03-Redis 应用
官网保平安:https://redis.io/
Redis 应用
Redis 除了做缓存,还能做什么?
- 分布式锁:通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。 。
- 限流:一般是通过 Redis + Lua 脚本的方式来实现限流。如果不想自己写 Lua 脚本的话,也可以直接利用 Redisson 中的
RRateLimiter来实现分布式限流,其底层实现就是基于 Lua 代码+令牌桶算法。 - 消息队列:Redis 自带的 List 数据结构可以作为一个简单的队列使用。Redis 5.0 中增加的 Stream 类型的数据结构更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
- 延时队列:Redisson 内置了延时队列(基于 Sorted Set 实现的)。
- 分布式 Session :利用 String 或者 Hash 数据类型保存 Session 数据,所有的服务器都可以访问。
- 复杂业务场景:通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景比如通过 Bitmap 统计活跃用户、通过 Sorted Set 维护排行榜。
Redis 可以做消息队列么?
实际项目中使用 Redis 来做消息队列的非常少,毕竟有更成熟的消息队列中间件可以用。
先说结论:可以是可以,但不建议使用 Redis 来做消息队列。和专业的消息队列相比,还是有很多欠缺的地方。
Redis 2.0 之前,如果想要使用 Redis 来做消息队列的话,只能通过 List 来实现。
通过 RPUSH/LPOP 或者 LPUSH/RPOP 即可实现简易版消息队列:
1 | |
不过,通过 RPUSH/LPOP 或者 LPUSH/RPOP 这样的方式存在性能问题,我们需要不断轮询去调用 RPOP 或 LPOP 来消费消息。当 List 为空时,大部分的轮询的请求都是无效请求,这种方式大量浪费了系统资源。
因此,Redis 还提供了 BLPOP、BRPOP 这种阻塞式读取的命令(带 B-Blocking 的都是阻塞式),并且还支持一个超时参数。如果 List 为空,Redis 服务端不会立刻返回结果,它会等待 List 中有新数据后再返回或者是等待最多一个超时时间后返回空。如果将超时时间设置为 0 时,即可无限等待,直到弹出消息
1 | |
List 实现消息队列功能太简单,没有消息确认机制、offset、消费者组,最要命的是没有广播机制,消息也只能被消费一次。
Redis 2.0 引入了发布订阅 (pub/sub) 功能,解决了 List 实现消息队列没有广播机制的问题。
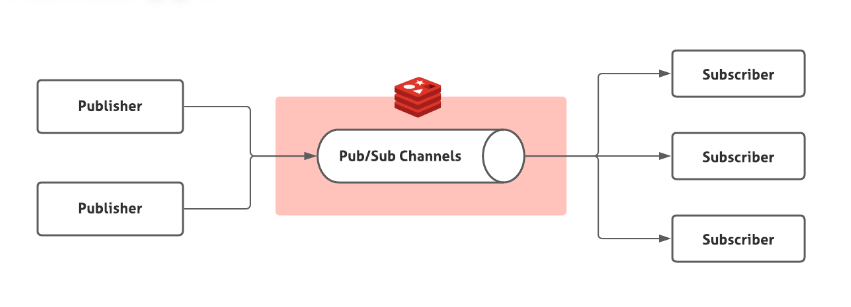
pub/sub 中引入了一个概念叫 channel(频道),发布订阅机制的实现就是基于这个 channel 来做的。
