1 概述 如同RDBMS中标准SQL语法一样,Hive SQL内建了不少函数,用于满足户在不同场合下的数据分析需求,提高开发SQL数据分析的效率。
可以使用show functions查看当下版本支持的函数,并且可以通过describe function extended funcname来查看函数的使用方式和方法。
1 2 3 4 describe function year ;describe function extended year ;
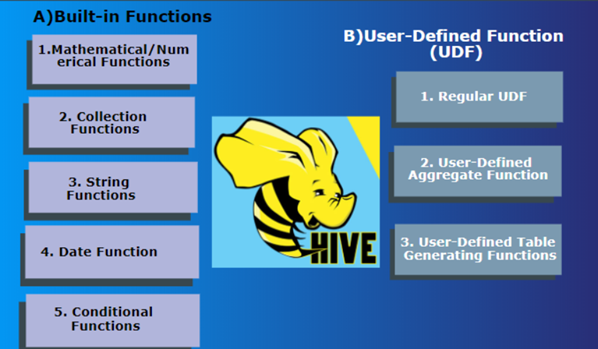
Hive的函数很多,除了自己内置所支持的函数之外,还支持用户自己定义开发函数。
内置函数根据应用归类整体可以分为以下8大种类型:
字符串类型函数(String Functions)
日期类型函数(Date Functions)
数学函数(Mathematical Functions)
集合函数(Collection Functions)
条件函数(Conditional Functions)
类型转换函数(Type Conversion Functions)
数据脱敏函数(Data Masking Functions)
其他杂项函数(Misc. Functions)
用户自定义函数(UDF,user-defined function)根据函数的输入输出行数共分为三类:
普通函数(UDF,User-Defined-Function),一进一出
聚合函数(UDAF,User-Defined Aggregation Function),多进一出
表生成函数(UDTF,User-Defined Table-Generating Functions),一进多出
虽然UDF(用户自定义函数)的命名主要指用户编写的函数,但这种分类标准实际上可以扩展到所有Hive函数,包括内置函数和自定义函数。
无论函数的类型如何,只要符合输入输出的要求,就可以根据输入和输出的行数进行分类。因此,不应被“用户自定义”这个标签所限制,例如,Hive官方文档中关于聚合函数的标准就是基于内置的UDAF类型。
2 内置函数 2.1 字符串类型函数(String Functions) 主要针对字符串数据类型进行操作,比如下面这些:
字符串长度函数:length
字符串反转函数:reverse
字符串连接函数:concat
带分隔符字符串连接函数:concat_ws
字符串截取函数:substr,substring
字符串转大写函数:upper,ucase
字符串转小写函数:lower,lcase
去空格函数:trim
左边去空格函数:ltrim
右边去空格函数:rtrim
正则表达式替换函数:regexp_replace
正则表达式解析函数:regexp_extract
URL 解析函数:parse_url
json 解析函数:1 2 3 get_json_object(json_txt, path ) - Extract a json object from path 1 个参数:指定要解析的JSON 字符串2 个参数:指定要返回的字段,通过$.columnName的方式来指定path
空格字符串函数:space
重复字符串函数:repeat
首字符ascii函数:ascii
左补足函数:lpad
右补足函数:rpad
分割字符串函数: split
集合查找函数: find_in_set
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 select length ("angelababy" );select reverse ("angelababy" );select concat ("angela" ,"baby" );select concat_ws ('.' , 'www' , array ('itcast' , 'cn' ));select substr ("angelababy" ,-2 ); select substr ("angelababy" , 2 , 2 ); select upper ("angelababy" );select ucase ("angelababy" );select lower ("ANGELABABY" );select lcase ("ANGELABABY" );select trim (" angelababy " );select ltrim (" angelababy " );select rtrim (" angelababy " );select regexp_replace('100-200' , '(\\d+)' , 'num' );select regexp_extract('100-200' , '(\\d+)-(\\d+)' , 2 );select parse_url('http://www.itcast.cn/path/p1.php?query=1' , 'HOST' );WITH t AS (SELECT '{"store":{"bicycle":{"price":19.95,"color":"red"}},' ||'"email":["amy@only_for_json_udf_test.net"],' ||'"owner":"amy"}' AS json SELECT get_json_object(t.json, '$.owner' ) FROM t UNION ALL SELECT get_json_object(t.json, '$.email[0]' ) FROM t UNION ALL SELECT get_json_object(t.json, '$.store.bicycle.price' ) FROM t SELECT get_json_object('[["123", "管理体系"]]' , '$[0][0]' ); select space (4 );select repeat ("angela" ,2 );select ascii ("angela" ); select lpad ('hi' , 5 , '??' ); select lpad ('hi' , 1 , '??' ); select rpad('hi' , 5 , '??' ); select rpad('hi' , 1 , '??' ); select split ('apache hive' , '\\s+' );select find_in_set('b' ,'abc,b,ab,c,def' );describe function extended find_in_set;
2.2 日期函数(Date Functions) 主要针对时间、日期数据类型进行操作,比如下面这些:
获取当前日期: current_date
获取当前时间戳: current_timestamp
UNIX时间戳转日期函数: from_unixtime
获取当前UNIX时间戳函数: unix_timestamp
日期转UNIX时间戳函数: unix_timestamp
指定格式日期转UNIX时间戳函数: unix_timestamp
抽取日期函数: to_date
日期转年函数: year
日期转月函数: month
日期转天函数: day
日期转小时函数: hour
日期转分钟函数: minute
日期转秒函数: second
日期转周函数: weekofyear
日期比较函数: datediff
日期增加函数: date_add
