深度学习常见数据集之PASCAL VOC
背景
PASCAL 的全称是 Pattern Analysis, Statistical Modelling and Computational Learning。
VOC 的全称是 Visual Object Classes。
第一届 PASCAL VOC 举办于2005年,然后每年一届,于2012年终止。
本文以PASCAL VOC 2012为基础。
数据标注方式
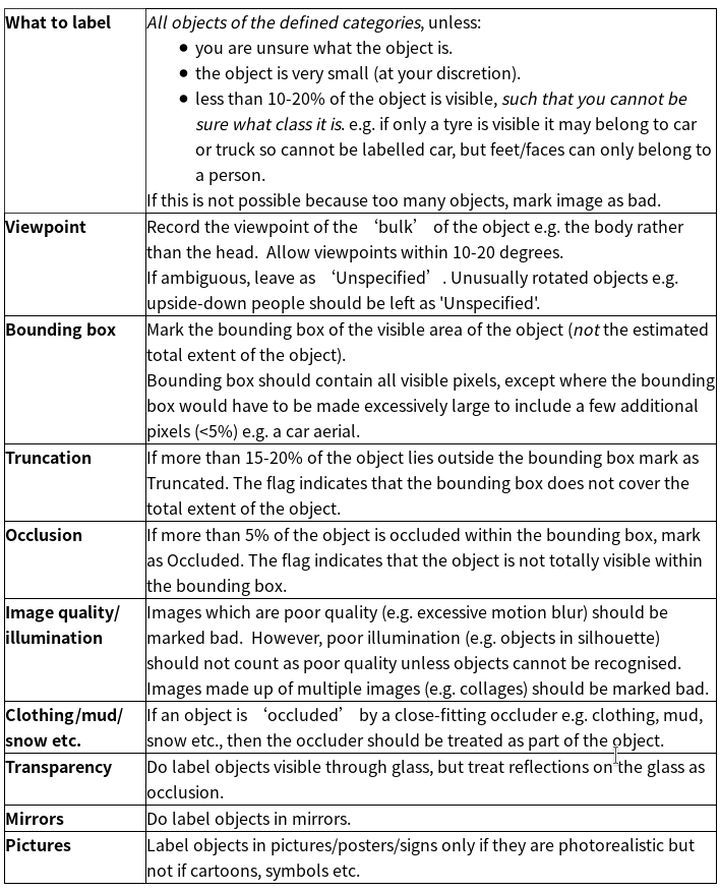
数据集简介
PASCAL VOC竞赛目标主要是目标识别,其提供的数据集里包含了20类的物体。
- person
- bird, cat, cow, dog, horse, sheep
- aeroplane, bicycle, boat, bus, car, motorbike, train
- bottle, chair, dining table, potted plant, sofa, tv/monitor
PASCAL VOC的主要2个任务是(按照其官方网站所述,实际上是5个):
- 分类: 对于每一个分类,判断该分类是否在测试照片上存在(共20类);
- 检测:检测目标对象在待测试图片中的位置并给出矩形框坐标(bounding box);
- Segmentation: 对于待测照片中的任何一个像素,判断哪一个分类包含该像素(如果20个分类没有一个包含该像素,那么该像素属于背景);
- (在给定矩形框位置的情况下)人体动作识别;
- Large Scale Recognition(由ImageNet主办)。
另外,PASCAL VOC利用其训练集的一个子集对外提供2个尝鲜性质的任务:
- (无给定矩形框位置的情况下)人体动作识别;
- Person Layout: 对于待测照片中的每一个人,预测出这个人的bounding box,以及这个人的头、手、脚的bounding box。
XML标注格式
对于目标检测来说,每一张图片对应一个xml格式的标注文件。所以你会猜到,就像gemfield准备的训练集有8万张照片一样,在存放xml文件的目录里,这里也将会有8万个xml文件。下面是其中一个xml文件的示例:
1 | |
在这个测试图片上,我们标注了2个object,一个是gemfield,另一个是civilnet。
在这个xml例子中:
- bndbox是一个轴对齐的矩形,它框住的是目标在照片中的可见部分;
- truncated表明这个目标因为各种原因没有被框完整(被截断了),比如说一辆车有一部分在画面外;
occluded是说一个目标的重要部分被遮挡了(不管是被背景的什么东西,还是被另一个待检测目标遮挡); - difficult表明这个待检测目标很难识别,有可能是虽然视觉上很清楚,但是没有上下文的话还是很难确认它属于哪个分类;标为difficult的目标在测试成绩的评估中一般会被忽略。
注意:在一个<object/>中,<name/> 标签要放在前面,否则的话,目标检测的一个重要工程实现SSD会出现解析数据集错误(另一个重要工程实现py-faster-rcnn则不会)。
如何评判目标检测的成绩?
先来介绍几个概念
1,IoU
这是关于一个具体预测的Bounding box的准确性评估的数据。对于目标检测任务来说,一个具体的目标预测包括一个bounding box的坐标和它的置信度。通过测量预测的bndbox(bounding box)和ground truth的bndbox之间的重合度,我们来得出此次预测是true positive还是false positive。

一般来说,重合区域的面积(上面公式的分子)和2个bndbox的面积之和的比例(上面公式的分母)如果大于50%,那么认为这是一个成功的预测(true positive),否则认为这是一个失败的预测(false positive)。公式等号的左边就是IoU。50%这个数值的选取是考虑了一些因素的,比方说人有胳膊有腿,有蜷缩有伸展的状态,因此这个数也不能太严格。
如果对于一个目标算法检测出多个目标,比如一个目标上算法给出了5个检测框,那么就算4个检测错误。
2,mAP
对于一个给定的任务和分类:
precision/recall曲线是根据算法的输出计算得到的。
Recall(召回率)说的是所有正样本中被算法预测出来的样本所占的比率;
(Recall is defined as the proportion of all positive examples ranked above a given rank.)
Precision(准确率)说的是预测出来的样本中是正确的比例是多少;
(Precision is the proportion of all examples above that rank which are from the positive class. )
AP的值就某种程度上反映了上述PR曲线(precision/recall)的形状,我们把recall的值从0到1 (0%到100%)划分为11份:0、0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9、1.0,在每个recall尺度上我们计算下准确率,然后再计算总和并平均,就是AP值。

