过 Metastore 服务读写元数据。所以在远程模式下,启动 HiveServer2 之前必须先首先启动 metastore 服务。
特别注意:远程模式下,Beeline 客户端只能通过 HiveServer2 服务访问 Hive。而 Hive Client 是通过 Metastore 服务访问的。具体关系如下:
Hive Client 使用
在 Hive 安装包的 bin 目录下,有 Hive 提供的第一代客户端 bin/hive。该客户端可以访问 Hive 的 metastore 服务,从而达到操作 Hive 的目的。
提示:如果远程模式部署,手动启动运行 metastore 服务。如果是内嵌模式和本地模式,直接运行 bin/hive,metastore 服务会内嵌一起启动。
可以直接在启动 Hive metastore 服务的机器上使用 bin/hive 客户端操作,此时不需要进行任何配置。
1 | |
需要在其他机器上通过 bin/hive 访问 Hive metastore 服务,只需要在该机器的 hive-site.xml 配置中添加 metastore 服务地址即可。
1 | |
Hive Beeline Client 使用
Hive 经过发展,推出了第二代客户端 beeline,但是 beeline 客户端不是直接访问metastore服务的,而是 需要单独启动hiveserver2服务。
在 Hive 运行的服务器上,首先启动 metastore 服务,然后启动 hiveserver2 服务。
1 | |
在 node3 上使用 beeline 客户端进行连接访问。需要注意 hiveserver2 服务启动之后需要稍等一会才可以对外提供服务。
Beeline 是 JDBC 的客户端,通过 JDBC 协议和 Hiveserver2 服务进行通信,协议的地址是:jdbc:hive2://node1:10000
1 | |
beeline支持的参数非常多,可以通过官方文档进行查询
Hive 和 SQL 的区别
Hive SQL语法和标准SQL很类似,使得学习成本降低不少。
Hive底层是通过MapReduce执行的数据插入动作,所以速度慢。
如果大数据集这么一条一条插入的话是非常不现实的,成本极高。
Hive应该具有自己特有的数据插入表方式,结构化文件映射成为表。
将结构化数据映射成为表
在 Hive 中,使用 insert+values 语句插入数据,底层是通过 MapReduce 执行的,效率十分低下。此时回到 Hive 的本质上:可以将结构化的数据文件映射成为一张表,并提供基于表的SQL查询分析。
在 Hive 中创建一张表 t_user。注意:字段的类型顺序要和文件中字段保持一致。
在hive中创建表跟结构化文件映射成功,需要注意以下几个方面问题:
创建表时,字段顺序、字段类型要和文件中保持一致。
如果类型不一致,hive会尝试转换,但是不保证转换成功。不成功显示null。
文件好像要放置在Hive表对应的HDFS目录下,其他路径可以吗?
建表的时候好像要根据文件内容指定分隔符,不指定可以吗?
Hive底层的确是通过MapReduce执行引擎来处理数据的
执行完一个MapReduce程序需要的时间不短
如果是小数据集,使用hive进行分析将得不偿失,延迟很高
如果是大数据集,使用hive进行分析,底层MapReduce分布式计算,很爽