04-spark、pyspark、hadoop、hive 版本选择
1、spark 安装环境
去官网看 spark 需要的环境:http://spark.apache.org/documentation.html
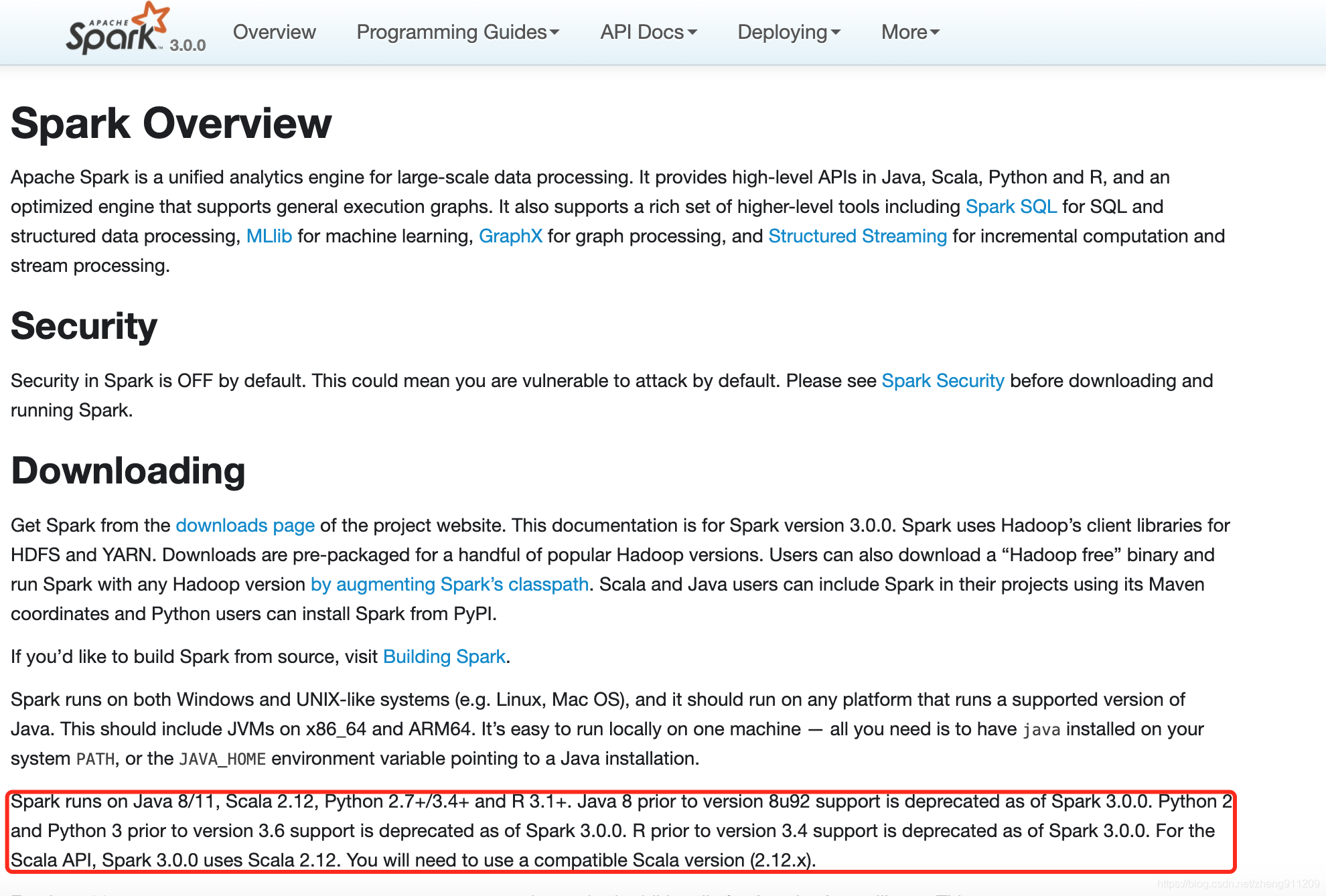
2、spark 支持的 hadoop 版本和 hive 版本
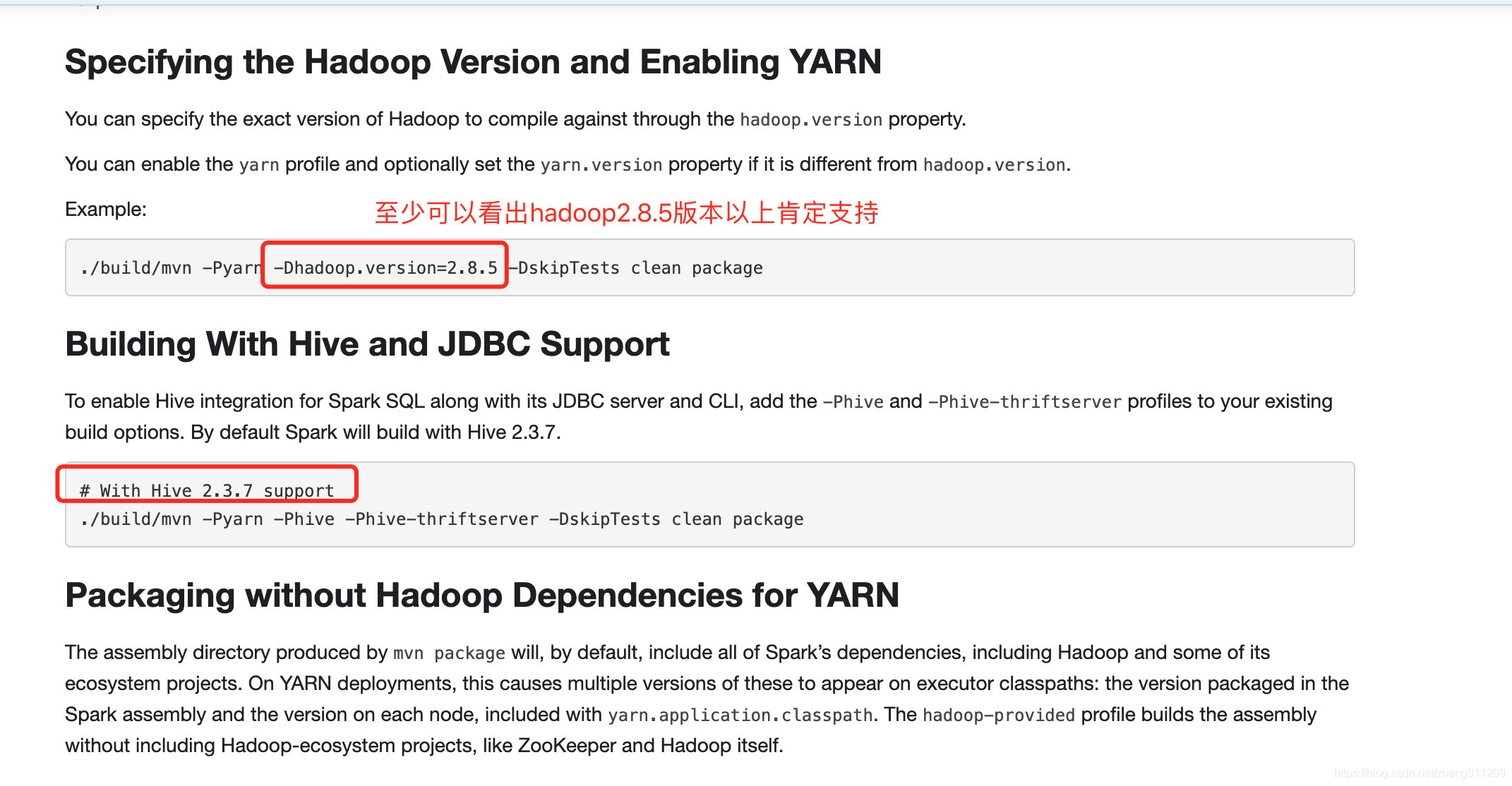