pub/sub 涉及发布者(Publisher)和订阅者(Subscriber,也叫消费者)两个角色:
- 发布者通过
PUBLISH投递消息给指定 channel。 - 订阅者通过
SUBSCRIBE订阅它关心的 channel。并且,订阅者可以订阅一个或者多个 channel。
我们这里启动 3 个 Redis 客户端来简单演示一下:

pub/sub 既能单播又能广播,还支持 channel 的简单正则匹配。不过,消息丢失(客户端断开连接或者 Redis 宕机都会导致消息丢失)、消息堆积(发布者发布消息的时候不会管消费者的具体消费能力如何)等问题依然没有一个比较好的解决办法。
为此,Redis 5.0 新增一个数据结构 Stream 来做消息队列。Stream 支持:
- 发布 / 订阅模式
- 按照消费者组进行消费(借鉴了 Kafka 消费者组的概念)
- 消息持久化(RDB 和 AOF)
- ACK 机制(通过确认机制来告知已经成功处理了消息)
- 阻塞式获取消息
Stream 的结构如下:
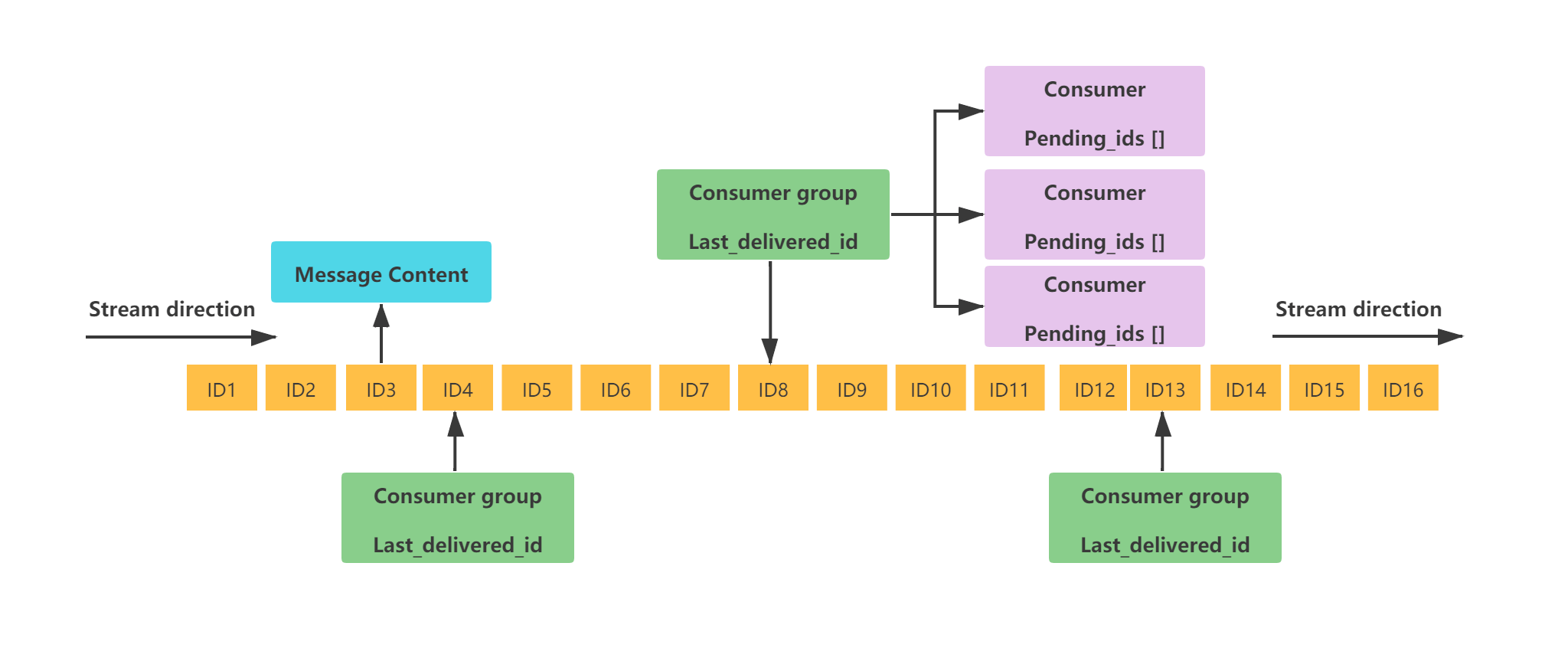
这是一个有序的消息链表,每个消息都有一个唯一的 ID 和对应的内容。ID 是一个时间戳和序列号的组合,用来保证消息的唯一性和递增性。内容是一个或多个键值对(类似 Hash 基本数据类型),用来存储消息的数据。
这里再对图中涉及到的一些概念,进行简单解释:
Consumer Group:消费者组用于组织和管理多个消费者。消费者组本身不处理消息,而是再将消息分发给消费者,由消费者进行真正的消费last_delivered_id:标识消费者组当前消费位置的游标,消费者组中任意一个消费者读取了消息都会使 last_delivered_id 往前移动。pending_ids:记录已经被客户端消费但没有 ack 的消息的 ID。
下面是 Stream 用作消息队列时常用的命令:
XADD:向流中添加新的消息。XREAD:从流中读取消息。XREADGROUP:从消费组中读取消息。XRANGE:根据消息 ID 范围读取流中的消息。XREVRANGE:与XRANGE类似,但以相反顺序返回结果。XDEL:从流中删除消息。XTRIM:修剪流的长度,可以指定修建策略(MAXLEN/MINID)。XLEN:获取流的长度。XGROUP CREATE:创建消费者组。XGROUP DESTROY: 删除消费者组XGROUP DELCONSUMER:从消费者组中删除一个消费者。XGROUP SETID:为消费者组设置新的最后递送消息 IDXACK:确认消费组中的消息已被处理。XPENDING:查询消费组中挂起(未确认)的消息。XCLAIM:将挂起的消息从一个消费者转移到另一个消费者。XINFO:获取流(XINFO STREAM)、消费组(XINFO GROUPS)或消费者(XINFO CONSUMERS)的详细信息。
Stream 使用起来相对要麻烦一些,这里就不演示了。
