用户自定义函数分类
虽然说Hive内置了很多函数,但是不见得一定可以满足于用户各种各样的分析需求场景。为了解决这个问题,Hive推出来用户自定义函数功能,让用户实现自己希望实现的功能函数。用户自定义函数简称UDF,源自于英文user-defined function。
自定义函数总共有3类,是根据函数输入输出的行数来区分的,分别是:
- UDF(User-Defined-Function)普通函数,一进一出
- UDAF(User-Defined Aggregation Function)聚合函数,多进一出
- UDTF(User-Defined Table-Generating Functions)表生成函数,一进多出
UDF分类标准扩大化
UDF叫做用户自定义函数,其分类标准主要针对的是用户编写开发的函数。但是这套UDF分类标准可以扩大到Hive的所有函数中:包括内置函数和自定义函数。因为不管是什么类型的行数,一定满足于输入输出的要求,那么从输入几行和输出几行上来划分没有任何毛病。千万不要被UD(User-Defined)这两个字母所迷惑,照成视野的狭隘。比如Hive官方文档中,针对聚合函数的标准就是内置的UDAF类型。

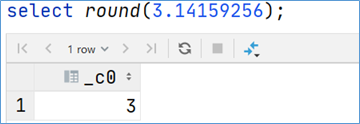
UDF 普通函数
UDF函数通常把它叫做普通函数,最大的特点是一进一出,也就是输入一行输出一行。比如round这样的取整函数,接收一行数据,输出的还是一行数据。
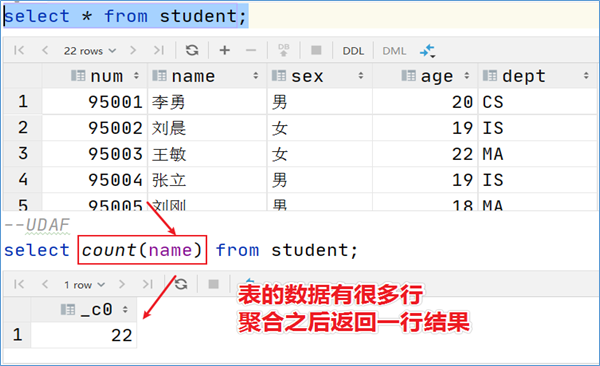
UDAF 聚合函数
UDAF函数通常把它叫做聚合函数,A所代表的单词就是Aggregation聚合的意思。最大的特点是多进一出,也就是输入多行输出一行。比如count、sum这样的函数。
1
2
3
4
5
6
7
| •count:统计检索到的总行数。
•sum:求和
•avg:求平均
•min:最小值
•max:最大值
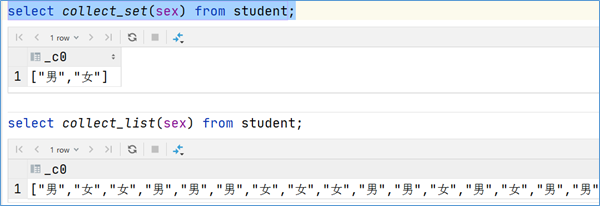
•数据收集函数(去重): collect_set(col)
•数据收集函数(不去重): collect_list(col)
|
1
2
3
4
| select sex from student;
select collect_set(sex) from student;
select collect_list(sex) from student;
|
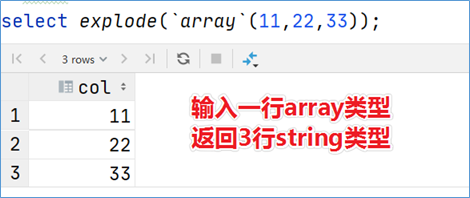
UDTF 表生成函数
UDTF函数通常把它叫做表生成函数,T所代表的单词是Table-Generating表生成的意思。最大的特点是一进多出,也就是输入一行输出多行。之所以叫做表生成函数,原因在于这类型的函数作用返回的结果类似于表(多行数据嘛),同时,UDTF函数也是接触比较少的函数,陌生。比如explode函数。
案例:用户自定义UDF
在企业中处理数据的时候,对于敏感数据往往需要进行脱敏处理。比如手机号。我们常见的处理方式是将手机号中间4位进行****处理。Hive中没有这样的函数可以直接实现功能,虽然可以通过各种函数的嵌套调用最终也能实现,但是效率不高,现要求自定义开发实现Hive函数,满足上述需求。
1、 能够对输入数据进行非空判断、位数判断处理
2、 能够实现校验手机号格式,把满足规则的进行****处理
3、 对于不符合手机号规则的数据原封不动不处理
实现步骤
通过业务分析,可以发现我们需要实现的函数是一个输入一行输出一行的函数,也就是所说的UDF普通函数。
根据Hive当中的UDF开发规范,实现步骤如下:
1、 写一个java类,继承UDF,并重载evaluate方法;
2、 程序打成jar包,上传服务器添加到hive的classpath;hive>add JAR /home/hadoop/udf.jar;
3、 注册成为临时函数(给UDF命名);create temporary function 函数名 as ‘UDF类全路径’;
4、 使用函数
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| <dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.4</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.2</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
|
业务代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| package cn.dsjprs.hive.udf;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.hive.ql.exec.UDF;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class EncryptPhoneNumber extends UDF {
public String evaluate(String phoNum){
String encryptPhoNum = null;
if (StringUtils.isNotEmpty(phoNum) && phoNum.trim().length() == 11 ) {
String regex = "^(1[3-9]\\d{9}$)";
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(phoNum);
if (m.matches()) {
encryptPhoNum = phoNum.trim().replaceAll("()\\d{4}(\\d{4})","$1****$2");
}else{
encryptPhoNum = phoNum;
}
}else{
encryptPhoNum = phoNum;
}
return encryptPhoNum;
}
}
|