日期减少函数: date_sub
日期差值函数: datediff
计算日期之间的月份差: months_between
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 select current_date (); select current_timestamp (); select unix_timestamp (); select unix_timestamp ("2024-09-02 12:45:20" ); select unix_timestamp ('20240902 12:45:20' ,'yyyyMMdd HH:mm:ss' ); select from_unixtime(1725281120 ); select from_unixtime(0 , 'yyyy-MM-dd HH:mm:ss' ); select to_date ('2009-07-30 04:17:52' );select year ('2009-07-30 04:17:52' );select month ('2009-07-30 04:17:52' );select day ('2009-07-30 04:17:52' );select hour ('2009-07-30 04:17:52' );select minute ('2009-07-30 04:17:52' );select second ('2009-07-30 04:17:52' );select weekofyear ('2009-07-30 04:17:52' );select datediff ('2012-12-08' ,'2012-05-09' );select date_add ('2012-02-28' ,10 );select date_sub ('2012-01-1' ,10 );SELECT datediff ('2023-03-21' , '2023-03-20' );SELECT datediff (to_date ('2023-03-20 20:02:02' ), to_date ('2023-03-15 20:02:02' ));SELECT ceil (months_between(end_date, start_date)) AS num_monthsFROM (select '2020-01-01' as start_date,'2020-03-05' as end_dateselect date_add (start_date, pos) as mid_date,from (select '2020-01-01' as start_date,'2020-03-05' as end_datelateral view posexplode(split (space (datediff (end_date, start_date)), '' )) t as pos, valselect from (select CONCAT (YEAR (start_date), '-' , LPAD (MONTH (start_date), 2 , '0' )) AS start_month,CONCAT (YEAR (end_date), '-' , LPAD (MONTH (end_date), 2 , '0' )) AS end_month,CONCAT (YEAR (add_months(start_date, pos)), '-' , LPAD (MONTH (add_months(start_date, pos)), 2 , '0' )) as mid_month,from (select '2020-01-30' as start_date,'2023-05-01' as end_datelateral view posexplode(split (space (CAST (ceil (months_between(end_date, start_date)) AS INT )), '' )) t as pos, valWHERE start_month <= mid_month AND mid_month <= end_month
2.3 数学函数(Mathematical Functions) 主要针对数值类型的数据进行数学计算,比如下面这些:
取整函数: round
指定精度取整函数: round
向下取整函数: floor
向上取整函数: ceil
取随机数函数: rand
二进制函数: bin
进制转换函数: conv
绝对值函数: abs
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 select round (3.1415926 ); select round (3.1415926 ,4 ); select floor (3.1415926 ); select floor (-3.1415926 ); select ceil (3.1415926 ); select ceil (-3.1415926 ); select rand ();select rand (2 ); select bin (18 );select conv (17 , 10 , 16 ); select abs (-3.9 );
2.4 集合函数(Collection Functions) 主要针对集合这样的复杂数据类型进行操作,比如下面这些:
集合元素size函数: size(Map<K.V>) size(Array<T>)
取map集合keys函数: map_keys(Map<K.V>)
取map集合values函数: map_values(Map<K.V>)
判断数组是否包含指定元素: array_contains(Array<T>, value)
数组排序函数:sort_array(Array<T>)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 select size (array (11 ,22 ,33 )); select size (map ("id" ,10086 ,"name" ,"zhangsan" ,"age" ,18 )); select map_keys(map ("id" ,10086 ,"name" ,"zhangsan" ,"age" ,18 )); select map_values(map ("id" ,10086 ,"name" ,"zhangsan" ,"age" ,18 )); select array_contains(array (11 ,22 ,33 ),11 ); select array_contains(array (11 ,22 ,33 ),66 ); select sort_array(array (12 ,2 ,32 ));
2.5 条件函数(Conditional Functions) 主要用于条件判断、逻辑判断转换这样的场合,比如:
if条件判断: if(boolean testCondition, T valueTrue, T valueFalseOrNull)
空判断函数: isnull(a)
非空判断函数: isnotnull(a)
空值转换函数: nvl(T value, T default_value)
非空查找函数: COALESCE(T v1, T v2, ...)