总的来说,Stream 已经可以满足一个消息队列的基本要求了。不过,Stream 在实际使用中依然会有一些小问题不太好解决比如在 Redis 发生故障恢复后不能保证消息至少被消费一次。
综上,和专业的消息队列相比,使用 Redis 来实现消息队列还是有很多欠缺的地方比如消息丢失和堆积问题不好解决。因此,我们通常建议不要使用 Redis 来做消息队列,你完全可以选择市面上比较成熟的一些消息队列比如 RocketMQ、Kafka。不过,如果你就是想要用 Redis 来做消息队列的话,那我建议你优先考虑 Stream,这是目前相对最优的 Redis 消息队列实现。
相关阅读:Redis 消息队列发展历程 * 阿里开发者 - 2022。
Redis Stream Vs Kafka
Redis 基于内存存储,这意味着它会比基于磁盘的 Kafka 快上一些,也意味着使用 Redis 我们 不能长时间存储大量数据。
如果您想以 最小延迟 实时处理消息的话,您可以考虑 Redis,但是如果 消息很大并且应该重用数据 的话,则应该首先考虑使用 Kafka。
从某些角度来说,Redis Stream 也更适用于小型、廉价的应用程序,因为 Kafka 相对来说更难配置一些。
使用过 Redis 做异步队列么,你是怎么用的
一般使用 list 结构作为队列,rpush 生产消息,lpop 消费消息。当 lpop 没有消息的时候,要适当 sleep 一会再重试。
如果对方追问可不可以不用 sleep 呢?
list 还有个指令叫 blpop,在没有消息的时候,它会阻塞住直到消息到来。
使用 list 当做队列,缺点是没有 ack 机制和不支持多个消费者。没有 ack 机制会导致从 Redis 中取出的数据后,如果客户端处理失败了,取出的这个数据相当于丢失了,无法重新消费。所以使用 List 用作队列适合于对于丢失数据不敏感的业务场景,但它的优点是,因为都是内存操作,所以非常快和轻量。
如果对方追问能不能生产一次消费多次呢?
使用 pub/sub 主题订阅者模式, 可以实现 1:N 的消息队列。
如果对方追问 pub/sub 有什么缺点?
- 如果任意一个消费者挂了,等恢复过来后,在这期间生产者生产的数据就丢失了。
pub/sub模式只把数据发给在线的消费者,消费者一旦下线,就会丢弃数据。 pub/sub模式不支持数据持久化,当 Redis 宕机恢复后,其他类型的数据都可以从 RDB 和 AOF 中恢复回来,但pub/sub模式不行,它就是简单的基于内存的多播机制。
想解决上面的问题,需要使用专业的消息队列如 RabbitMQ 等。
如果对方追问 Redis 如何实现延时队列? 我估计现在你很想把面试官一棒打死,怎么问的这么详细。但是你很克制,然后神态自若的回答道:
使用 sorted set,拿时间戳作为 score,消息内容作为 key 调用 zadd 来生产消息,消费者用 zrangebyscore 指令获取 N 秒之前的数据轮询进行处理。
Redis 可以做搜索引擎么?
