03-Kafka 与 zookeeper
Kafka 和 Zookeeper 之间的关系
Zookeeper 是一个开放源码的、高性能的协调服务,它用于 Kafka 的分布式应用。Zookeeper 主要用于在集群中不同节点之间进行通信。在 Kafka 中,它被用于提交偏移量,因此如果节点在任何情况下都失败了,它都可以从之前提交的偏移量中获取。除此之外,它还执行其他活动,如:Leader 检测、分布式同步、配置管理、识别新节点何时离开或连接、集群、节点实时状态等等。
如果没有 Zookeeper,Kafka 也需要自己维护一套机制存储元数据和交换集群信息的工具,不如直接用 Zookeeper。
Zookeeper 主要为 Kafka 做了下面这些事情:
Broker 注册:在 Zookeeper 上会有一个专门用来进行 Broker 服务器列表记录的节点,节点路径为
/brokers/ids。每个 Broker 在启动时,都会到 Zookeeper 上进行注册,即到/brokers/ids下创建属于自己的节点。即创建/brokers/ids/[0-N]的节点,然后写入 IP,端口等信息,Broker 创建的是临时节点,所以一旦 Broker 上线或者下线,对应 Broker 节点也就被删除了,因此可以通过 Zookeeper 上 Broker 节点的变化来动态表征 Broker 服务器的可用性。Topic 注册:在 Kafka 中,同一个Topic 的消息会被分成多个分区并将其分布在多个 Broker 上,这些分区信息及与 Broker 的对应关系也都是由 Zookeeper 在维护。比如我创建了一个名字为 my-topic 的主题并且它有两个分区,对应到 zookeeper 中会创建这些文件夹:
/brokers/topics/my-topic/Partitions/0、/brokers/topics/my-topic/Partitions/1负载均衡:上面也说过了 Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition 可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力。 对于同一个 Topic 的不同 Partition,Kafka 会尽力将这些 Partition 分布到不同的 Broker 服务器上。当生产者产生消息后也会尽量投递到不同 Broker 的 Partition 里面。当 Consumer 消费的时候,Zookeeper 可以根据当前的 Partition 数量以及 Consumer 数量来实现动态负载均衡。
……
早期版本的 Kafka 用 Zookeeper 做 meta 信息存储、Consumer 的消费状态、group 的管理以及 offset 的值。
考虑到 Zookeeper 本身的一些因素以及整个架构较大概率存在单点问题,新版本中逐渐弱化了 Zookeeper 的作用。新的 consumer 使用了 Kafka 内部的 group coordination 协议,也减少了对 Zookeeper 的依赖,但是 Broker 依然依赖于 Zookeeper,Zookeeper 在 Kafka 中还用来选举 controller 和检测 Broker 是否存活等。
使用 Kafka 能否不引入 Zookeeper?
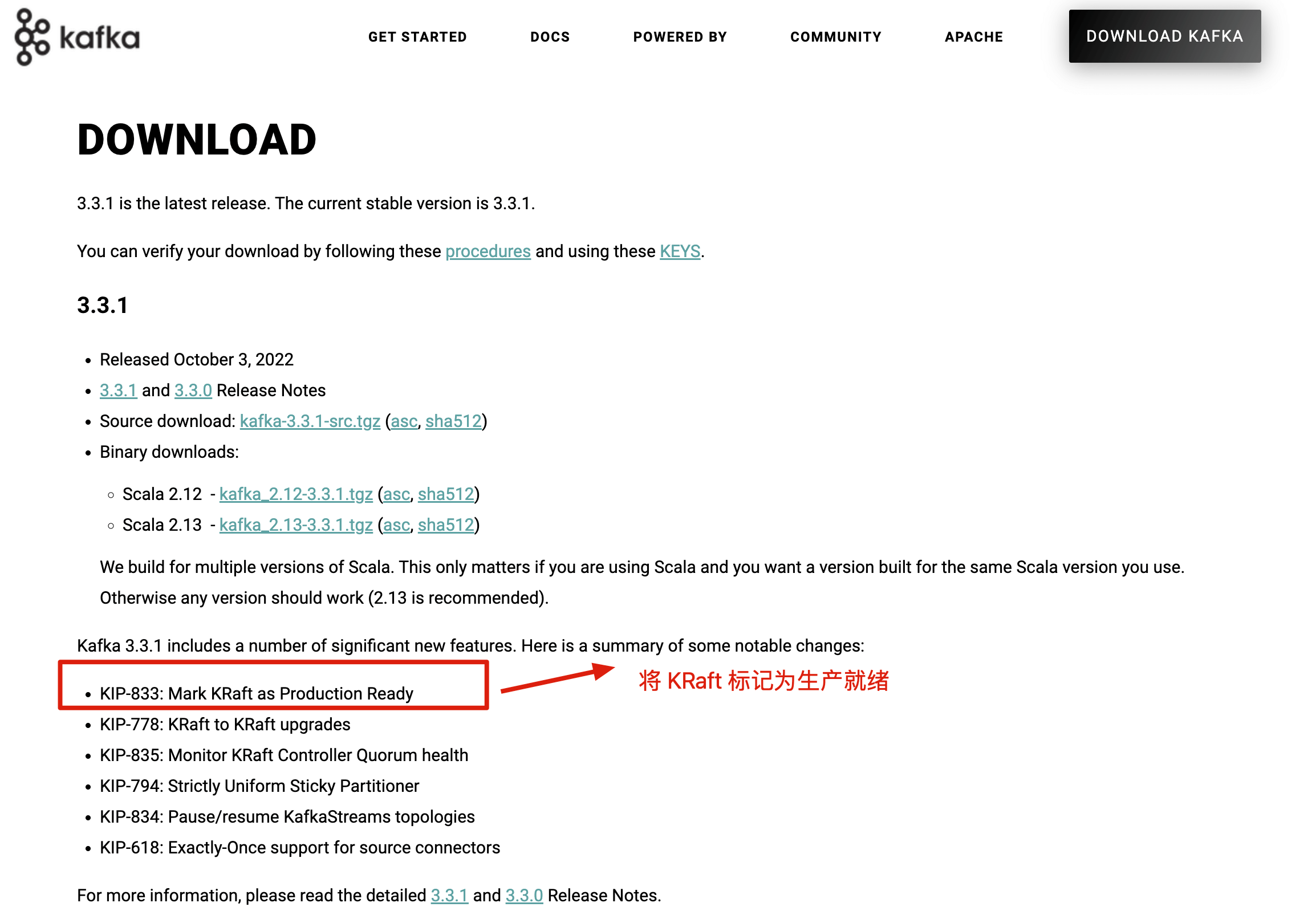
在 Kafka 2.8 之前,Kafka 最被大家诟病的就是其重度依赖于 Zookeeper。在 Kafka 2.8 之后,引入了基于 Raft 协议的 KRaft 模式,不再依赖 Zookeeper,大大简化了 Kafka 的架构,让你可以以一种轻量级的方式来使用 Kafka。
不过,要提示一下:如果要使用 KRaft 模式的话,建议选择较高版本的 Kafka,因为这个功能还在持续完善优化中。Kafka 3.3.1 版本是第一个将 KRaft(Kafka Raft)共识协议标记为生产就绪的版本。