条件转换函数: 用于实现对数据的判断,根据条件返回不同的结果,类似于Java中的switch case 功能1 2 3 CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END CASE WHEN 条件1 THEN VALUE1 ... WHEN 条件N THEN VALUEN ELSE 默认值 END CASE 列 WHEN V1 THEN VALUE1 ... WHEN VN THEN VALUEN ELSE 默认值 END
nullif(a, b): 如果a = b,则返回NULL;否则返回NULL。否则返回一个assert_true: 如果’condition’不为真,则引发异常,否则返回null
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 select if (1 =2 , 100 , 200 ); select `name` , if (sex ='男' , 'M' , 'W' ) from itheima.student limit 3 ;select isnull ("allen" ); select isnull (null ); select isnotnull("allen" ); select isnotnull(null ); select nvl("allen" ,"itcast" ); select nvl(null ,"itcast" ); select COALESCE (null ,11 ,22 ,33 ); select COALESCE (null ,null ,null ,33 ); select COALESCE (null ,null ,null ); select case when 50 > 100 then 'tom' when 100 = 100 then 'mary' else 'tim' end ; select `name` case `sex` when '男' then 'man' when '女' then 'women' else 'unknow' end AS sex_enfrom itheima.student;select nullif (11 , 11 ); select nullif (11 , 12 ); SELECT assert_true(11 >= 0 ); SELECT assert_true(-1 >= 0 );
2.6 类型转换函数(Type Conversion Functions) 主要用于显式的数据类型转换,有下面两种函数:
任意数据类型之间转换:cast
1 2 select cast (12.14 as bigint ); select cast (12.14 as string );
2.7 数据脱敏函数(Data Masking Functions) 主要完成对数据脱敏转换功能,屏蔽原始数据,主要如下:
1 2 3 4 5 6 * maskstring str[, int n]string str[, int n])string str[, int n])string str[, int n])string |char |varchar str)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 select mask ("abc123DEF" ); select mask ("abc123DEF" ,'-' ,'.' ,'^' ); select mask_first_n("abc123DEF" , 4 ); select mask_last_n("abc123DEF" ,4 ); select mask_show_first_n("abc123DEF" , 4 ); select mask_show_last_n("abc123DEF" , 4 ); select mask_hash("abc123DEF" );
2.8 其他杂项函数(Misc. Functions)
hive调用java方法: java_method(class, method[, arg1[, arg2..]])
反射函数: reflect(class, method[, arg1[, arg2..]])
取哈希值函数:hash
current_user()、logged_in_user()、current_database()、version()SHA-1加密: sha1(string/binary)
SHA-2家族算法加密:sha2(string/binary, int) (SHA-224, SHA-256, SHA-384, SHA-512)
crc32加密:
MD5加密: md5(string/binary)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 select java_method("java.lang.Math" , "max" , 11 , 22 ); select reflect("java.lang.Math" ,"max" , 11 , 22 ); select hash ("allen" ); select sha1 ("allen" ); select sha2 ("allen" ,224 ); select sha2 ("allen" ,512 ); select crc32 ("allen" ); select md5 ("allen" );
3 内置聚合函数(Built-in UDAF) UDAF函数通常称为聚合函数,A所代表的单词就是Aggregation聚合的意思。最大的特点是多进一出,也就是输入多行输出一行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 drop table student;create table studentnum int ,name string ,string ,int ,string row format delimited fields terminated by ',' LOAD DATA LOCAL INPATH '/home/hive/students.txt' INTO TABLE student;SELECT * FROM student;
3.1 基础聚合函数 HQL提供了几种内置的UDAF聚合函数,例如max,min和avg等,这些我们把它称之为基础的聚合函数。
通常情况下,聚合函数会与GROUP BY子句一起使用。 如果未指定GROUP BY子句,默认情况下,它会汇总所有行数据。下面介绍常用的聚合函数:
count:统计检索到的总行数。
sum:求和
avg:求平均
min:最小值
max:最大值
percentile: 精确计算一个数据集的百分位数,可能会消耗大量的内存和计算资源。
percentile_approx: 近似计算一个数据集的百分位数。
collect_set(col) : 数据收集函数(去重)