Redis 是可以实现全文搜索引擎功能的,需要借助 RediSearch,这是一个基于 Redis 的搜索引擎模块。
RediSearch 支持中文分词、聚合统计、停用词、同义词、拼写检查、标签查询、向量相似度查询、多关键词搜索、分页搜索等功能,算是一个功能比较完善的全文搜索引擎了。
相比较于 Elasticsearch 来说,RediSearch 主要在下面两点上表现更优异一些:
- 性能更优秀:依赖 Redis 自身的高性能,基于内存操作(Elasticsearch 基于磁盘)。
- 较低内存占用实现快速索引:RediSearch 内部使用压缩的倒排索引,所以可以用较低的内存占用来实现索引的快速构建。
对于小型项目的简单搜索场景来说,使用 RediSearch 来作为搜索引擎还是没有问题的(搭配 RedisJSON 使用)。
对于比较复杂或者数据规模较大的搜索场景还是不太建议使用 RediSearch 来作为搜索引擎,主要是因为下面这些限制和问题:
- 数据量限制:Elasticsearch 可以支持 PB 级别的数据量,可以轻松扩展到多个节点,利用分片机制提高可用性和性能。RedisSearch 是基于 Redis 实现的,其能存储的数据量受限于 Redis 的内存容量,不太适合存储大规模的数据(内存昂贵,扩展能力较差)。
- 分布式能力较差:Elasticsearch 是为分布式环境设计的,可以轻松扩展到多个节点。虽然 RedisSearch 支持分布式部署,但在实际应用中可能会面临一些挑战,如数据分片、节点间通信、数据一致性等问题。
- 聚合功能较弱:Elasticsearch 提供了丰富的聚合功能,而 RediSearch 的聚合功能相对较弱,只支持简单的聚合操作。
- 生态较差:Elasticsearch 可以轻松和常见的一些系统/软件集成比如 Hadoop、Spark、Kibana,而 RedisSearch 则不具备该优势。
Elasticsearch 适用于全文搜索、复杂查询、实时数据分析和聚合的场景,而 RediSearch 适用于快速数据存储、缓存和简单查询的场景。
如何基于 Redis 实现延时任务?
类似的问题:
- 订单在 10 分钟后未支付就失效,如何用 Redis 实现?
- 红包 24 小时未被查收自动退还,如何用 Redis 实现?
基于 Redis 实现延时任务的功能无非就下面两种方案:
- Redis 过期事件监听
- Redisson 内置的延时队列
面试的时候,你可以先说自己考虑了这两种方案,但最后发现 Redis 过期事件监听这种方案存在很多问题,因此你最终选择了 Redisson 内置的 DelayedQueue 这种方案。
这个时候面试官可能会追问你一些相关的问题,我们后面会提到,提前准备就好了。
另外,除了下面介绍到的这些问题之外,Redis 相关的常见问题建议你都复习一遍,不排除面试官会顺带问你一些 Redis 的其他问题。
Redis 过期事件监听实现延时任务功能的原理?
Redis 2.0 引入了发布订阅 (pub/sub) 功能。在 pub/sub 中,引入了一个叫做 channel(频道) 的概念,有点类似于消息队列中的 topic(主题)。
pub/sub 涉及发布者(publisher)和订阅者(subscriber,也叫消费者)两个角色:
- 发布者通过
PUBLISH投递消息给指定 channel。 - 订阅者通过
SUBSCRIBE订阅它关心的 channel。并且,订阅者可以订阅一个或者多个 channel。
在 pub/sub 模式下,生产者需要指定消息发送到哪个 channel 中,而消费者则订阅对应的 channel 以获取消息。
Redis 中有很多默认的 channel,这些 channel 是由 Redis 本身向它们发送消息的,而不是我们自己编写的代码。其中,__keyevent@0__:expired 就是一个默认的 channel,负责监听 key 的过期事件。也就是说,当一个 key 过期之后,Redis 会发布一个 key 过期的事件到 __keyevent@<db>__:expired 这个 channel 中。
我们只需要监听这个 channel,就可以拿到过期的 key 的消息,进而实现了延时任务功能。
这个功能被 Redis 官方称为 keyspace notifications,作用是实时监控 Redis 键和值的变化。
Redis 过期事件监听实现延时任务功能有什么缺陷?
