01-MySQL 基础
官网保平安:https://www.mysql.com/
MySQL 思维导图:https://www.processon.com/view/link/63bc2c8ea82ed9463ba99f38
与 Oracle 相比,MySQL 有什么优势
- MySQL 是开源软件,随时可用,无需付费。
- MySQL 是便携式的。
- 带有命令提示符的 GUI。
- 使用 MySQL 查询浏览器支持管理。
MySQL 有什么优点?
这个问题本质上是在问 MySQL 如此流行的原因。
MySQL 主要具有下面这些优点:
- 成熟稳定,功能完善。
- 开源免费。
- 文档丰富,既有详细的官方文档,又有非常多优质文章可供参考学习。
- 开箱即用,操作简单,维护成本低。
- 兼容性好,支持常见的操作系统,支持多种开发语言。
- 社区活跃,生态完善。
- 事务支持优秀, InnoDB 存储引擎默认使用 REPEATABLE-READ 并不会有任何性能损失,并且,InnoDB 实现的 REPEATABLE-READ 隔离级别其实是可以解决幻读问题发生的。
- 支持分库分表、读写分离、高可用。
MySQL 备份
数据库导入导出命令(结构+数据)
导出。
mysqldump --no-defaults -uroot -p 数据库名字 > 导出路径
参数--no-defaults解决unknown option --no-beep报错。导入。
mysqldump -uroot -p 数据库名称 < 路径- 进入数据库:
source + 要导入数据库文件路径
如何最快的复制一张表
为了避免对源表加读锁,更稳妥的方案是先将数据写到外部文本文件,然后再写回目标表。
- 一种方法是,使用 mysqldump 命令将数据导出成一组 INSERT 语句。
- 另一种方法是直接将结果导出成.csv 文件。MySQL 提供语法,用来将查询结果导出到服务端本地目录:
select * from db1.t where a>900 into outfile '/t.csv';得到.csv 导出文件后,你就可以用 load data 命令将数据导入到目标表 db2.t 中:load data infile '/t.csv' into table db2.t; - 物理拷贝:在 MySQL 5.6 版本引入了可传输表空间(transportable tablespace) 的方法,可以通过导出 + 导入表空间的方式,实现物理拷贝表的功能。
误删数据怎么办
如果发生了数据删除的操作,又可以从以下几个点来恢复:
- DML 误操作语句造成数据不完整或者丢失。可以通过 flashback,美团的 myflash,也是一个不错的工具,本质都差不多。
- 都是先解析 binlog event,然后在进行反转。把 delete 反转为 insert,insert 反转为 delete,update 前后 image 对调。
- 所以必须设置 binlog_format=row 和 binlog_row_image=full,切记恢复数据的时候,应该先恢复到临时的实例,然后在恢复回主库上。
- DDL 语句误操作(truncate和drop),由于 DDL 语句不管 binlog_format 是 row 还是 statement ,在 binlog 里都只记录语句,不记录 image 所以恢复起来相对要麻烦得多。
- 只能通过
全量备份+binlog的方式来恢复数据。一旦数据量比较大,那么恢复时间就特别长。
- 只能通过
- rm 删除:使用备份跨机房,或者最好是跨城市保存。
DBA 的最核心的工作就是保证数据的完整性,先要做好预防,预防的话大概是通过这几个点:
- 权限控制与分配(数据库和服务器权限)。
- 制作操作规范。
- 定期给开发进行培训。
- 搭建延迟备库。
- 做好 SQL 审计,只要是对线上数据有更改操作的语句(DML和DDL)都需要进行审核。
- 做好备份。备份的话又分为两个点。
- 如果数据量比较大,用物理备份 xtrabackup。定期对数据库进行全量备份,也可以做增量备份。
- 如果数据量较少,用 mysqldump 或者 mysqldumper。再利用 binlog 来恢复或者搭建主从的方式来恢复数据。定期备份 binlog 文件也是很有必要的。
为什么要有多线程复制策略
因为单线程复制的能力全面低于多线程复制,对于更新压力较大的主库,备库可能是一直追不上主库的,带来的现象就是备库上 seconds_behind_master 值越来越大。
在实际应用中,建议使用可靠性优先策略,减少主备延迟,提升系统可用性,尽量减少大事务操作,把大事务拆分小事务。
MySQL 的并行策略有哪些
按表分发策略:如果两个事务更新不同的表,它们就可以并行。因为数据是存储在表里的,所以按表分发,可以保证两个 worker 不会更新同一行。
缺点:如果碰到热点表,比如所有的更新事务都会涉及到某一个表的时候,所有事务都会被分配到同一个 worker 中,就变成单线程复制了。按行分发策略:如果两个事务没有更新相同的行,它们在备库上可以并行。显然,这个模式要求 binlog 格式必须是 row。
缺点:相比于按表并行分发策略,按行并行策略在决定线程分发的时候,需要消耗更多的计算资源。
MySQL 怎么恢复半个月前的数据
通过 全量备份+binlog 进行恢复。前提是要有定期整库备份且保存了 binlog。
其他
详细说一下一条 MySQL 语句执行的步骤
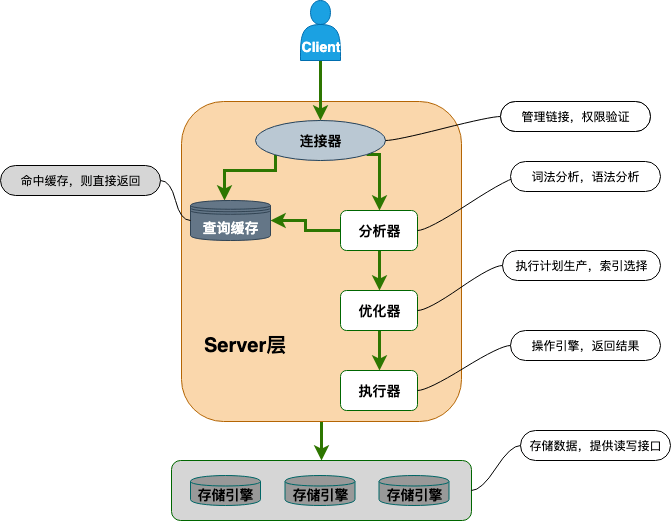
Server 层按顺序执行 SQL 的步骤为:
- 客户端请求
- -> 连接器(验证用户身份,给予权限)
- -> 查询缓存(存在缓存则直接返回,不存在则执行后续操作)(MySQL 8.0 版本后移除,因为这个功能不太实用)
- -> 分析器(对 SQL 进行词法分析和语法分析操作)
- -> 优化器(主要对执行的 SQL 优化,选择最优的执行方案方法)
- -> 执行器(执行语句,然后从存储引擎返回数据。执行语句之前会先判断是否有权限,如果没有权限的话,就会报错)
如何理解 MySQL 的边读边发
如果客户端接受慢,会导致 MySQL 服务端由于结果发不出去,这个事务的执行时间会很长。
服务端并不需要保存一个完整的结果集,取数据和发数据的流程都是通过一个 next_buffer 来操作的。
内存的数据页都是在 Buffer_Pool 中操作的。InnoDB 管理 Buffer_Pool 使用的是改进的 LRU 算法,使用链表实现,实现上,按照 5:3 的比例把整个 LRU 链表分成了 young 区域和 old 区域。对冷数据的全扫描,影响也能做到可控制。
MySQL 的大表查询为什么不会爆内存
由于 MySQL 是边读变发,因此对于数据量很大的查询结果来说,不会在 server 端保存完整的结果集,所以,如果客户端读结果不及时,会堵住 MySQL 的查询过程,但是不会把内存打爆。
MySQL 临时表的用法和特性
- 只对当前 session 可见。
- 可以与普通表重名。
- 增删改查用的是临时表。
show tables不显示普通表。- 在实际应用中,临时表一般用于处理比较复杂的计算逻辑。
- 由于临时表是每个线程自己可见的,所以不需要考虑多个线程执行同一个处理时临时表的重名问题,在线程退出的时候,临时表会自动删除。
简述触发器、函数、视图、存储过程
