联邦学习优缺点
近年来,联邦学习的热度在逐渐的升温,主要有几方面的因素:
- 端和边缘设备越来越普及,算力也有所提升。这个趋势随着智能汽车,VR,IoT等的发展,估计还会持续下去。
- 隐私合规,数据保护成为大公司绕不过去的一个门槛。不管是用户意愿,政府法规,还是公司间合作,对于数据的保护越来越重视。
- 其他方面,比如个性化模型,数据中心成本等等。
其中第二条尤其关键:
- iOS加强隐私后,很多用户手机上的数据无法被采集。
- 国家常常会要求数据不能离开本国。
- 合作的公司要求数据不能离开各自的数据中心。
因此,传统集中数据后进行训练的范式在这些场景下就变得不可行。
联邦学习简介
Federated learning is a machine learning setting where multiple entities (clients) collaborate in solving a machine learning problem, under the coordination of a central server or service provider. Each client’s raw data is stored locally and not exchanged or transferred; instead, focused updates intended for immediate aggregation are used to achieve the learning objective.
联邦学习经过发展,出现了一些变种,常见的有:
- cross device。这是最初定义的,面向的是海量边缘设备。
- cross silo。这也是常见的情况,比如两个公司合作(或者大公司两个部门合作),或者一个公司多个国家的数据。参与者更少,每个参与者更加稳定,拥有更多的算力。但是依然受到数据本地化的限制。
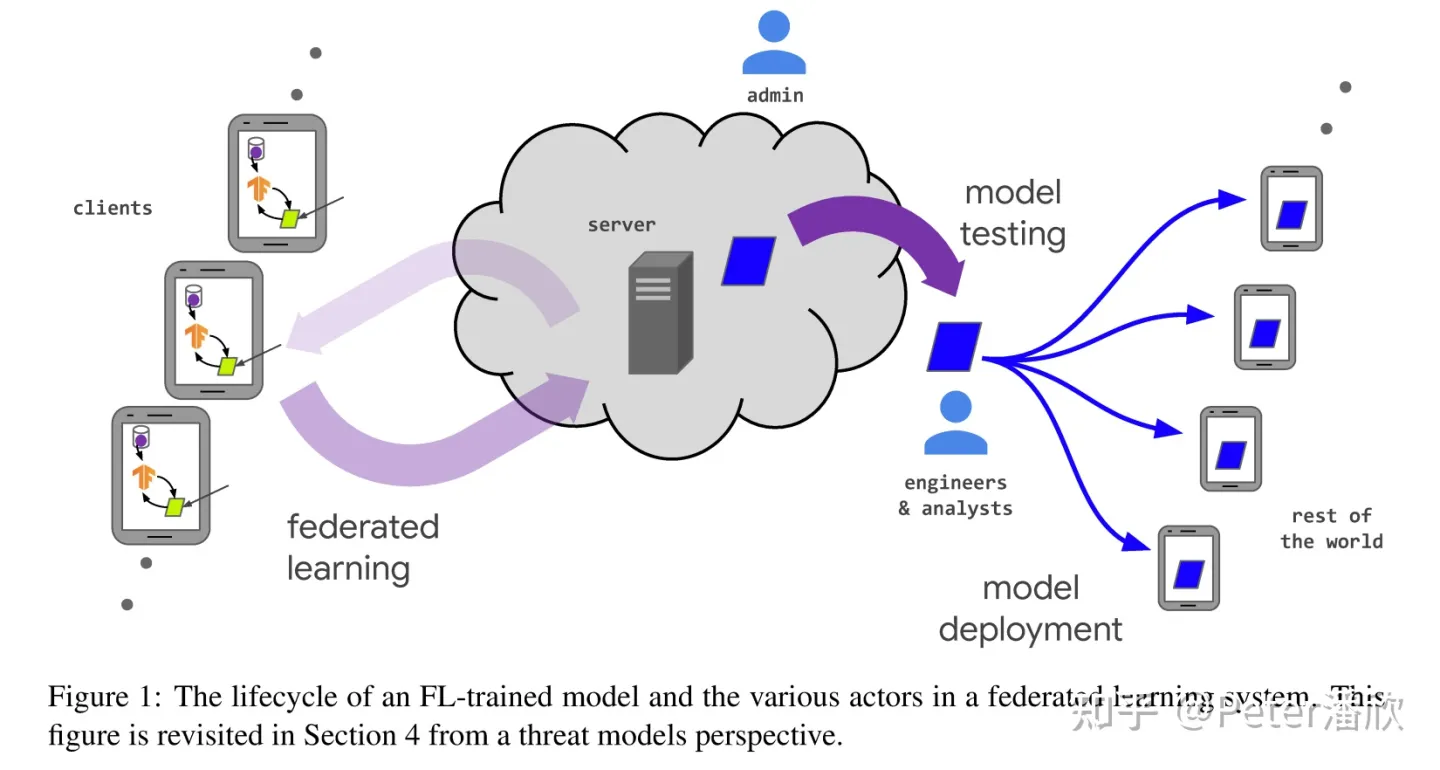
一个经典的联邦学习的过程如上图所示:
- 从海量的设备上选择一部分参与联邦学习。条件可能是算力足够,插上电源,网络稳定等。
- 后台将需要被训练的模型推送到这些被选中的设备上。
- 被选中的设备基于本地的数据进行本地训练,获得更新后的模型。
- 将更新的模型推送到后台,后台对这些模型进行聚合,得到汇总的新模型。
如果我们放松“后台coordinator”的限制,这个过程可能会变成P2P的训练,这里不进一步讨论。
挑战
联邦学习作为一个相对新热的技术,还有许多问题需要解决,才能获得普遍是应用。