1、时效性差
官方文档的一段介绍解释了时效性差的原因,地址:https://redis.io/docs/manual/keyspace-notifications/#timing-of-expired-events 。

这段话的核心是:过期事件消息是在 Redis 服务器删除 key 时发布的,而不是一个 key 过期之后就会就会直接发布。
我们知道常用的过期数据的删除策略就两个:
- 惰性删除:只会在取出 key 的时候才对数据进行过期检查。这样对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
- 定期删除:每隔一段时间抽取一批 key 执行删除过期 key 操作。并且,Redis 底层会通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
定期删除对内存更加友好,惰性删除对 CPU 更加友好。两者各有千秋,所以 Redis 采用的是 定期删除+惰性/懒汉式删除 。
因此,就会存在我设置了 key 的过期时间,但到了指定时间 key 还未被删除,进而没有发布过期事件的情况。
2、丢消息
Redis 的 pub/sub 模式中的消息并不支持持久化,这与消息队列不同。在 Redis 的 pub/sub 模式中,发布者将消息发送给指定的频道,订阅者监听相应的频道以接收消息。当没有订阅者时,消息会被直接丢弃,在 Redis 中不会存储该消息。
3、多服务实例下消息重复消费
Redis 的 pub/sub 模式目前只有广播模式,这意味着当生产者向特定频道发布一条消息时,所有订阅相关频道的消费者都能够收到该消息。
这个时候,我们需要注意多个服务实例重复处理消息的问题,这会增加代码开发量和维护难度。
Redisson 延迟队列原理是什么?有什么优势?
Redisson 是一个开源的 Java 语言 Redis 客户端,提供了很多开箱即用的功能,比如多种分布式锁的实现、延时队列。
我们可以借助 Redisson 内置的延时队列 RDelayedQueue 来实现延时任务功能。
Redisson 的延迟队列 RDelayedQueue 是基于 Redis 的 SortedSet 来实现的。SortedSet 是一个有序集合,其中的每个元素都可以设置一个分数,代表该元素的权重。Redisson 利用这一特性,将需要延迟执行的任务插入到 SortedSet 中,并给它们设置相应的过期时间 作为分数。
Redisson 使用 zrangebyscore 命令扫描 SortedSet 中过期的元素,然后将这些过期元素从 SortedSet 中移除,并将它们加入到就绪消息列表中。就绪消息列表是一个阻塞队列,有消息进入就会被监听到。这样做可以避免对整个 SortedSet 进行轮询,提高了执行效率。
相比于 Redis 过期事件监听实现延时任务功能,这种方式具备下面这些优势:
- 减少了丢消息的可能:DelayedQueue 中的消息会被持久化,即使 Redis 宕机了,根据持久化机制,也只可能丢失一点消息,影响不大。当然了,你也可以使用扫描数据库的方法作为补偿机制。
- 消息不存在重复消费问题:每个客户端都是从同一个目标队列中获取任务的,不存在重复消费的问题。
跟 Redisson 内置的延时队列相比,消息队列可以通过保障消息消费的可靠性、控制消息生产者和消费者的数量等手段来实现更高的吞吐量和更强的可靠性,实际项目中首选使用消息队列的延时消息这种方案。
积分排行 ★★★
相关的一些 Redis 命令:
zrange:返回有序集中,指定区间内的成员(从小到大排序)、zrevrange:返回有序集中,指定区间内的成员(从大到小排序)、zrevrank(指定元素排名)、zrangebyscore:返回有序集合中,指定分数区间的成员列表。
场景示例如下:
- 场景一:用户得分越高,排行越前面。
- 场景二:用户游戏中花费的时间最短,排行越前面。
这种场景适合使用 sort set,使用的命令和基本操作如下:
添加用户和对应得分:
客户端命令:
ZADD key score member [[score member] [score member] ...]Python 代码:
redis_cli.zadd("key", {"mem1": 10, "mem2": 6, "mem3": 7})将一个或多个 member 元素及其 score 值加入到有序集 key 中。score 值可以是整数值或双精度浮点数。
