02-Redis 部署模式02哨兵(重要)
官网保平安:https://redis.io/
Sentinel(哨兵)(>=2.8版本)
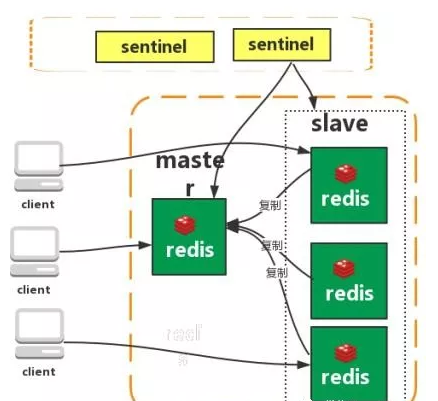
Redis Sentinel 实现 Redis 集群高可用,只是在主从复制实现集群的基础下,多了一个 Sentinel 角色来帮助我们监控 Redis 节点的运行状态并自动实现故障转移。
当 master 出现故障的时候,Sentinel 会帮助我们实现故障转移,自动根据一定的规则选出一个 slave 升级为 master,确保整个 Redis 系统的可用性。整个过程完全自动,不需要人工介入。
Sentinel 有什么作用
相关问题:
- 为什么建议部署多个 Sentinel 节点(哨兵集群)?
根据 Redis Sentinel 官方文档 的介绍,Sentinel 节点主要可以提供 4 个功能:
- 监控: 监控所有 redis 节点(包括 Sentinel 节点自身)的状态是否正常。
- 故障转移: 如果一个 master 出现故障,Sentinel 会帮助我们实现故障转移,自动将某一台 slave 升级为 master,确保整个 Redis 系统的可用性。
- 通知: 通知 slave 新的 master 连接信息,让它们执行 replicaof 成为新的 master 的 slave。
- 配置提供: 客户端连接 Sentinel 请求 master 的地址,如果发生故障转移,Sentinel 会通知新的 master 链接信息给客户端。
Redis Sentinel 本身设计的就是一个分布式系统,建议多个 Sentinel 节点协作运行。这样做的好处是:
- 多个 Sentinel 节点通过投票的方式来确定 Sentinel 节点是否真的不可用,避免误判(比如网络问题可能会导致误判)。
- Sentinel 自身就是高可用。
如果想要实现高可用,建议将哨兵 Sentinel 配置成单数且大于等于 3 台。
一个最简易的 Redis Sentinel 集群如下所示(官方文档中的一个例子),其中:
- M1 表示 master,R2、R3 表示 slave;
- S1、S2、S3 都是 Sentinel;
- quorum 表示判定 master 失效最少需要的仲裁节点数。这里的值为 2,也就是说当有 2 个 Sentinel 认为 master 失效时,master 才算真正失效。
1 | |
如果 M1 出现问题,只要 S1、S2、S3 其中的两个投票赞同的话,就会开始故障转移工作,从 R2 或者 R3 中重新选出一个作为 master。
为什么 Redis 哨兵集群只有 2 个节点无法正常工作?
在故障转移的时候,需要 majority,也就是大多数哨兵都是运行的,2 个哨兵的 majority 就是 2(2 的 majority=2,3 的 majority=2,5 的 majority=3,4 的 majority=2),2 个哨兵都运行着,就可以允许执行故障转移。
如果此时有一个 Sentinel 挂掉了,此时就没有足够的 majority 来允许执行故障转移,所以故障转移不会执行。
Sentinel 缺点
- 主从模式,切换需要时间,可能会丢数据。
- 没有解决 master 写的压力。
Sentinel 原理
相关的问题:
- 主观下线与客观下线的区别?
- Sentinel 如何检测节点是否下线?
- Sentinel 是如何实现故障转移的?
- Sentinel 如何选择出新的 master?
- 如何从 Sentinel 集群中选择出 Leader?
三个定时监控任务:
- 每隔10s,每个 Sentinel 节点 会向 master 和 slave 发送
info命令获取最新的拓扑结构。 - 每隔 2s,每个 Sentinel 节点 会向某频道上发送该 Sentinel 节点 对于 master 的判断以及当前 Sl节点 的信息,同时每个 Sentinel 节点 也会订阅该频道,来了解其他 Sentinel 节点 以及它们对 master 的判断(做客观下线依据)。
- 每隔 1s,每个 Sentinel 节点 会向 master、slave、其余 Sentinel 节点 发送一条 ping 命令做一次心跳检测(心跳检测机制),来确认这些节点当前是否可达。
- 每隔10s,每个 Sentinel 节点 会向 master 和 slave 发送
主客观下线:
主观下线(sdown):
- 根据第三个定时任务,如果对应的节点超过规定的时间(down-after-millisenconds)没有进行有效回复的话,就会认定为主观下线。但还不是很确定,需要其他 Sentinel 节点的投票。
- 这里的有效回复不一定是 PONG,可以是-LOADING 或者 -MASTERDOWN
客观下线(odown):
- 若主观下线的是 master,会咨询其他 S节点 对该 master 的判断,超过半数,对该 master 做客观下线。
- 若主观下线的是 slave,不会做什么事情。
如果没有足够数量的 Sentinel 节点认定 master 已经下线的话,当 master 能对 Sentinel 节点的 PING 命令进行有效回复之后,master 也就不再被认定为主观下线,回归正常。
选举出某一 Sentinel 节点 作为 Leader,来进行故障转移。