效果问题
Non-IID数据问题。传统训练要求数据符合IID分布,通常采集数据后进行充分shuffle就可以了。但是联邦学习时每个设备背后的用户都不一样,设备上的数据也非常有限。因此各个设备上的训练显然是不符合IID要求的,比如:
- 特征分布,比如不同人的肤色不一样,写字字体不一样等。
- 标签分布,比如袋鼠通常只出现在澳洲,富人在乡村相对少等。
- 同样标签,不同特征。比如虽然都是房子,中东的房子和日韩的房子外貌差异很大。
- 同样特征,不同标签。比如在预测“最好吃的食物是XX”,在不同地域的预测结果是不一样的。
- 样本量差异。APP的重度用户和轻度用户的样本量差异较大。
这些因素,都可能导致传统基于IID的训练收敛理论失效,导致模型效果发生意料之外的结果。
另外一个是优化算法的收敛性问题,联邦学习中使用FedAvg和传统训练使用的SGD,ADAM有不少的差异,另外客户端数量(下表的M)也有较大的差异。基于Convex假设分析和Non-Convex都有不少差异。
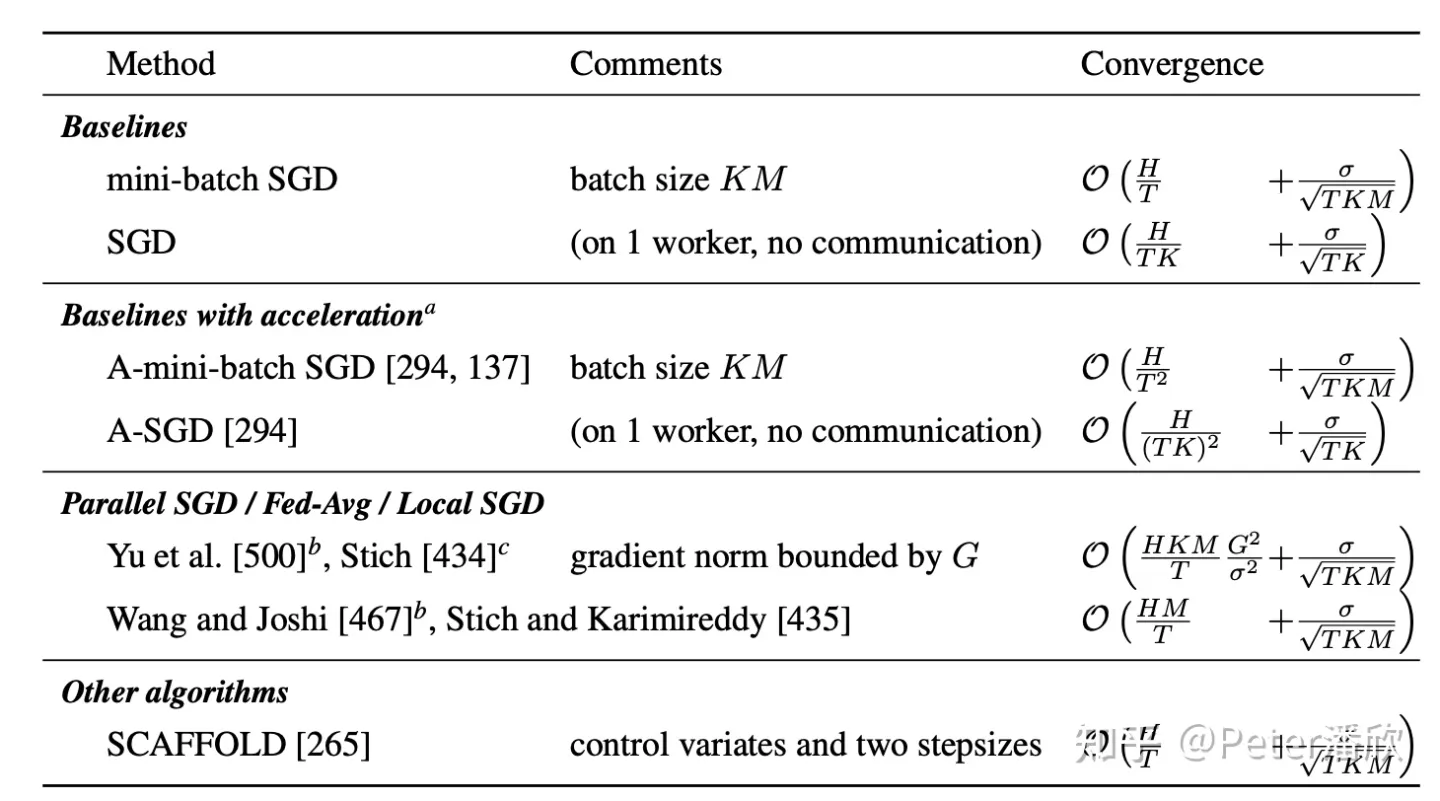
结合NonIID和分布式优化的调整,训练的收敛性分析还有很多工作需要做。
从当前训练技术中也有不少潜在解决方案是可以借鉴的,比如:
- 个性化。假如每个用户的数据分布是NonIID的,那么我们是否更应该为每个用户设计个性化的模型,这个问题就没有了?比如,将不同相似用户群建模成不同的task,利用multi-task learning。或者基于基模型,在各个用户设备上进行fine-tunning等。
- 元学习。元学习的优化方向是”跟快的适应“。那么,基于元学习的优化策略,结合个性化是否会有比较好的效果。
或许伴随着联邦学习,传统全局模型的one-fits-all的范式也需要改变。
性能问题
由于模型的训练和部署都不在后台数据中心,整个ML workflow上的挑战会更多。通常DeepLearning模型的训练有非常多的超参数需要调整,甚至要使用NAS,HPO这种技术进行海量的搜索。但是如果模型的主要计算在海量用户设备上,传统的搜索方式也需要有较多的改进。
另一个问题是通信压缩。传统数据中心内的训练,带宽通常非常大,也没有很多通信费用问题。但是再联邦学习场景,通信可能需要经过广域网。可能会涉及网络稳定性,延迟,带宽,费用等各种问题。需要对通信进行压缩,比如:
- 模型参数,梯度量化压缩。
- 模型结构压缩,局部模型训练。
- 面向无线模拟信号的有损压缩等。
隐私问题