因此,一个表现良好的算法应该是在各个recall层面上都有足够好的Precision。
对于给定的任务的所有的分类:
计算每个分类的AP,求和再平均,得到的就是mAP。
PASCAL VOC数据集实例
以 VOC 2007 为例,解压后的文件为:
1
2
3
4
5
6
7
8
9
10
11
12
13
shell
.
├── Annotations 进行 detection 任务时的标签文件,xml 形式,文件名与图片名一一对应
├── ImageSets 包含三个子文件夹 Layout、Main、Segmentation,其中 Main 存放的是分类和检测的数据集分割文件
├── JPEGImages 存放 .jpg 格式的图片文件
├── SegmentationClass 存放按照 class 分割的图片
└── SegmentationObject 存放按照 object 分割的图片
├── Main
│ ├── train.txt 写着用于训练的图片名称,共 2501 个
│ ├── val.txt 写着用于验证的图片名称,共 2510 个
│ ├── trainval.txt train与val的合集。共 5011 个
│ ├── test.txt 写着用于测试的图片名称,共 4952 个
建立自己的数据集
本节仅以目标检测为例,建立一个名为VOC2018的数据集。如下所示:
1 | |
可以看到,必备的目录只有Annotations、JPEGImages以及ImageSets/Main。
1,把所有的照片放入到JPEGImages目录:
1 | |
2,把所有的xml标注文件放入到Annotations目录:
1 | |
3,把划分好的训练集测试集放入到 ImageSets/Main目录下:
1 | |
以val.txt文件为例,格式如下(这几个文件格式一样):
1 | |
VOC 常用组合、数据量统计及组织结构
VOC2007 train_val_test & VOC2012 train_val 百度云下载链接,提取码: jz27
目前目标检测常用的是 VOC2007 和 VOC2012 数据集,因为二者是互斥的,论文中的常用组合有以下几种:
07+12:使用 VOC2007 和 VOC2012 的train+val(16551)上训练,然后使用 VOC2007 的 test(4952) 测试07++12:使用 VOC2007 的train+val+test(9963)和 VOC2012的train+val(11540)训练,然后使用 VOC2012 的 test 测试,这种方法需提交到 PASCAL VOC Evaluation Server 上评估结果,因为 VOC2012 test 没有公布07+12+COCO:先在 MS COCO 的 trainval 上 预训练,再使用 VOC2007 和 VOC2012 的train+val微调训练,然后使用 VOC2007 的 test 测试07++12+COCO:先在 MS COCO 的 trainval 上预训练,再使用 VOC2007 的train+val+test和 VOC2012 的train+val微调训练,然后使用 VOC2012 的 test 测试 ,这种方法需提交到 PASCAL VOC Evaluation Server上评估结果,因为VOC2012 test 没有公布
VOC2007 和 VOC2012 目标检测任务中的训练、验证和测试数据统计如下表所示,具体每一类的数据分布见 PASCAL VOC2007 Database Statistics 和 PASCAL VOC2012 Database Statistics

提交格式
1、Classification Task
- 每一类都有一个 txt 文件,里面每一行都是测试集中的一张图片,前面一列是图片名称,后面一列是预测的分数。
1 | |
2、Detection Task
- 每一类都有一个 txt 文件,里面每一行都是测试集中的一张图片,每行的格式为:
<image identifier> <confidence> <left> <top> <right> <bottom>,confidence 用来计算mAP
1 | |
评估标准
- PASCAL的评估标准是 mAP(mean average precision),关于 mAP 可参考以下资料:
- average precision
- 性能指标(模型评估)之mAP
- 多标签图像分类任务的评价方法-mAP
- 周志华老师 《机器学习》 模型评估标准一节
- PASCAL官方给了 MATLAB 版的 mAP 评估脚本和示例代码 development kit code and documentation
- eg:下面是一个二分类的 P-R 曲线(
precision-recall curve),对于 PASCAL 来说,每一类都有一个这样的 P-R曲线,P-R 曲线下面与 x 轴围成的面积称为average precision,每个类别都有一个 AP,**20个类别的 AP 取平均值** 就是 mAP。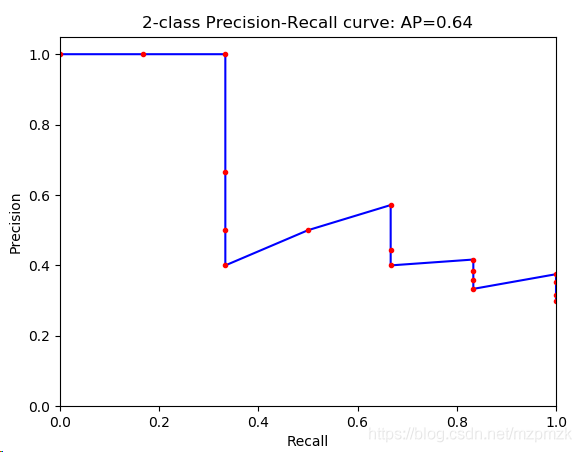
参考资料
1、The PASCAL Visual Object Classes Homepage
2、目标检测数据集PASCAL VOC简介