去 spark 官网看:http://spark.apache.org/docs/3.0.0/building-spark.html#specifying-the-hadoop-version-and-enabling-yarn
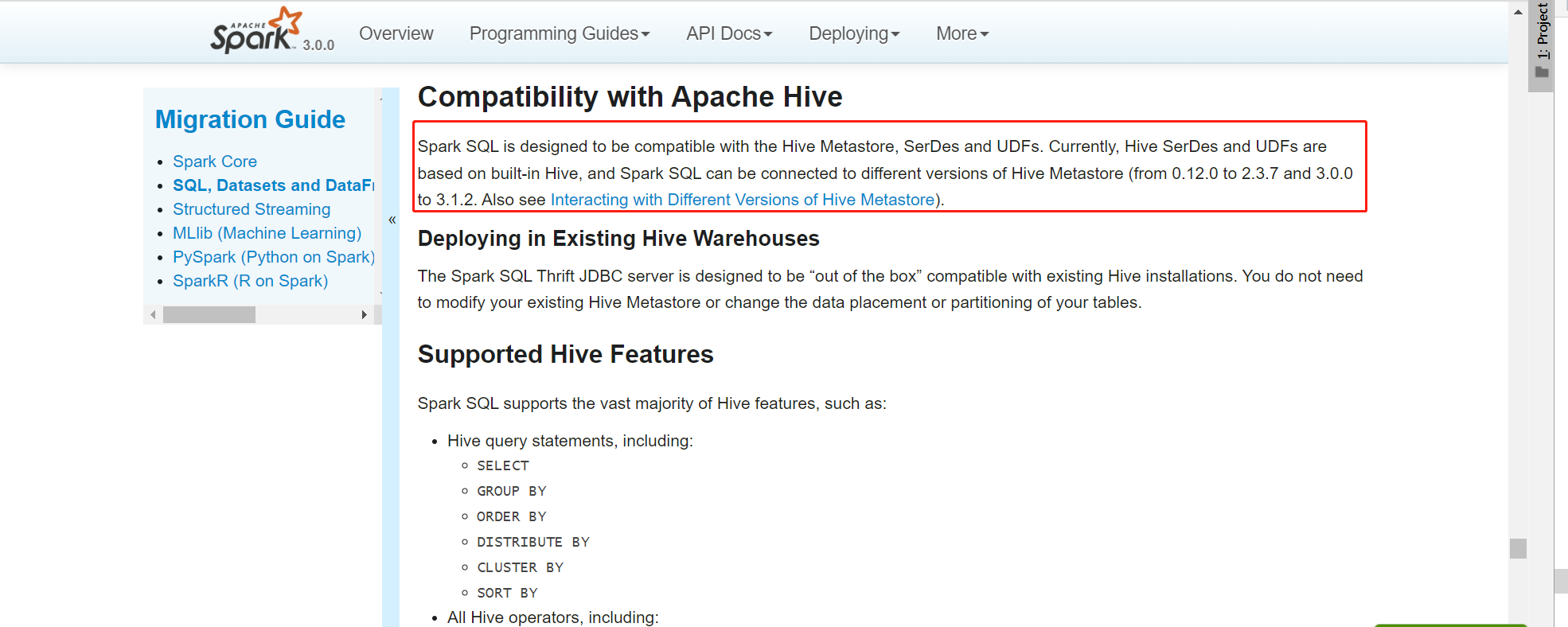
去 spark 官网看 spark 和 