作为联邦学习的初衷之一,需要保护用户的数据隐私。数据隐私可能被破坏的地方非常多,通常需要Privacy In Depth的思想,充分考虑各个Actor, Actor Threat Model。

常见的一些隐私保护技术可以应用在上图描述的环节中:
- Secure Multi-Party Computation。比如Homomorphic Encryption可以让多个参与方完成各自的计算,但是不需要解密输入,保障输入的数据不会被计算中泄露出去。
- Trusted Execution Environment。可信计算环境可以保障环境中完成的计算符合一些要求。1. Confidentiality,除非运行代码主动,数据不会被泄露出去。2. Integrity,代码的运算不被外部干扰,除非代码主动读取。3. Attestation,对外证明被运行的代码是预期中的。
- Zero Knowledge Proofs。对外部证明自己完成了隐私计算,而不需要泄露数据本身的细节。
- Differential Privacy。通过在训练过程中注入一些干扰信号,比如高斯噪声,来防止隐私数据被重建。
- Auditing。
- Secure Shuffling & Aggregation。在后台对用户输出进行shuffle和加密的聚合,防止后台发生隐私泄露。
值得关注的是,一些隐私保护的技术可能会影响模型的训练效果。比如Differential Privacy,可能会导致模型收敛效果变差。还有一些技术会导致系统整体的调试,Debug,优化变得困难。还有一些会导致训练训练和通信的开销变大。
安全问题
深度学习的安全问题一直都比较大。比如:
- 许多研究都发现可以对在模型中安装不易发现的后门,操控模型在一些数据输入上的表现。常见的方法有Adversarial Attack。
- 另外,端上的用户可能会通过一些干扰噪音,影响模型的收敛效果。而从海量用户中挖掘这部分恶意(或者Bugggy)设备本身也是比较难的。
系统问题
前面也简单提到,联邦学习对于系统上也增加了不少挑战。
- 更新问题。如何将训练的代码,模型顺利的更新到海量设备上。
- 监控和调试。如何发现部署的问题,特别是缺少数据和设备环境的情况下,复现本身就是一大挑战。
- 设备Bias。如何选择参与的设备,防止出现训练上的Bias。比如,如果低端手机不参加计算,是否会导致对应用户的Bias。
- 设备上运行时。为了在端设备上进行模型训练,训练运行时需要满足一些条件:1. 轻量,在端上运行。2. 性能,尽量完成更强的模型的训练。3. 通用性,支持各种模型,减低更新升级的需要。4. 兼容一些标准格式和场景的训练框架格式。等