如果某个 member 已经是有序集的成员,那么更新这个 member 的 score 值,并通过重新插入这个 member 元素,来保证该 member 在正确的位置上。
当 key 不存在,则创建一个空的有序集并执行 ZADD 操作。
当 key 存在但不是有序集类型时,返回一个错误。
返回有序集 key 中成员 member 的排名,命令:
zrevrank key member。其中有序集成员按 score 值递减(从大到小)排序。排名以 0 为底,也就是说,score 值最大的成员排名为 0。
返回有序集 key 中,成员 member 的 score 值,命令:
ZSCORE key member如果 member 元素不是有序集 key 的成员,或 key 不存在,返回 nil 。
获取排名前几的成员,命令
zrange:1
2
3
4
5
6zrange(name, start, end, desc=False, withscores=False, score_cast_func=float)
# start:起始位置,可从0开始;
# end:结束位置,为-1时可以取到结尾位置;
# desc:排序规则,默认按照score从小到大排序;
# withscores:是否获取元素的分数,默认只获取元素的值;
# score_cast_func:对分数进行数据转换的函数;
如何处理以上两个场景中用户分数相同的情况呢,比如两个用户 score 相同,Redis 如何排序呢。
在 score 相同的情况下,Redis ,会按照 key 的字典顺序排序,而所谓的字典排序其实就是 “ABCDEFG”、”123456…” 这样的排序,在首字母相同的情况下,Redis 会再比较后面的字母,还是按照字典排序。
有如下场景怎么办呢:用户得分越高,排行越前面,如果分数相同情况下,先达成该分数的用户排前面。
我们可以把用户完成游戏的时间戳也加入到 score 值的构成中。我们会想到 分数+''+时间戳。
但是 分数+''+时间戳 是不行的,因为分数越大越靠前,而时间戳越小则越靠前,这样两部分的判断规则是相反的,无法简单把两者合成一起成为用户的 score。
我们可以逆向思维,可以用同一个足够大的数 MAX 减去时间戳,时间戳越小,则得到的差值越大,这样我们就可以把 score 的结构改为:分数+''+(MAX-时间戳),这样就能满足我们的需求了。
Redis 最适合的场景
Redis 最适合所有数据 in-momory 的场景,虽然 Redis 也提供持久化功能,但实际更多的是一个 disk-backed 的功能,跟传统意义上的持久化有比较大的差别。可能大家就会有疑问,似乎 Redis 更像一个加强版的 Memcached,那么何时使用 Memcached,何时使用 Redis 呢?
会话缓存(Session Cache),Redis 最常用的一种使用情景。
用 Redis 缓存会话比其他存储(如Memcached)的优势在于:Redis 提供持久化。
当维护一个不是严格要求一致性的缓存时,如果用户的购物车信息全部丢失,大部分人都会不高兴的,当有持久化,他们还会这样吗?
幸运的是,随着 Redis 这些年的改进,很容易找到怎么恰当的使用 Redis 来缓存会话的文档。甚至广为人知的商业平台 Magento 也提供 Redis 的插件。全页缓存(FPC)。
除基本的会话 token 之外,Redis 还提供很简便的FPC平台。
回到一致性问题,即使重启了 Redis 实例,因为有磁盘的持久化,用户也不会看到页面加载速度的下降,这是一个极大改进,类似 PHP 本地 FPC。
再次以 Magento 为例,Magento 提供一个插件来使用 Redis 作为全页缓存后端。此外,对 WordPress 的用户来说,Pantheon 有一个非常好的插件 wp-redis,这个插件能帮助你以最快速度加载你曾浏览过的页面。队列。
Reids 在内存存储引擎领域的一大优点是提供 list 和 set 操作,这使得 Redis 能作为一个很好的消息队列平台来使用。
Redis 作为队列使用的操作,就类似于本地程序语言(如Python)对 list 的 push/pop 操作。
例如,Celery 有一个后台就是使用 Redis 作为 broker。排行榜/计数器。
Redis 在内存中对数字进行递增或递减的操作实现的非常好。
集合(Set)和有序集合(Sorted Set)也使得我们在执行这些操作的时候变的非常简单,Redis 只是正好提供了这两种数据结构。