collect_list(col): 数据收集函数(不去重)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 select count (*) as cnt1, count (1 ) as cnt2 from itheima.student; select `sex` , count (*) as cnt from student group by sex;select count (*) as cntcount (distinct dept) AS dept_distictavg (age) as age_avgmin (age) as age_minmax (age) as age_maxsum (age) as age_sumfrom student;select avg (count (*)) from student; select max (null ), min (null ), count (null ); select sum (null ), avg (null ); select sum (coalesce (val1, 0 )) sum (coalesce (val1, 0 ) + val2) from (select 1 AS val1, 2 AS val2union all select null AS val1, 2 AS val2union all select 2 AS val1, 3 AS val2SELECT percentile(CAST (age AS BIGINT ), array (0 , 0.01 , 0.05 , 0.1 , 0.2 ,0.25 ,0.5 ,0.75 ,0.95 ))FROM student;SELECT percentile_approx(CAST (age AS BIGINT ), 0.5 , 10000 )FROM student;select collect_set(sex) from student; select collect_list(sex) from student;
3.2 增强聚合函数 增强聚合的grouping_sets、cube、rollup这几个函数主要适用于OLAP多维数据分析模式中,多维分析中的维指的分析问题时看待问题的维度、角度。下面介绍常用的函数:
Grouping sets: 一种将多个group by逻辑写在一个sql语句中的便利写法。
Cube: 根据GROUP BY的维度的所有组合进行聚合。
Rollup: Cube的子集,以最左侧的维度为主,从该维度进行层级聚合。
Grouping sets grouping sets 是一种将多个group by逻辑写在一个sql语句中的便利写法。等价于将不同维度的GROUP BY结果集进行UNION ALL。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 SELECT COUNT (DISTINCT num ) AS numsFROM studentGROUP BY sex, deptGROUPING SETS (sex, dept, (sex, dept))ORDER BY GROUPING__ID;SELECT sex, NULL , COUNT (DISTINCT num ) AS nums,1 AS GROUPING__ID FROM student GROUP BY sexUNION ALL SELECT NULL as sex, dept, COUNT (DISTINCT num ) AS nums,2 AS GROUPING__ID FROM student GROUP BY deptUNION ALL SELECT sex, dept, COUNT (DISTINCT num ) AS nums, 3 AS GROUPING__ID FROM student GROUP BY sex, dept;
Cube cube的语法功能指的是:根据GROUP BY的维度的所有组合进行聚合。((a,b,c),(a,b),(b,c),(a,c),(a),(b),(c),())。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 SELECT COUNT (DISTINCT num ) AS nums,FROM studentGROUP BY sex, deptWITH CUBE ORDER BY GROUPING__ID;SELECT NULL , NULL , COUNT (DISTINCT num ) AS nums, 0 AS GROUPING__ID FROM studentUNION ALL SELECT sex, NULL , COUNT (DISTINCT num ) AS nums,1 AS GROUPING__ID FROM student GROUP BY sexUNION ALL SELECT NULL , dept, COUNT (DISTINCT num ) AS nums,2 AS GROUPING__ID FROM student GROUP BY deptUNION ALL SELECT sex, dept, COUNT (DISTINCT num ) AS nums,3 AS GROUPING__ID FROM student GROUP BY sex, dept;
Rollup cube的语法功能指的是:根据GROUP BY的维度的所有组合进行聚合。 rollup是Cube的子集,以最左侧的维度为主,从该维度进行层级聚合。((a,b,c),(a,b),(a),())。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 SELECT COUNT (DISTINCT num ) AS nums,FROM studentGROUP BY sex, deptWITH ROLLUP ORDER BY GROUPING__ID;SELECT NULL , NULL , COUNT (DISTINCT num ) AS nums, 0 AS GROUPING__ID FROM studentUNION ALL SELECT sex, NULL , COUNT (DISTINCT num ) AS nums,1 AS GROUPING__ID FROM student GROUP BY sexUNION ALL SELECT sex, dept, COUNT (DISTINCT num ) AS nums,3 AS GROUPING__ID FROM student GROUP BY sex, dept;
4 内置表生成函数(Built-in UDTF) UDTF函数通常把它叫做表生成函数,T所代表的单词是Table-Generating表生成的意思。最大的特点是一进多出,也就是输入一行输出多行。
之所以叫做表生成函数,原因在于这类型的函数作用返回的结果类似于表(多行数据)。常用的函数有:
explode:接受一个数组(或映射)作为输入,并将数组(映射)中的元素作为单独的行输出。
posexplode:返回一个包含两列(pos, val)的行集,每个数组元素对应一行,行号从 0 开始。
json_tuple:用于一个标准的JSON字符串中,按照输入的一组键(key1,key2,…)抽取各个键指定的字符串。
Lateral View(侧视图)是一种特殊的语法,主要用于搭配UDTF类型功能的函数一起使用,用于解决UDTF函数的一些查询限制的问题。
UDTF对每个输入行产生0或者多个输出行(拆分成多行); 不加lateral view的UDTF只能提取单个字段拆分,并不能塞回原来数据表中.