这就需要用到分布式领域的 共识算法 了。简单来说,共识算法就是让分布式系统中的节点就一个问题达成共识。在 Sentinel 选举 leader 这个场景下,这些 Sentinel 要达成的共识就是谁才是 leader 。
大部分共识算法都是基于 Paxos 算法改进而来。Sentinel 选举 leader 用的是 Raft 算法。每个Sentinel 节点 有一票同意权,哪个 Sentinel 节点 做出主观下线的时候,就会询问其他 Sentinel 节点 是否同意其为领导者。获得半数选票的则成为领导者。基本谁先做出客观下线,谁成为领导者。
想要深入了解 Raft 算法实践以及 Sentinel 选举 leader 的详细过程的同学,推荐阅读下面这两篇文章:
故障转移(选举新 master 流程):
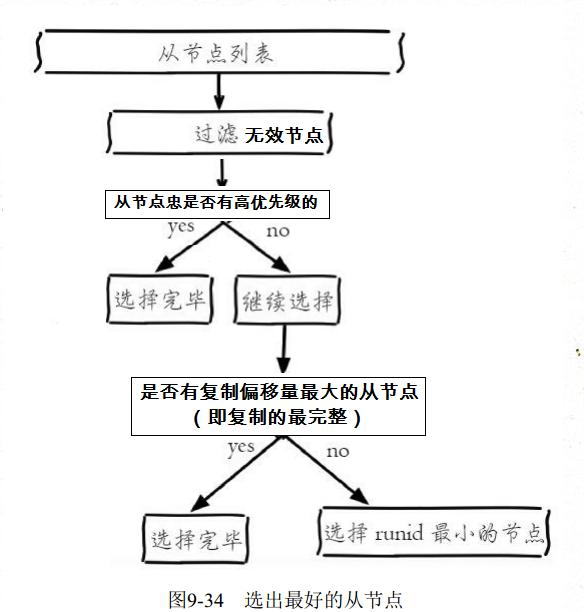
选举 master,会考虑 slave 的如下信息:
跟 master 断开连接的时长。如果一个 slave 跟 master 断开连接已经超过了
down-after-milliseconds的 10 倍,外加 master 宕机的时长,那么该 slave 就被认为不适合选举为 master。( down-after-milliseconds * 10) + milliseconds_since_master_is_in_SDOWN_state
slave 优先级。按照 slave 优先级进行排序,优先级最高的直接成为新的 master。如果没有优先级最高的,再判断复制进度。
- 可以通过 slave-priority 手动设置 slave 的优先级,
复制进度。Sentinel 总是希望选择出数据最完整(与旧 master 数据最接近)也就是复制进度最快的 slave 被提升为新的 master,复制进度越快得分也就越高。
run id(运行 id)。如果上面两个条件都相同,那么选择一个 run id 比较小的 slave。
- 每个 redis 节点启动时都有一个 40 字节随机字符串作为运行 id
如果 master 修复好了,再次启动时候,会变成 slave。
Sentinel 设置
启动主 Redis:
redis-server /etc/redis-6379.conf。启动从 Redis:
redis-server /etc/redis-6380.conf。找到
/etc/redis-sentinel-8001.conf配置文件,修改:port = 8001:哨兵的端口。sentinel monitor mymaster 127.0.0.1 6379 2:- mymaster 是哨兵所在分组的名称。
- 后面的 IP+端口 是 master 的IP和端口。
- 最后的 2,意思是 master 被认为的宕机,需要选举新的 master 时,至少要争取到 2 票的赞同,否则故障不会自动转移。
找到
/etc/redis-sentinel-8002.conf配置文件,修改:port = 8002:哨兵的端口。sentinel monitor mymaster 127.0.0.1 6379 2。
启动两个哨兵:
- 方式一:
redis-server --sentinel命令启动哨兵,示例:redis-server /path/to/sentinel.conf --sentinel。 - 方式二:
redis-sentinel命令启动哨兵,示例:redis-sentinel /path/to/sentinel.conf。
两个命令都可以启动哨兵服务。
- 方式一:
一个常见的最小配置如下所示:
1 | |
Redis 主从架构数据会丢失吗,为什么?
- Sentinel 可以防止脑裂吗?
有两种数据丢失的情况:
异步复制导致的数据丢失:因为 master -> slave 的复制是异步的,所以可能有部分数据还没复制到 slave,master 就宕机了,此时这些部分数据就丢失了。
脑裂导致的数据丢失:
- 某个 master 所在机器突然脱离了正常的网络,跟其他 slave 机器不能连接,但是实际上 master 还运行着,此时哨兵可能就会认为 master 宕机了,然后开启选举,将其他 slave 切换成了 master。
- 这个时候,集群里就会有两个 master,也就是所谓的脑裂。此时虽然某个 slave 被切换成了 master,但是可能 client 还没来得及切换到新的 master,还继续写向旧 master 的数据可能也丢失了。
- 因此旧 master 再次恢复的时候,会被作为一个 slave 挂到新的 master 上去,自己的数据会清空,重新从新的 master 复制数据。
如何解决主从架构数据丢失的问题?
数据丢失的问题是不可避免的,但是我们可以尽量减少。
在 Redis 的配置文件里设置参数
1 | |
上面的配置的意思是:要求至少有 1 个 slave,数据复制和同步的延迟不能超过 10 秒。如果说一旦所有的 slave,数据复制和同步的延迟都超过了 10 秒钟,那么这个时候,master 就不会再接收任何请求了。
减小 min-slaves-max-lag 参数的值,这样就可以避免在发生故障时大量的数据丢失。
那么对于 client,我们可以采取降级措施,将数据暂时写入本地缓存和磁盘中,在一段时间后重新写入 master 来保证数据不丢失;也可以将数据写入 Kafka 消息队列,隔一段时间去消费 Kafka 中的数据。