Hive的兼容性:https://spark.apache.org/docs/3.0.0/sql-migration-guide.html#compatibility-with-apache-hive
3、hive 和 spark 对应版本
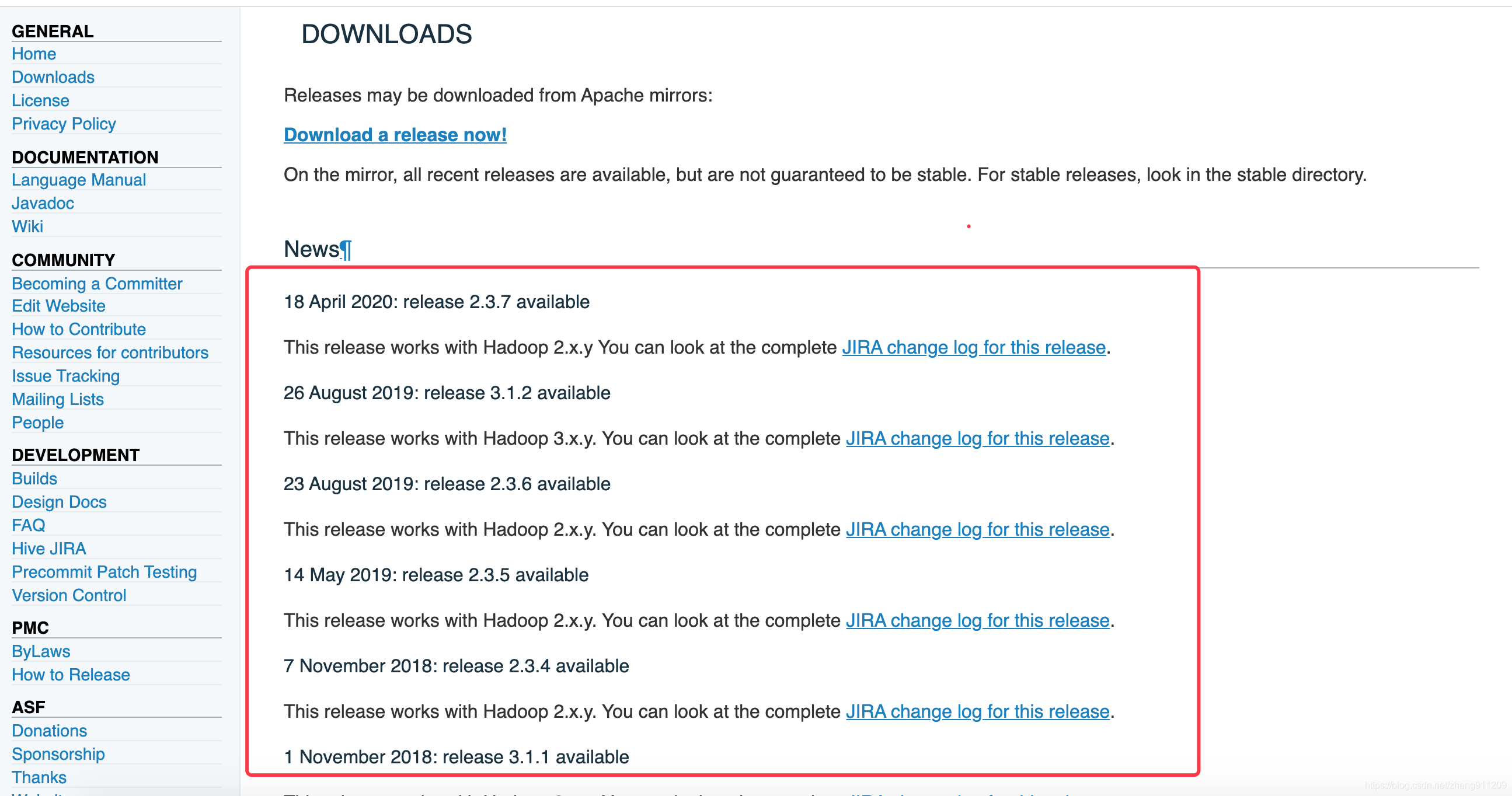
去 hive 官网:https://hive.apache.org/downloads.html