侧视图的原理是将UDTF的结果构建成一个类似于视图的表,然后将原表中的每一行和UDTF函数输出的每一行进行连接,生成一张新的虚拟表。
1 2 3 Syntax:LATERAL VIEW udtf(expression) tableAlias AS columnAlias (',' columnAlias)*FROM baseTable (lateralView)*
4.1 explode explode() 接受一个数组(或映射)作为输入,并将数组(映射)中的元素作为单独的行输出。UDTFs(用户定义表生成函数)可以在 SELECT 表达式列表中使用,也可以作为 LATERAL VIEW 的一部分使用。
函数原型:
1 2 T explode(ARRAY<T > a)<br > <Tkey,Tvalue > m)<br >
使用示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 select explode (array ('A' ,'B' ,'C' ));select explode (split ('A,B,C,D' , ',' ));select explode (map ('A' ,10 ,'B' ,20 ,'C' ,30 )) as (`key` , `value` );select id , explode (split (chars, ',' ))from (select 'A,B,C,D' as chars, 1 as id ) t;select `col` from (select 'A,B,C,D' as chars, 1 as id ) tlateral view explode (split (chars, ',' )) tf as `col` ;
如果在select条件中,包含explode和其他字段,就会报错。错误信息为:
4.2 posexplode posexplode() 类似于 explode,但不仅返回数组的元素,还返回元素在原数组中的位置。
1 int ,T posexplode(ARRAY<T > a)
使用示例:
1 2 3 4 5 6 7 8 select posexplode(array ('A' ,'B' ,'C' ));select posexplode(array ('A' ,'B' ,'C' )) as (pos, val);select t.id, tf.*from (select 0 AS id ) tlateral view posexplode(array ('A' ,'B' ,'C' )) tf as pos,val;
4.3 json_tuple json_tuple() 用于一个标准的JSON字符串中,按照输入的一组键(key1,key2,…)抽取各个键指定的字符串。
函数原型:
1 string1,...,stringn json_tuple(string jsonStr ,string k1 ,... ,string kn )
使用示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 WITH t AS (SELECT '{"store":{"bicycle":{"price":19.95,"color":"red"}},' ||'"email":["amy@only_for_json_udf_test.net"],' ||'"owner":"amy"}' AS json SELECT json_tuple(t.json, 'store' , 'owner' , 'email' ) FROM tSELECT t.*, store , owner, emailFROM (SELECT '{"store":{"bicycle":{"price":19.95,"color":"red"}},' ||'"email":["amy@only_for_json_udf_test.net"],' ||'"owner":"amy"}' AS json ) tLATERAL VIEW json_tuple(t.json, 'store' , 'owner' , 'email' ) b as store , owner, email;
与get_json_object函数类似均用于解析json字符串,但json_tuple 函数一次可以解析多个 json 字段。
Lateral View 侧视图 概念 Lateral View 是一种特殊的语法,主要用于搭配UDTF类型功能的函数一起使用 ,用于解决UDTF函数的一些查询限制的问题。侧视图的原理是将UDTF的结果构建成一个类似于视图的表,然后将原表中的每一行和UDTF函数输出的每一行进行连接,生成一张新的虚拟表。这样就避免了UDTF的使用限制问题。使用lateral view时也可以对UDTF产生的记录设置字段名称,产生的字段可以用于group by、order by 、limit等语句中,不需要再单独嵌套一层子查询。一般只要使用UDTF,就会固定搭配lateral view使用。
官方链接:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+LateralView
UDTF配合侧视图使用 使用explode函数+lateral view侧视图,可以完美解决:
1 2 3 4 5 6 7 8 9 10 select …… from tabelA lateral view UDTF(xxx) 别名 as col1,col2,col3……;select a.team_name ,b.yearfrom the_nba_championship a lateral view explode (champion_year) b as year select a.team_name ,b.yearfrom the_nba_championship a lateral view explode (champion_year) b as year order by b.year desc ;
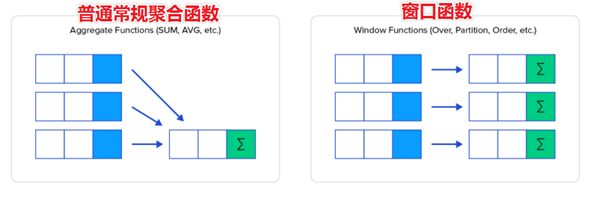
5 窗口函数(Window functions) 5.1 概述 窗口函数(Window functions)是一种SQL函数,非常适合于数据分析,因此也叫做OLAP函数。
其最大特点是:输入值是从SELECT语句的结果集中的一行或多行的“窗口”中获取的。
如果函数具有OVER子句,则它是窗口函数;如果它缺少OVER子句,则它是一个普通的聚合函数。
窗口函数可以简单地解释为类似于聚合函数的计算函数,但是通过GROUP BY子句组合的常规聚合会隐藏正在聚合的各个行,最终输出一行,窗口函数聚合后还可以访问当中的各个行,并且可以将这些行中的某些属性添加到结果集中。
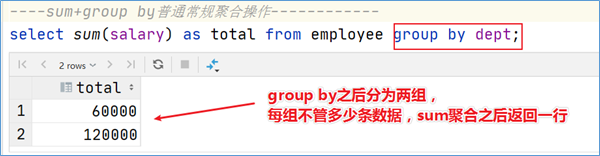
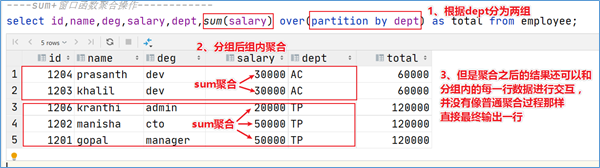
为了更加直观感受窗口函数,通过sum聚合函数进行普通常规聚合和窗口聚合,看效果。
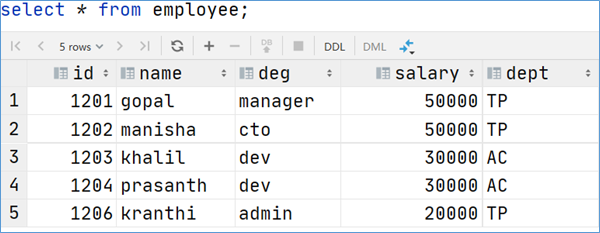
1 2 3 4 5 select sum (salary) as total from employee group by dept;select id ,name ,deg,salary,dept,sum (salary) over (partition by dept) as total from employee;
窗口函数语法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Function(arg1,..., argn) OVER ([PARTITION BY <...>] [ORDER BY <....>] [<window_expression>] )[<window_expression>]
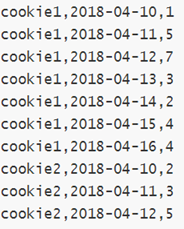
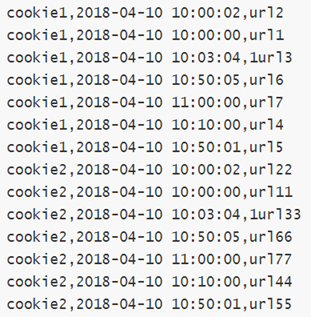
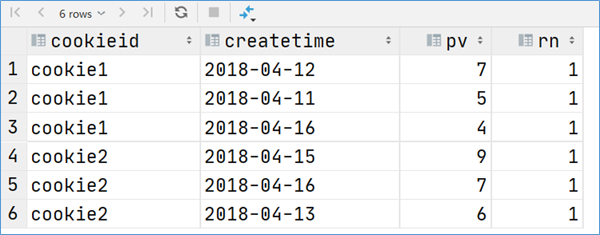
5.2 案例:网站用户页面浏览次数分析 在网站访问中,经常使用cookie来标识不同的用户身份,通过cookie可以追踪不同用户的页面访问情况。下面两份数据:
字段含义:cookieid 、访问时间、pv数(页面浏览数)
字段含义:cookieid、访问时间、访问页面url
在Hive中创建两张表表,把数据加载进去用于窗口分析。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 create table website_pv_info(string comment "cookieid" ,string comment "访问时间" ,int comment "pv数(页面浏览数)" COMMENT "website_pv_info.txt" row format delimited fields terminated by ',' ;create table website_url_info(string comment "cookieid" ,string comment "访问时间" ,url string comment "访问页面" COMMENT "website_url_info.txt" row format delimited fields terminated by ',' ;load data local inpath '/home/hive/data/website_pv_info.txt' into table website_pv_info;load data local inpath '/home/hive/data/website_url_info.txt' into table website_url_info;select * from website_pv_info;select * from website_url_info;
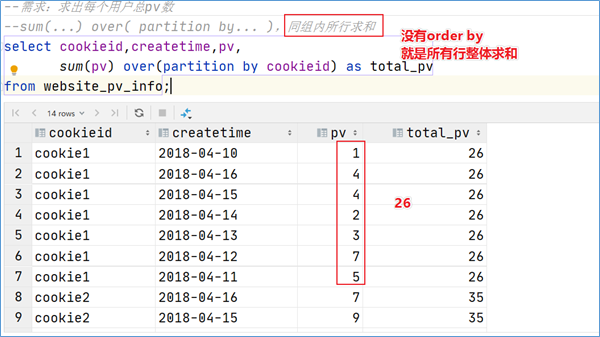
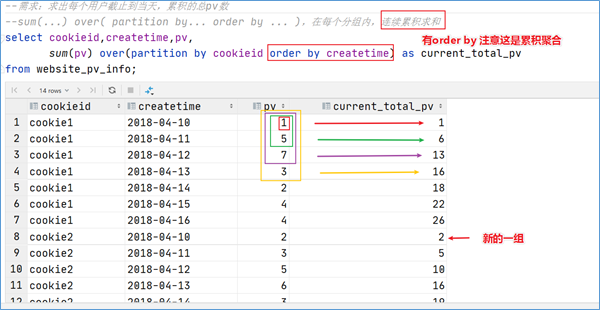
5.3 窗口聚合函数 从Hive v2.2.0开始,支持DISTINCT与窗口函数中的聚合函数一起使用。 这里以sum()函数为例,其他聚合函数使用类似。
sum()函数+窗口函数
说明
sum(…) over( )
对表所有行求和
sum(…) over( order by … )
连续累积求和
sum(…) over( partition by… )
同组内所有行求和
sum(…) over( partition by… order by … )
在每个分组内,连续累积求和