触发器:对数据库某个表进行【增、删、改】前后,自定义的一些 SQL 操作。
函数:在 SQL 语句中使用的函数。例如:
select sleep(2)。视图:对某些表进行 SQL 查询,将结果实时显示出来(是虚拟表),只能查询不能更新。
视图是一种虚拟的表,通常是有一个表或者多个表的行或列的子集,具有和物理表相同的功能,可以对视图进行增、删、改、查等操作。
对视图的修改,不影响基本表。
相比多表查询,它使得我们获取数据更容易。存储过程:将提前定义好的 SQL 语句保存到数据库中并命名;以后在代码中调用时直接通过名称即可。存储过程一旦调试完成通过后就能稳定运行,另外,使用存储过程比单纯 SQL 语句执行要快,因为存储过程是预编译过的。
存储过程在互联网公司应用不多,因为存储过程难以调试和扩展,而且没有移植性,还会消耗数据库资源。
阿里巴巴 Java 开发手册里要求禁止使用存储过程。!游标是对查询处理出来的结果集作为一个单元来有效的处理。游标可以定在该单元中的特定行,从结果集的当前行检索一行或多行。
MySQL 的并发链接和并发查询有什么区别
在执行
show processlist的结果里,看到了几千个连接,指的是并发连接。而
当前正在执行的语句,才是并发查询。
并发连接数多影响的是内存,并发查询太高对 CPU 不利。一个机器的 CPU 核数有限,线程全冲进来,上下文切换的成本就会太高。
所以需要设置参数:innodb_thread_concurrency 用来限制线程数,当线程数达到该参数,InnoDB 就会认为线程数用完了,会阻止其他语句进入引擎执行。
为什么 MySQL 会抖一下
当内存数据页跟磁盘数据页内容不一致的时候,我们称这个内存页为“脏页”。内存数据写入到磁盘后,内存和磁盘上的数据页的内容就一致了,称为“干净页”。
脏页会被后台线程自动 flush,也会由于数据页淘汰而触发 flush,而刷脏页的过程由于会占用资源,可能会让你的更新和查询语句的响应时间长一些。
刷脏页有下面4种场景:
- 当 redo log 写满,MySQL 就会暂停所有更新操作,将同步这部分日志对应的脏页同步到磁盘。
- 系统内存不足时,需要淘汰一部分数据页,如果淘汰的是脏页,就要先将脏页同步到磁盘。
- MySQL 认为系统空闲的时候,有机会就同步内存数据到磁盘,这种没有性能问题。
- MySQL 正常关闭,MySQL 会把内存的脏页都同步到磁盘上,这样下次 MySQL 启动的时候,就可以直接从磁盘上读数据,启动速度会很快。这种没有性能问题。
MySQL 查询缓存有什么弊端,应该什么情况下使用,8.0 版本对查询缓存有什么变更
- 查询缓存可能会失效非常频繁,对于一个表,只要有更新,该表的全部查询缓存都会被清空。因此对于频繁更新的表来说,查询缓存不一定能起到正面效果。
- 对于读远多于写的表可以考虑使用查询缓存。
- 8.0 版本的查询缓存功能被删了 ( ̄. ̄)。
隐式转换
- 当操作符左右两边的数据类型不一致时,会发生隐式转换。
- 当 where 查询操作符左边为数值类型时,发生了隐式转换,那么对效率影响不大,但还是不推荐这么做。
- 当 where 查询操作符左边为字符类型时,发生了隐式转换,那么会导致索引失效,造成全表扫描效率极低。
- 字符串转换为数值类型时,非数字开头的字符串会转化为 0,以数字开头的字符串会截取从第一个字符到第一个非数字内容为止的值为转化结果。
能用 MySQL 直接存储文件(比如图片)吗?
可以是可以,直接存储文件对应的二进制数据即可。不过,还是建议不要在数据库中存储文件,会严重影响数据库性能,消耗过多存储空间。
可以选择使用云服务厂商提供的开箱即用的文件存储服务,成熟稳定,价格也比较低。