去 apache 官网的 wiki 上看:https://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark%3A+Getting+Started
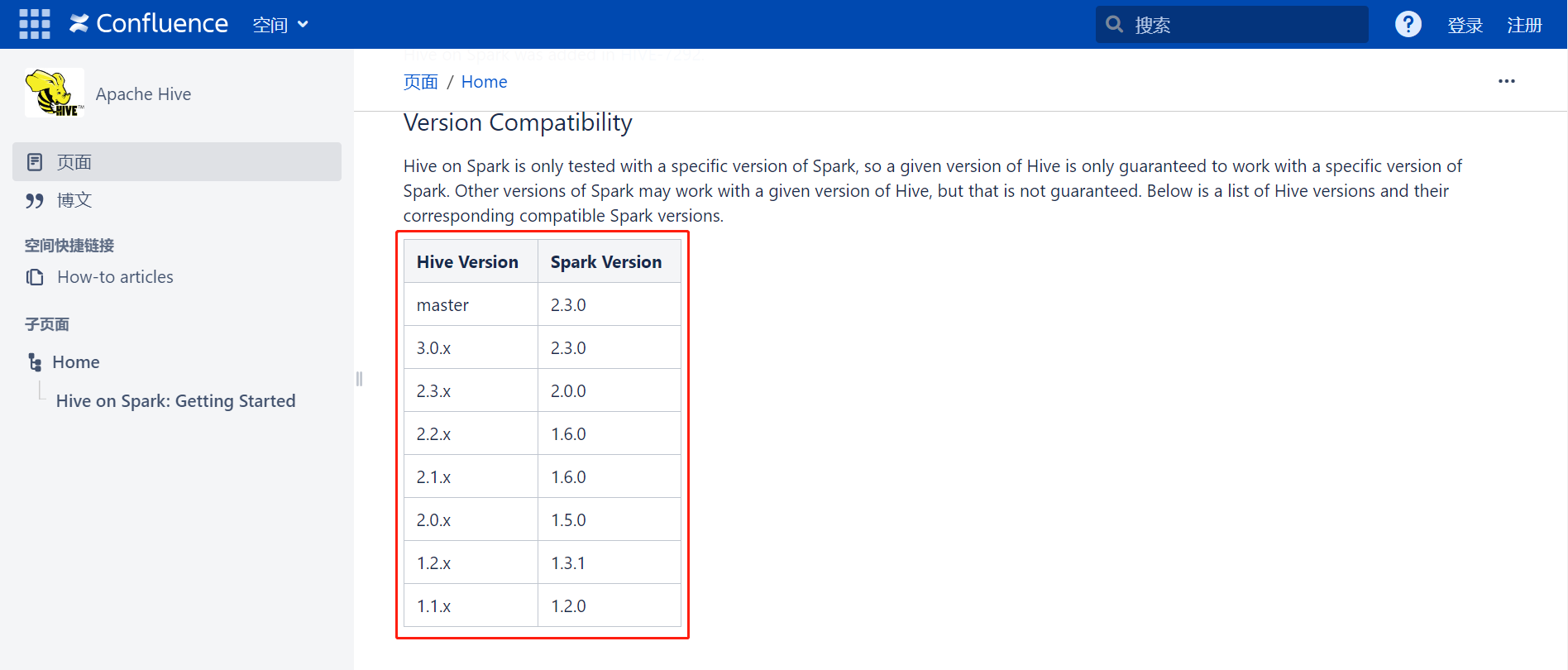
建议:最好不要选择hive的3.x版本,因为spark2.x与目前最新版本的hive3.x在catalog上不兼容(详见官方文档)。