sum(…) over( partition by… order by … rows between … and …)
在每个分组内,滑动窗口求和
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 select cookieid,createtime,pv,sum (pv) over () as pv_totalfrom website_pv_info;select cookieid,createtime,pv,sum (pv) over (partition by cookieid) as pv_totalfrom website_pv_info;select cookieid,createtime,pv,sum (pv) over (partition by cookieid order by createtime) as pv_totalfrom website_pv_info;select cookieid,createtime,pvsum (pv) over (partition by cookieid order by createtime rows between 2 preceding and current row ) as pv_totalfrom website_pv_info;
5.4 窗口表达式 在sum(...) over( partition by... order by ... )语法完整的情况下,进行的累积聚合操作,默认累积聚合行为是:从第一行聚合到当前行。控制行范围的能力,比如向前2行,向后3行。
语法:
1 2 3 4 5 6 7 关键字是 rows between ,包括下面这几个选项preceding :往前following :往后current row :当前行unbounded :边界unbounded preceding 表示从前面的起点unbounded following :表示到后面的终点
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 select cookieid,createtime,pv,sum (pv) over (partition by cookieid order by createtime rows between unbounded preceding and current row ) as pv2from website_pv_info;select cookieid,createtime,pv,sum (pv) over (partition by cookieid order by createtime rows between 3 preceding and current row ) as pv4from website_pv_info;select cookieid,createtime,pv,sum (pv) over (partition by cookieid order by createtime rows between 3 preceding and 1 following ) as pv5from website_pv_info;select cookieid,createtime,pv,sum (pv) over (partition by cookieid order by createtime rows between current row and unbounded following ) as pv6from website_pv_info;select cookieid,createtime,pv,sum (pv) over (partition by cookieid order by createtime rows between unbounded preceding and unbounded following ) as pv6from website_pv_info;
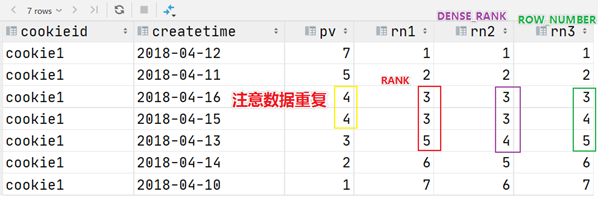
5.5 窗口排序函数 窗口排序函数用于给每个分组内的数据打上排序的标号,注意窗口排序函数不支持窗口表达式。常见的有4个函数:
row_number:在每个分组中,为每行分配一个从1开始的唯一序列号,递增,不考虑重复;
rank: 在每个分组中,为每行分配一个从1开始的序列号,考虑重复,挤占后续位置;
dense_rank: 在每个分组中,为每行分配一个从1开始的序列号,考虑重复,不挤占后续位置;
ntile:将每个分组内的数据分为指定的若干个桶里(分为若干个部分),并且为每一个桶分配一个桶编号。
1 2 3 4 5 6 7 8 9 10 11 12 13 SELECT RANK () OVER (PARTITION BY cookieid ORDER BY pv desc ) AS `RANK` ,DENSE_RANK () OVER (PARTITION BY cookieid ORDER BY pv desc ) AS `DENSE_RANK` ,OVER (PARTITION BY cookieid ORDER BY pv DESC ) AS `ROW_NUMBER` ,3 ) OVER (PARTITION BY cookieid ORDER BY pv DESC ) AS `NTILE` FROM website_pv_infoWHERE cookieid = 'cookie1' ;