所以,我们要从排序集合中获取到排名最靠前的10个用户,只需要执行:ZRANGE user_scores 0 10 WITHSCORES
当然,这是假定你是根据你用户的分数做递增的排序。如果你想返回用户及用户的分数,你需要这样执行:ZSCORE user_scores user_name
Agora Games 是用 Ruby 实现的,它的排行榜就是使用 Redis 来存储数据的。发布/订阅。
最后(但肯定不是最不重要的)是 Redis 的发布/订阅功能。发布/订阅的使用场景确实非常多。
我已看见人们在社交网络连接中使用,还可作为基于发布/订阅的脚本触发器,甚至用 Redis 的发布/订阅功能来建立聊天系统!(不,这是真的,你可以去核实)。
Redis 提供的所有特性中,我感觉这个是喜欢的人最少的一个,虽然它为用户提供如果此多功能。
如何实现集群中的 session 共享存储
如果项目是单台服务器部署,那么 Session 通常也运行在这台服务器上的,所有的访问也都会到这台服务器上,我们可以根据客户端传来的 sessionID,来获取 session,或在对应 Session 不存在的情况下(session 生命周期到了/用户第一次登录),创建一个新的 Session。
但是,如果我们在集群环境下,假设我们有两台服务器 A、B,用户的请求会由 Nginx 服务器进行转发(别的方案也是同理),用户登录时,Nginx 将请求转发至服务器 A 上,A 创建了新的 session,并将 SessionID 返回给客户端,用户在浏览其他页面时,客户端验证登录状态,Nginx 将请求转发至服务器 B,由于 B 上并没有对应客户端发来 sessionId 的 session,所以会重新创建一个新的 session,并且再将这个新的 sessionID 返回给客户端,这样,我们可以想象一下,用户每一次操作都有 1/2 的概率进行再次的登录,这样不仅对用户体验特别差,还会让服务器上的 session 激增,加大服务器的运行压力。为了解决集群环境下的 seesion 共享问题,共有 4 种解决方案:
- 粘性 session:粘性 session 是指 Ngnix 每次都将同一用户的所有请求转发至同一台服务器上,即将用户与服务器绑定。
- session 复制:每当 session 发生变化时(如创建或者修改),就广播给集群中所有的服务器,使所有的服务器上的 session 相同。
- session 共享:缓存 session,使用 redis,memcached。
- session 持久化:将 session 存储至数据库中,像操作数据一样操作 session。
使用 Set 实现抽奖系统怎么做?
如果想要使用 Set 实现一个简单的抽奖系统的话,直接使用下面这几个命令就可以了:
SADD key member1 member2 ...:向指定集合添加一个或多个元素。SPOP key count:随机移除并获取指定集合中一个或多个元素,适合不允许重复中奖的场景。SRANDMEMBER key count:随机获取指定集合中指定数量的元素,适合允许重复中奖的场景。
使用 Bitmap 统计活跃用户怎么做?
Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身。我们知道 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间。
你可以将 Bitmap 看作是一个存储二进制数字(0 和 1)的数组,数组中每个元素的下标叫做 offset(偏移量)。
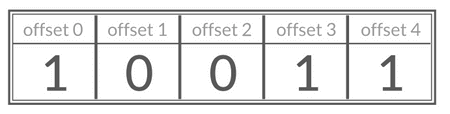
如果想要使用 Bitmap 统计活跃用户的话,可以使用日期(精确到天)作为 key,然后用户 ID 为 offset,如果当日活跃过就设置为 1。
初始化数据:
1 | |
统计 20210308~20210309 总活跃用户数:
1 | |
统计 20210308~20210309 在线活跃用户数:
1 | |
使用 HyperLogLog 统计页面 UV 怎么做?
使用 HyperLogLog 统计页面 UV 主要需要用到下面这两个命令:
PFADD key element1 element2 ...:添加一个或多个元素到 HyperLogLog 中。PFCOUNT key1 key2:获取一个或者多个 HyperLogLog 的唯一计数。
1、将访问指定页面的每个用户 ID 添加到 HyperLogLog 中。
1 | |
2、统计指定页面的 UV。
1 | |