也就是说,spark2.x无法直接读取hive3.x的表,只能通过HortonWorks官方提供的HWC补丁来解决(详情可以参考我的这篇spark升级文章),所以不建议你用最新版本,因为配置过于麻烦,作为初学者的你来说,很容易因为其复杂性而放弃。建议你选择在对应的hive2.x版本,或者hive1.x版本,其中hive2.x版本相比1.x多了ACID功能,而1.x版本则比较简单、纯粹,在兼容性上,两者都没有问题,看你需要选择。最后,hive的版本越低,兼容spark的坑越少,且越成熟,这个在各大公司和项目中均有印证,如果你不想过于折腾,建议选择低版本。
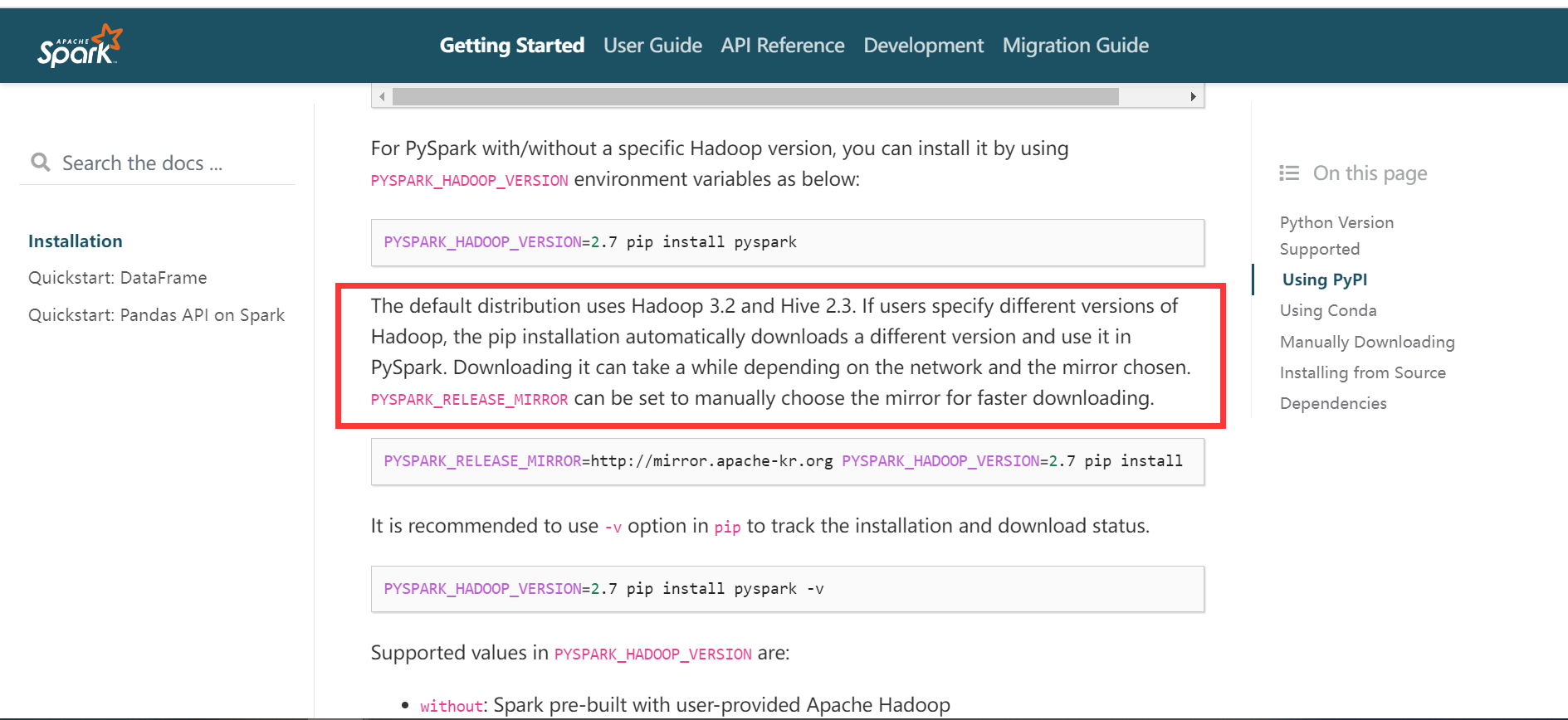
4、pyspark 和 hadoop 以及 hive 的版本
去 spark 的官网: https://spark.apache.org/docs/3.2.4/api/python/getting_started/install.html