三个函数用于分组TopN的场景非常适合。
1 2 3 4 5 6 7 8 SELECT * from SELECT OVER (PARTITION BY cookieid ORDER BY pv DESC ) AS seqFROM website_pv_info) tmp where tmp.seq <4 ;
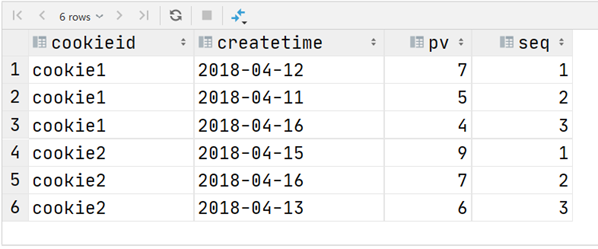
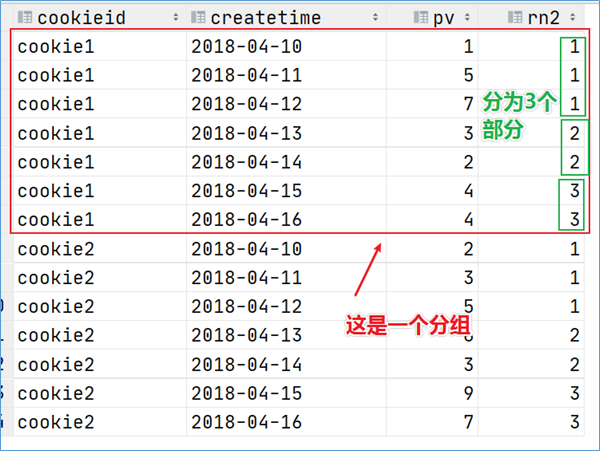
还有一个函数,叫做ntile函数 ,其功能为:将每个分组内的数据分为指定的若干个桶里(分为若干个部分),并且为每一个桶分配一个桶编号。 如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差1。有时会有这样的需求:如果数据排序后分为三部分,业务人员只关心其中的一部分,如何将这中间的三分之一数据拿出来呢?NTILE函数即可以满足。
1 2 3 4 5 6 7 8 SELECT 3 ) OVER (PARTITION BY cookieid ORDER BY createtime) AS rn2FROM website_pv_infoORDER BY cookieid,createtime;
1 2 3 4 5 6 7 8 9 SELECT * from SELECT 3 ) OVER (PARTITION BY cookieid ORDER BY pv DESC ) AS rnFROM website_pv_info) tmp where rn =1 ;
5.6 窗口分析函数
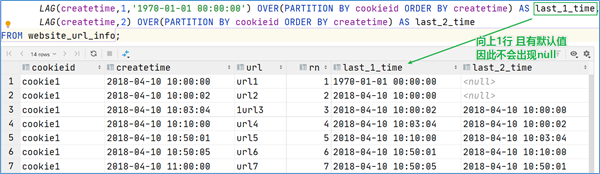
LAG(col,n,DEFAULT):用于统计窗口内往上第n行值
LEAD(col,n,DEFAULT):用于统计窗口内基于当前行数据向下偏移取第n行值
FIRST_VALUE:取分组内排序后,截止到当前行,第一个值
LAST_VALUE:取分组内排序后,截止到当前行,最后一个值
1 2 3 4 5 6 7 8 9 10 11 12 13 SELECT cookieid,url ,OVER (PARTITION BY cookieid ORDER BY createtime) AS rn,1 , '1970-01-01 00:00:00' ) OVER (PARTITION BY cookieid ORDER BY createtime) AS LAG1,2 ) OVER (PARTITION BY cookieid ORDER BY createtime) AS LAG2,LEAD (createtime, 1 , '1970-01-01 00:00:00' ) OVER (PARTITION BY cookieid ORDER BY createtime) AS LEAD1,LEAD (createtime, 2 ) OVER (PARTITION BY cookieid ORDER BY createtime) AS LEAD2,FIRST_VALUE (url ) OVER (PARTITION BY cookieid ORDER BY createtime) AS FIRST_VALUE ,LAST_VALUE (url ) OVER (PARTITION BY cookieid ORDER BY createtime) AS LAST_VALUE FROM website_url_info;
6 抽样函数(Sampling functions) 当数据量过大时,我们可能需要查找数据子集以加快数据处理速度分析和发现整个数据集中的模式和趋势。在HQL中,可以通过三种方式采样数据:
随机采样(Random)
存储桶表采样(Bucket table):这是一种特殊的采样方法,针对分桶表进行了优化。
块采样(Block):允许select随机获取n行数据,即数据大小或n个字节的数据;采样粒度是HDFS块大小。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 SELECT * FROM website_url_info SORT BY rand () LIMIT 2 ;SELECT * FROM website_url_info DISTRIBUTE BY rand () SORT BY rand () LIMIT 2 ;SELECT * FROM website_url_info ORDER BY rand () LIMIT 2 ;SELECT * FROM website_url_info TABLESAMPLE (1 ROWS );SELECT * FROM website_url_info TABLESAMPLE (50 PERCENT );SELECT * FROM website_url_info TABLESAMPLE (1 k);SELECT * FROM website_url_info TABLESAMPLE (BUCKET 1 OUT OF 2 ON rand ());describe formatted website_url_info;SELECT * FROM website_url_info TABLESAMPLE (BUCKET 1 OUT OF 2 ON `createtime` );